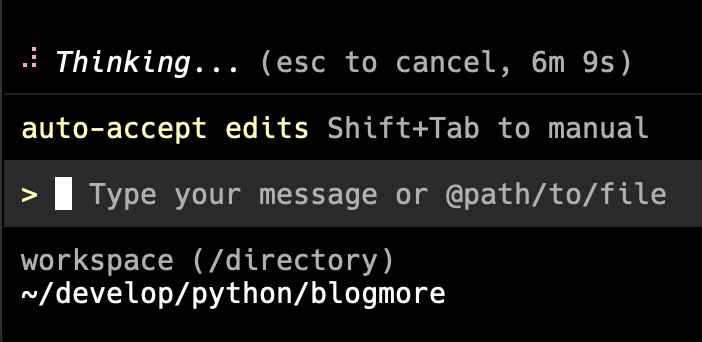
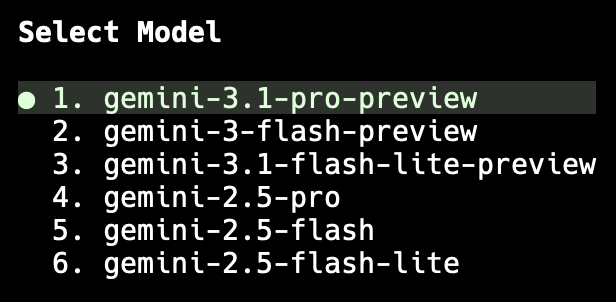
I was working on something new for BlogMore and, sure enough, after a wee while, we got stuck in "Thinking..." mode. So I hit Escape and asked to pick a different model. I chose to pick manually, and went with gemini-3.1-pro-preview.
I then literally asked that it carry on where it left off...
...and it did! It worked. No more sitting around thinking for ages.
Watching the quota after doing this, it looks like the model I was using ate quota faster, but that was worth it given I've never come close to hitting full quota with Gemini CLI.
Once the immediate job was done, I went back to auto and it worked for a bit, only to get stuck thinking again. I repeated this process and it did the trick a second time. From now on I'm going to use this approach.
It does, again, highlight how unreliable these tools are, but at least I've found a workaround that works for now.
After starting to make use of the GitLab/Codeberg sync approach for various repositories, I found that my muscle memory in Magit was getting the better of me and, on occasion, I'd push a new branch to backups when I wanted origin. I sensed there had to be a way round that.
As mentioned a couple of days ago, I've been toying with finding areas of improvement in respect to the performance of BlogMore. Until now, for good reasons, I've not really paid any attention to how fast (or slow) BlogMore is when it comes to generating my blog. While it's never been blindingly fast, it's always been fast enough and I was more keen on making it work right. So for a good while the focus has been on well-formed output, stuff that keeps the crawlers happy, that sort of thing.
But now that I'm in a place where new features aren't really so necessary, it does feel like a good point to find any easy wins in speeding up the code. I think it's gone well.
BlogMore v2.22.0 contains quite a few internal changes that speed up some core parts of site generation. Many of the things identified by Gemini, back when I first kicked this process off, have been done. The amount of Markdown->HTML conversion work has been vastly reduced, which has had a pretty big impact on all sorts of things. There's also caching of the FontAwesome metadata1 which should save a fair bit of time on slower connections. I did avoid the whole business of parallel processing as I dabbled with this near the start of the project and I could not wrangle a win out of that at all; given how much of a win I've had with these changes, I doubt that would change (it could conceivably make things worse).
So, how much faster is it? Roughly, based on my tests, a site generates in about 1/4 of the time it did before. On my M2 Mac Mini my blog builds in under 3 seconds; with v2.21.0 it took around 13 seconds. In my case that's with all the optional features of BlogMore turned on.
Naturally this work has touched on a lot of internals of the code, and made significant changes to the generation pipelines of lots of different pages and features. I've done my absolute best to compare2 the output of v2.21.0 and v2.22.0 and I can't see any significant differences3. When trying out v2.22.0 I would suggest paying just a little extra attention to the result, to be sure you're happy that nothing has changed.
