Well, I wasn't expecting to release a new version of BlogMore quite so soon, given I made a release earlier today. But an issue came in that the Bluesky icon wasn't showing in the socials section on someone's blog, despite the fact that the docs suggested it should work.
It's interesting to note that Copilot/Claude (which is what did this work originally) produced one thing in the code, and then made an unsupportable claim in the documentation. Furthermore, it didn't construct the tests to at least match the documentation's claims. None of this is a surprise, of course, but it is a good illustration of the fact that agent-based coding is just fancy auto-complete with no real ability to maintain a coherent view of the whole project.
Anyway, v2.35.0 is now available and I too can have a Bluesky link in my socials. Oddly, I hadn't thought to add it before now.
I've just realised that, somehow, I've managed to post something on this blog, every single day this month.
A large part of this is, of course, because I've been doing a lot of stuff on BlogMore, but there's no getting away from the fact that BlogMore exists and I feel compelled to make use of it, and also that blogmore.el helps make it a lot easier to kick off and edit a post.
Thinking back to other blogs I've maintained over the past couple of decades, I don't think I've ever come close to this. Last month did come close, broken only by the couple of days I was chilling in Whitby. The month before also came close, minus 2 days where I just didn't have something to write.
I don't imagine this will last; in fact, I know for sure that there will be fewer posts next month (I have a trip coming up). What I do know is that I feel more compelled to jot something down when an idea turns up, and I'm enjoying the habit of blogging more frequently. While I expect this run to calm down, I hope I don't fall back to leaving it months at a time before opening a fresh Emacs buffer and kicking off some new Markdown.
The first change is a small fix to the url_path property, which wasn't being populated; now it is.
The second change adds two new properties to the output which relate to links that can be found inside posts: internal_links and external_links. As the names suggest, the first gives you a list of all the internal links that can be found in a given post, with the values given being the same format as the id used for every post in the dump. For example:
There is, of course, some overlap with the link dumping command, but given that the information is available it seemed to make sense to provide it here; it also means that it's available in a more structured form.
Also providing this sort of information in the JSON output means there's a lot of flexibility when it comes to analysing all the posts in my blog. For example, I can now easily satisfy my curiosity if I want to know exactly which posts in my blog have no links whatsoever.
Since kicking off the work on BlogMore and blogmore.el, I've absolutely found that I've reduced the friction involved when it comes to writing a quick (or not so quick) blog post. I've also found that I want to go back and tidy up lots of my old posts. Over the past few weeks I've gone and cleaned up the size and positioning of images; converted most images to WebP format; cleaned and consolidated the tags used; hunted down and fixed broken internal links; and a few other things besides.
Another thing I want to do is go back and hunt down, and clean up, typos and spelling mistakes, and the like. While I'm careful to try and not make any errors when typing out a post, and while I've always made a point of reading my posts back to try and catch problems, I've not always been successful. Sometimes I'm just blind to the errors, sometimes I'm just rushing. There's over a decade of mistakes on this blog.
This alone makes it nice and easy to go back and clean up some obvious issues. A problem I ran into though was that I was getting a lot of false reports for things in the front matter of the files (especially parts of the cover: file name) and also in the end-of-file comments I like to use. So, with a little help from Gemini (because it's a moment since I last wrote any awk in anger), I wrote a filter to "clean" the Markdown content before running it through aspell.
Already, using this setup, I've caught a few things that deserved cleaning up, and because there will be a lot of words that are correct but particular to this blog and what I write about, I'm also building up a local ignore list.
While this setup isn't going to make the content of this blog error-free, it should give me everything I need to go back and slowly improve some of the older text, and to harmonise some of the spellings of some technical terms.
I've released v2.33.0 of BlogMore, which extends the stats page some more, and also adds a tool so a user can do all sorts of fun things with the raw data of their posts.
