I've released v2.33.0 of BlogMore, which extends the stats page some more, and also adds a tool so a user can do all sorts of fun things with the raw data of their posts.
The addition to the stats page is a list of years along with the top five words that characterise the focused subject for those years. This is done using TF-IDF. While the results for my blog don't come as a surprise, I am pleased to see that it does turn out pretty much how I would have expected:
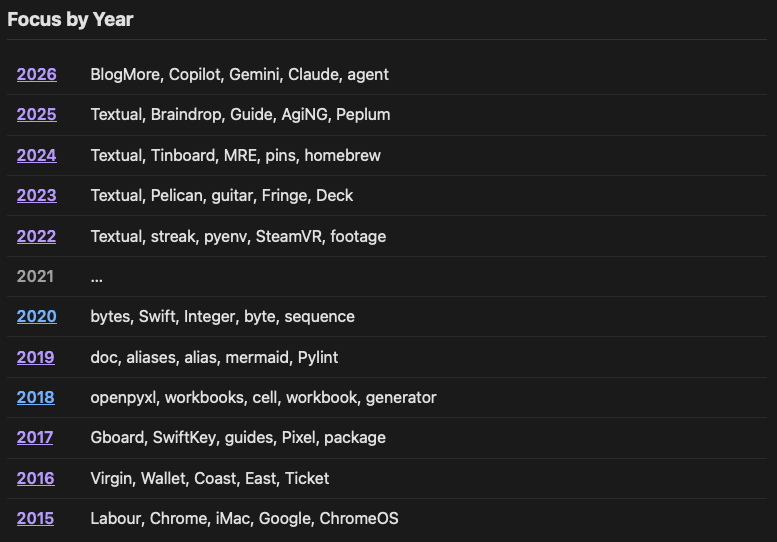
This feels like another fun way to learn something about the post history for your own blog.
Which got me thinking: there's probably any number of other niche and bizarre things that could be done with the content of a blog to gain some insight as to its history, and I really shouldn't just keep adding more and more things to the stats page. But what if I wanted a way to run some code over all the posts? Wouldn't it be useful if I could get all of the parsed post data in JSON format so I can play with it?
With that idea in mind, I added the dump command. When run, it will print to stdout a full dump of all of your posts, as JSON, so you can then write your own nifty tool to read it back in and do any number of interesting checks, tests, reformats or manipulations. For example, if I wanted to use jq to pull out the metadata for this particular post I could:
blogmore dump | jq '.[] | select(.id == "posts/2026/05/2026-05-29-blogmore-v2-33-0.md") | .metadata'
which gives me this result:
{
"title": "BlogMore v2.33.0",
"date": "2026-05-29 14:14:10+0100",
"category": "Coding",
"tags": "BlogMore, Coding, PyPI, Python",
"cover": "/attachments/2026/05/29/focus.webp"
}
I can see this being pretty useful to blogmore.el at some point, if I want to add some better querying tools or similar (not that I'd want to run a dump every time, it does require that a full parse and render has to happen).
Hopefully this will be useful to someone else. I know I'll be toying with it to find out other things about my posting history.