It lives in ~/.cache/blogmore on Unix and Unix-like systems, or %LOCALAPPDATA%\blogmore\cache on DOS/VMS-influenced systems. ↩
Lots of diff -rq and then diffing an assorted sample of files that showed differences to inspect what was actually different. ↩
Actually, there's a small difference in the context shown in backlinks, but this was a deliberate change and a very small cosmetic enhancement. ↩
Well, it's here: GitHub's tool to let you see how much better off you're going to be under the new Copilot billing system that comes in next month. It's... something.
But let's set the background first. I'm here (in Copilot usage space) as an observer, spending time on an experiment that started with the free pro tier and then transitioned into the "okay, I'll play along for $10 a month, the tool I'm building is fun to work on and is useful to me" phase. I doubted it would last forever -- the price was obviously too good to be true for too long -- but I wasn't expecting it to collapse quite so soon and in quite such a spectacular way.
When GitHub announced the move to usage-based billing I was curious to see if I'd be better off or worse off. It was hard to call really. My use of Copilot is sporadic, and as BlogMore has started to settle down and reach a state approaching feature-saturation the need to do heavy work on it has reduced. I did use it a fair bit last month, but that was more in tinkering and experimenting mode rather than full development mode1, so it's probably a good measure.
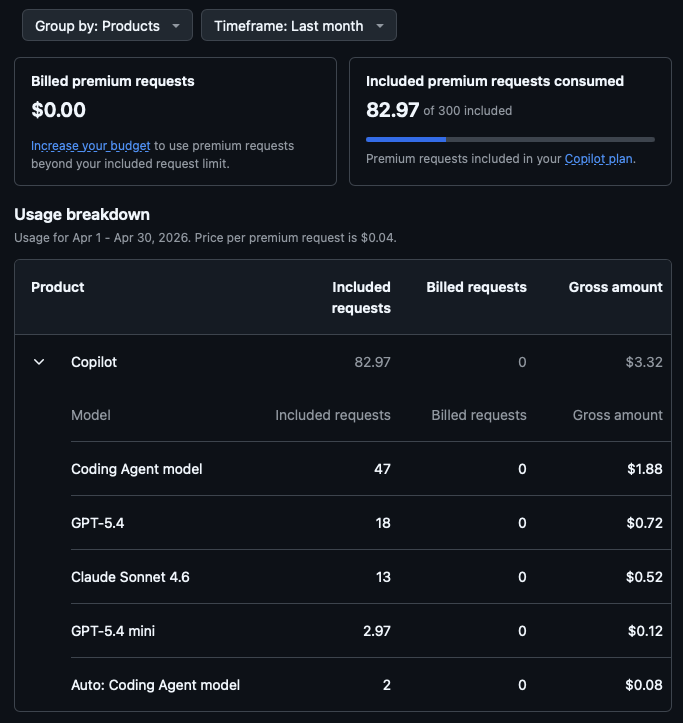
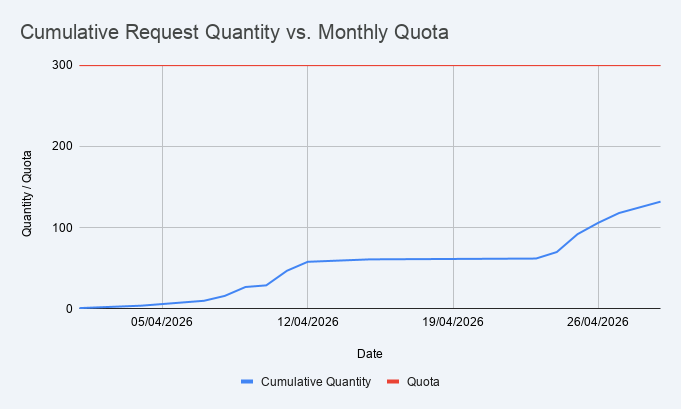
Checking the details on GitHub, it looks like I used a touch under 1/3 of my premium requests.
It also looks like the usage came in a couple of bursts lasting a few days, with a pretty flat period in the middle of the month.