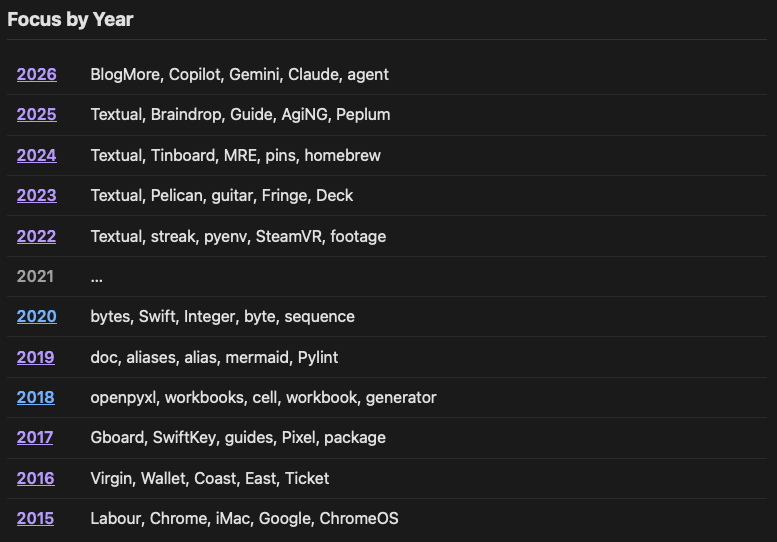
The addition to the stats page is a list of years along with the top five words that characterise the focused subject for those years. This is done using TF-IDF. While the results for my blog don't come as a surprise, I am pleased to see that it does turn out pretty much how I would have expected:
This feels like another fun way to learn something about the post history for your own blog.
Which got me thinking: there's probably any number of other niche and bizarre things that could be done with the content of a blog to gain some insight as to its history, and I really shouldn't just keep adding more and more things to the stats page. But what if I wanted a way to run some code over all the posts? Wouldn't it be useful if I could get all of the parsed post data in JSON format so I can play with it?
With that idea in mind, I added the dump command. When run, it will print to stdout a full dump of all of your posts, as JSON, so you can then write your own nifty tool to read it back in and do any number of interesting checks, tests, reformats or manipulations. For example, if I wanted to use jq to pull out the metadata for this particular post I could:
I can see this being pretty useful to blogmore.el at some point, if I want to add some better querying tools or similar (not that I'd want to run a dump every time, it does require that a full parse and render has to happen).
Hopefully this will be useful to someone else. I know I'll be toying with it to find out other things about my posting history.
Now that BlogMore is so obviously feature-complete and there's nothing else I could possibly need to add to it... here's v2.32.0 with a quick new feature.
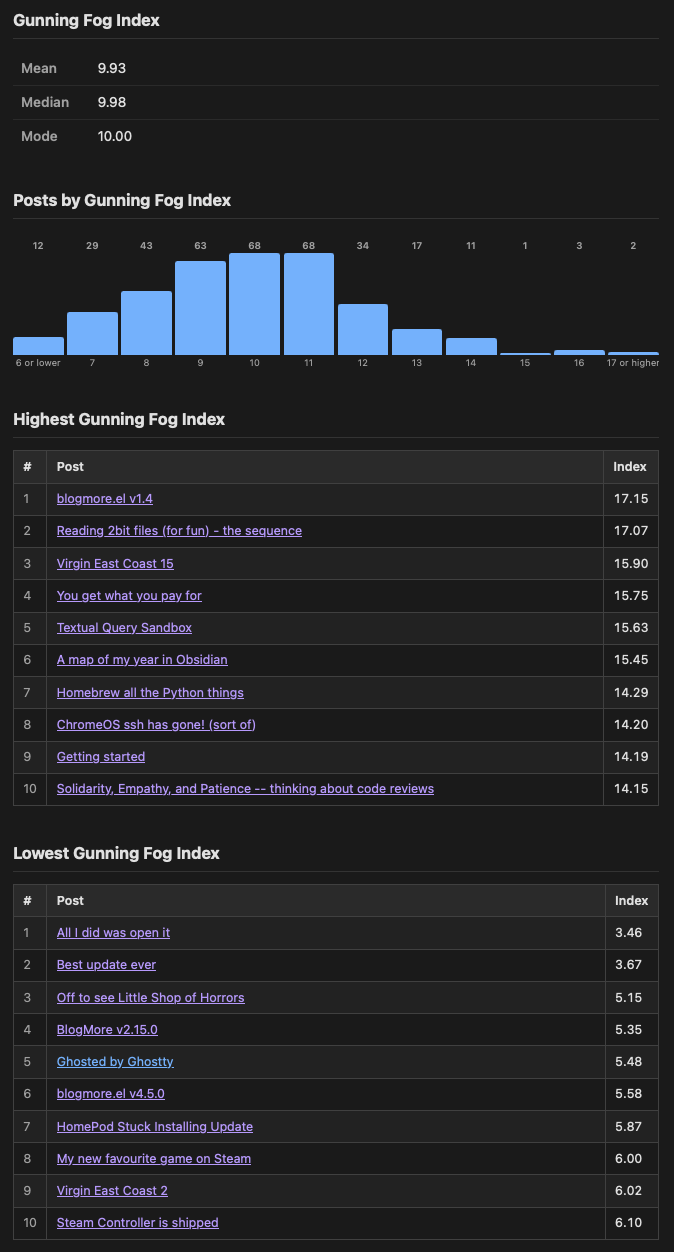
The work to add the relatedness of posts got me wondering about other things that could be measured about the content of posts, and a bit of reading and looking for ideas resulted in my (re)discovering the Gunning fog index. That got me thinking it might be interesting to see what the highest and lowest values were for my blog, and perhaps what the average is, perhaps even get a feel for the distribution.
So now BlogMore has a with_gfi configuration setting (and a matching command line switch). When enabled, it adds the score for a post next to the reading time (if that's enabled, if not it's in the same location as the reading time would be). It also adds a load of stats to the stats page.
As well as this change, I've also tweaked the stats page so it's easier to get a link to a particular section. As with headings in posts, when you hover over a section heading you'll get a little anchor you can click on that will result in you visiting that particular heading. That should make it easier to highlight a particular statistic, if you need to.
A quick update to BlogMore, with a small accessibility improvement, and also a whole new set of data for the graph.
The accessibility update follows on from a change published yesterday. In that release I did a little bit of work to disambiguate links to categories and tags that had the same link text; this time I've given the same aria-label treatment to the post dates where they link to the year, month, and day archives. While we're never really going to get ambiguous year links (unless there are also links in the body of a post that are four digit numbers), it's highly likely we're going to get the occasional month and day that are ambiguous.
So now those links make it clear, with aria-label, what's being linked to.
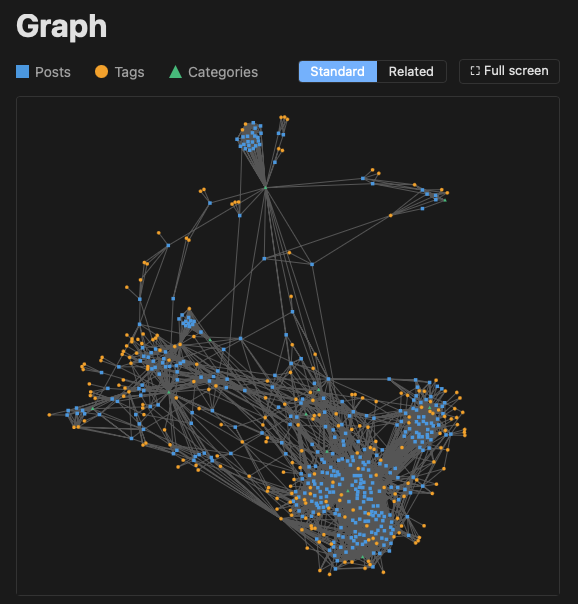
The other main change in v2.31.0 comes from a thought I had last night about the new "related posts" feature I added yesterday. Currently the graph shows the relationships the posts have based around their common categories and tags:
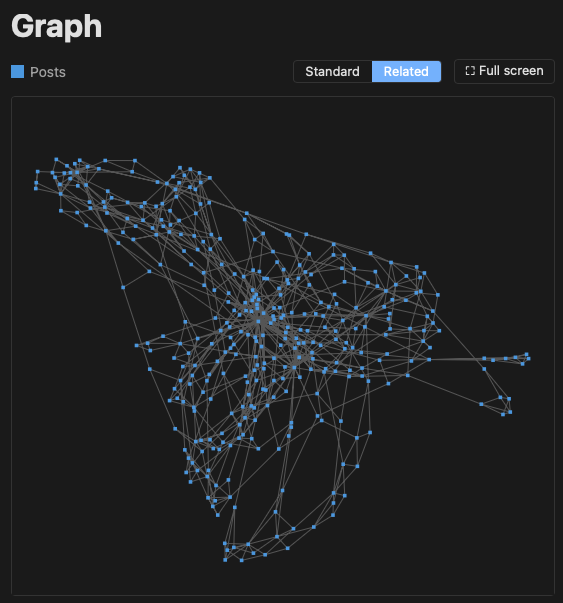
But now I've got this code that can work out how posts might be related based on their text content. What might that look like? It might be cool to be able to switch the graph view between the two sets of data, if the blog owner is building with related posts turned on.
While I'm not sure it really tells me anything, I like that I have yet another method of (re)discovering posts.
BlogMore has been bumped to v2.30.0. This release is pretty heavy on new features, but it does also include one small accessibility tweak too. While looking through some of the neutral feedback from PageSpeed Insights I noticed it mentioned that in some cases I had a category and a tag linked on the same page, where the text of the link was the same. That's pretty common on my blog. For many of the categories (especially things like AI, Coding, Emacs, Python, etc.) I'll also have a corresponding tag. The idea is that categories are essentially sub-blogs within the blog, whereas tags characterise a post.
Given that the same text for different purposes doesn't give much context from an accessibility point of view I've added appropriate aria-label attributes to differentiate these links.
Now for the new features.