So, technically, GitHub won. I paid them $10 for 300 premium requests, I left a touch over 2/3 unused. I think it's fair to suggest that I'm a pretty lightweight user, even when I have a project under active development.
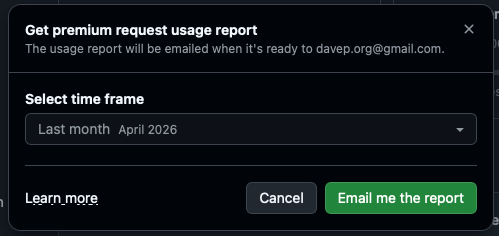
This is where the new usage-based preview tool comes in. Launched yesterday, it lets you take your existing usage stats and see how much it would have really cost you.
The app itself comes over as being hastily spat out with an agent and little communication between responsible teams. You'd think you just press a button when viewing some historical usage figures and get a display that shows you what it would cost under the new approach.
You'd think.
Nope. First you generate your report for a particular month. Then have to ask for it to be emailed to you as a CSV!
Even that part isn't super reliable. When I tried it last night it took a wee while to turn up, and that was after about 10 attempts where I got an error message saying it couldn't generate the report. This morning I tried again and I've yet to see the email, 30 minutes later2.
Having done that you click through to another page/app where you have to upload the CSV, to GitHub, that GitHub just sent you in an email. Brilliant. It then gives you the good news.
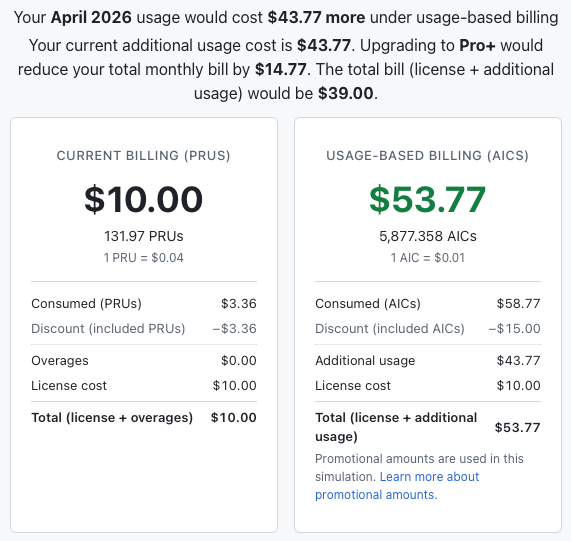
So what is my 1/3 use of the premium request allowance going to save me under the new approach to billing?
Amazing. I especially like the part where they spin it as: if I spent $39/month with them I would save money!
Watching this journey has been wild. The free Pro as a taster to get me onto $10/month I can go with, that's fair enough. For the longest time I never even paid it any attention. But watching GitHub give it to so many people, and especially so many students, and then watching them do shocked Pikachu when it cost them an arm and a leg and probably caused the degradation of the performance of their systems... who could possibly have seen this coming? Impossible to predict.
Back when I first wrote about my initial impressions of working with Copilot I wondered in the conclusion if I'd transition to a paying version of Copilot. I obviously did. At $10/month it was a very affordable tinker toy that gave me a new dimension to the hobby side of my love of creating things with code. But the prospect of paying $39/month for something in the region of 1/3 of requests that I had before: nah, I'm not into that.
It looks like this month will be the last month I keep a Copilot subscription. BlogMore will carry on being developed, I'll probably transition to leaning on Gemini CLI more (as I have been the last week anyway), and also start to get my hands dirty with the code more too.
This feels like one of the early signs of the bait and switch that the AI suppliers have been building up all along. Experimenting and better understanding how and why people use these tools has been seriously useful, and I can't help but feel that I accidentally started at just the right moment. Watching this happen, with actual experience of what's going on, is very educational. It's going to be super interesting to see if this same stunt gets pulled on a bigger scale, with all the companies that uncritically embraced AI at every level of their organisation.
It's going to be especially interesting to watch the AI leaders in those companies to see how they spin this, if and when the real costs are more widely applied.
Is my recollection. I should probably review the ChangeLog and see what I actually did add in April. ↩