The first is another "discover other posts" type feature, that might encourage a reader to venture further into a blog. While BlogMore does support backlinks (as was added back in v2.16.0), I have been thinking that a "related posts" feature would be interesting to add. So now it's added. This is enabled with the with_related configuration option (or the --with-related command line switch) and provides control over how many related posts are shown; the default is three.
The rest of the new features are more admin-based and are all commands on the BlogMore command line. The first is the drafts command which simply lists the filename of all the posts that are in a draft state.
The second new command is links
dump. This is a utility command for dumping a CSV list of all the external links that can be found in your posts, along with the filename of the post the link was found in. This could be useful for all sorts of things; for example writing your own external link statistics tool, or perhaps writing your own external link checker.
Talking of external link checkers: I've also added links
check. This is a bit experimental, but is intended to be a simple checker of all the external links, seeing if they're still out there. By default, when run, it'll check every link it finds and, if there's a problem with it, it'll report the issue. There's a --verbose mode as well if you want feedback on all the links that are working.
It seems like every time I think I'm done adding features, something else is either suggested or pops into my head. I feel like I'm near the end of adding stuff now and should be getting back to refining the code.
Despite the fact that I am not, in any way, superstitious, I kind of have this rule: don't make definitive statements about the absolute happening of an event until it happens; it kind of feels like you're tempting the universe to prank you. I don't always follow it, I know it's kind of silly, but it's there and hard to shake. It's normal. It's human.
Sometimes it happens that it looks like I should stick to that rule.
Eleven days back I wrote about how I was aiming to return to streaming thanks to the fact that I'd once again be the proud owner of a full fibre connection. The thing that, in part, prompted me to write about that was the fact that I'd had an email, that morning, from Openreach, to let me know they'd done some work and that fibre was now available at my property.
The email proudly stated:
Hello Dave,
Congratulations, you can now get Full Fibre on the Openreach network at [my home address].
With Full Fibre broadband, you can choose your package based on the download speeds you'll need from 40 Mbps to 1.6 Gbps. Need some help choosing? Then read our blog before ordering to find out what's a good download speed.
We also have the UK's biggest choice of broadband providers, so you can find a package and price to suit you.
After a button that linked to a site for finding a provider, it went on to say:
After you've placed your order with the provider of your choice, we'll arrange a day and time with you for one of our engineers to connect Full Fibre to your property if it isn't there already.
They may need to drill a small hole in your wall, or they may be able to use the same access point as your current line. Either way, they'll take care of everything and leave you with a broadband that's ready to deal with anything the future brings. You can find out more about what's involved in our handy Full Fibre installation video.
I found this whole email mildly amusing because it was obvious that the work they'd done, that made this possible, will have been the result of the call I made to EE back in March to order fibre in the first place, when it became apparent I was finally able to request it.
So, yeah, when Openreach -- the people who do the cables and stuff -- email you to let you know they've as good as hooked your place up, you know it's a safe bet.
Today was the day. This morning, between 08:00 and 13:00, was the window I'd been given for one of their engineers to turn up and do the hole drilling and the box screwing and all the stuff and then this evening I'd be in a position where, once again, I could download the whole Internet and stream utter nonsense in the highest quality (both creating and consuming). I was looking forward to this.
Everyone in the house was.
The time window started, and kept going, and kept going, and eventually it was 13:00 and nobody had turned up and my house had no extra wires or holes and I was on the phone to EE to ask WHERE IS THE GLASS INTERNET PIPE?!?
Long story short: it wasn't turning up. At all. It appears, at some point in the recent past, Openreach simply cancelled the order and nobody thought to tell me. Openreach (the people who sent me the email 11 days ago) didn't think to tell me. That's the same Openreach who sent me the SMS on the 7th of this month to give me the date of the work; apparently they could not send me an SMS to let me know they'd decided against this.
Of course, it's not all on Openreach. It would also seem that EE knew, from their own system, that the order had been cancelled and they too had failed to email me, message me, call me, something, to let me know I'd be wasting my time clearing half my day to receive them and have the work take place.
So: pretty shitty service all round.
The main explanation I've been given is something to do with a "CBT"1, or something related. This means that it's just not possible to deliver fibre to my address. This is after:
I called to check in March
I was told in March it was possible
Openreach checked things out, said more work was needed, did the work
I literally saw them doing the work, with a trench and barriers and everything
I was emailed by Openreach after the work took place to say they'd done the work and I could have fibre
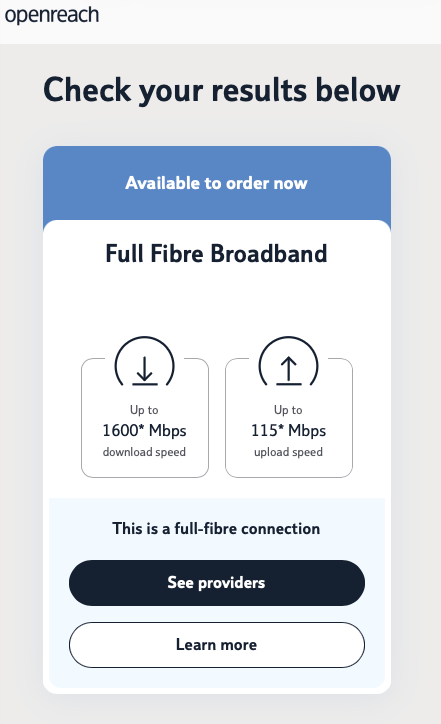
Even today, even right now, if I go on their site and put in my exact address:
Not "no". Not "eventually". Not "soon". Now. It says now.
At this point this is where I have to say, after making a bit of a mess of all of this, EE have done all they can to smooth things over (especially given there's sod all they can actually do about this). They've compensated me for the missed appointment (despite the fact it wasn't technically missed; it had been cancelled and nobody had let me know), left me to hang on to all the new equipment for if/when the fibre does turn up (meaning I'll have a backup router I guess), and have also compensated me for 3 months of my current copper-based broadband by way of an apology.
On top of that they didn't just brush me off with a "sorry, can't do anything about this", they went to bat for me during a 90 minute phone conversation, chasing up more detailed explanations of what the issue was with Openreach, as we talked. While I don't actually have a solution that is anything other than "you'll have to wait", at least now I have something of a better explanation as to what the actual problem is.
So where does this leave me? Here's what I do know:
The issue that stopped my installation is solvable and, in all likelihood, is the sort of thing that will be solved in the next few months (mention being made of a reasonable range of between a 2 to 6 month wait).
Almost every alternative provider I could go to would have the same issue, as they all work over the fibre that Openreach would install.
From what I can see no provider that isn't Openreach-connected is even the least bit interested in providing fibre.
Openreach have promised that the moment they have a solution to the technical problem that stops the installation, they will call me and arrange to kick things off again (or at least, I guess, let me know it's safe to place the order with EE again).
To be clear too: we're not talking about providing a service to a house in the middle of a field in the middle of nowhere, not even a house in some out-of-the-way village. I live in a reasonably large town, far bigger than the village I lived in before where I did have full fibre.
All of which concludes with: I started today excited by the prospect of fast downloads, fast uploads, and returning to talking nonsense on YouTube while being terrible at playing games; I'm finishing the day with no clear path to having fibre, and a wait time that could extend well into the rest of this year, and perhaps even into next.
I hope it won't be that bad, but I am deflated and disappointed.
Also, on the very remote chance that either Sharon or Neil from EE ever stumble on this blog post: thank you for all the effort you went to to get actual answers for me. It's a shame that it needs to be said, but it is rare these days that you call a customer support line at a service or utility company and get people who are willing and able to work in a way that isn't just following a script.
Well, except for the bit right at the end... I'm fine Neil, I don't need to swap mobile provider. ;-)
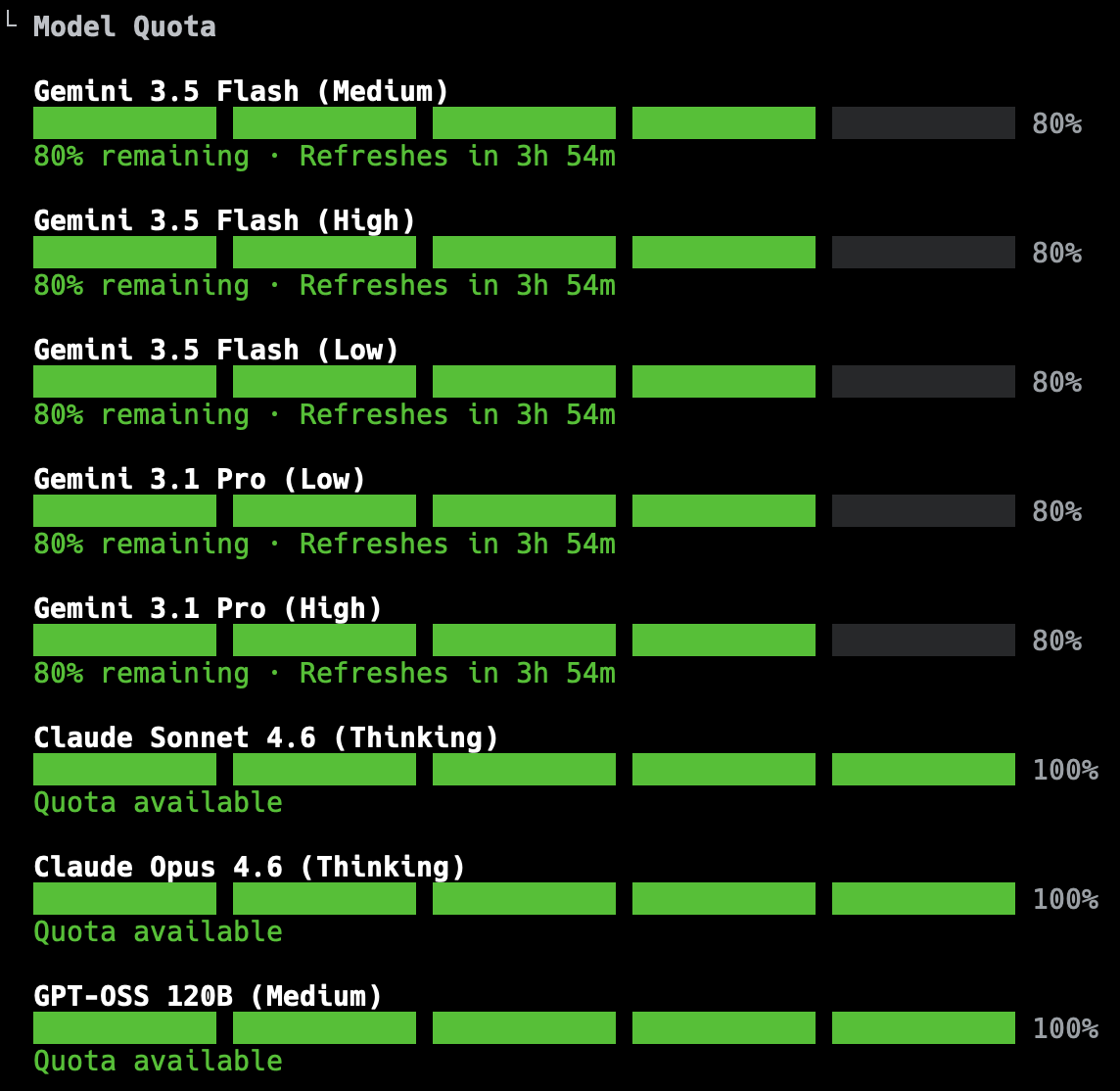
While it did appear something had changed for the better yesterday evening, things looked different again this morning. Before getting to work, I did a couple of quick changes to BlogMore; this time Antigravity seemed to use up a bit more quota in the same amount of time as I was working last night, but this time the reset window is much bigger.
I'm sure there's a method to this, but at the moment I'm really unclear what it is.
I guess I could ask it...
Yeah, let's do that.
Can you explain your quota cooldown time for me? Sometimes it seems to count down from 1 hour, others 5. Am I not reading this correctly?
You are reading the quota cooldown correctly! The reason the timer fluctuates between 1 hour, 5 hours, or other times is due to how the rolling usage window and compute-based limits work.
1. Rolling 5-Hour Window
Your usage limit is evaluated on a rolling window (typically 5 hours) rather than resetting at a fixed time of day.
If you see a 5-hour cooldown: You likely used a large portion of your compute capacity very recently. You have to wait for that recent window to clear.
If you see a 1-hour cooldown: You are close to the edge of your rolling window. A batch of high-compute requests you made 4 hours ago is about to fall out of the 5-hour window, which will free up capacity for you in 1 hour.
2. Compute-Based Usage (Not Message Count)
Your quota is consumed by compute rather than a flat number of messages. Compute is affected by:
Chat Length: Every time you send a new message, the model re-processes the entire chat history. Longer conversations consume your quota much faster.
Task Complexity: Tasks like code generation, deep thinking, or agentic workflows require more processing power and consume more quota.
Tips to Manage Your Quota:
Start New Chats: For new topics or tasks, start a fresh conversation. This prevents the model from having to re-read long histories and saves significant compute.
Use Clear, Targeted Prompts: Try to combine instructions rather than sending multiple short follow-up messages.
So, I don't think I'm any wiser after that. The explanation for the 1-hour countdown I saw last night has no connection to anything I did yesterday; I wasn't using Antigravity 4 hours earlier when I checked the quota near the end of that session. Guess I need to go and find and RTFM. Just like we used to in the good old days.