Given I'm almost certainly going to drop GitHub Copilot starting next month, I'm using Gemini CLI more and more for BlogMore. Yesterday evening, I used it to plan out an idea for a change to the application. Now that I've migrated all images to WebP, I thought it might be interesting to look at the idea of having a responsive approach to images. This is something I don't know a whole lot about (never having needed to bother with it before), but it also happens that I need to read up on this anyway for something related to the day job; given this, it felt like a good time to experiment.
This morning, over second coffee, I've kicked off the job of implementing it and, honestly, Gemini CLI is really struggling. It "implemented" the change pretty quickly, within minutes, but it just plain didn't work. Since then I've had it iterate over the issue four times and now it's struggling to make it work at all. It's still beavering away on this as I type, and consuming daily quota at a fair rate too.
So, while I still have GitHub Copilot, this feels like a good point to play them off against each other at least one more time. Having saved the plan Gemini wrote last night as an issue, I've assigned it to Copilot (using Claude Sonnet 4.6). As I type this, I have Gemini racing to get this working in a terminal window behind Emacs, meanwhile there's Claude doing its thing in GitHub's cloud.
It'll be interesting to see if Copilot manages to one-shot this, for sure Gemini is far off a one-shot implementation.
As I mentioned before: I've done this by hand, one post at a time, also adding missing covers as I go. The process went faster than I anticipated and I found that adding linting support to BlogMore really helped with this process. Each time I made a batch of changes I could run the linter to make sure I'd not broken any image links.
As for the result: I've brought the total size of images on the blog down from around 56MB to about 32MB, give or take (keep in mind the latter figure also includes all the WebP images I've added while blogging since I started this process). While I don't really have to worry so much about the storage costs of these images (I'm using GitHub Pages after all), overall, over time, there should be savings in the time it takes for readers to load any given page.
It's now well over a year since I released Braindrop and it's in constant use by me. I continue to find raindrop.io a really useful resource, and more often than not manage, edit, tag, and review what I save there with Braindrop, including which become public, and which don't.
So with the release of v1.1.0 I've added three new commands to the application:
JumpToNavigation - Jump to the navigation panel; bound to 1 by default
JumpToRaindrops - Jump to the main raindrops list panel; bound to 2 by default
JumpToDetails - Jump to the details panel for the selected raindrop, if the panel is visible; bound to 3 by default
Now it's just a little easier and quicker to get around the UI.
If raindrop.io is your thing, and you want to work with your saved bookmarks in the terminal: Braindrop is licensed GPL-3.0 and available via GitHub and also via PyPI. It can also be installed using uv:
uvtoolinstallbraindrop
If you don't have uv installed you can use uvx.sh to perform the installation. For GNU/Linux or macOS or similar:
For the past few years, pretty much every evening for a couple of hours, I would stream while playing games on my PS5. Before that I went through a period of streaming while playing games on my VR gaming setup, often mucking about in things like cyubeVR and Gunman Contracts. It was a fun time and I got the chance to make some fun acquaintances online. All of this was made possible by the fact that I had a really nice, fast fibre connection where I lived.
Late on last year I moved. Unfortunately the location I moved to didn't have fibre available. That's not to say the house lacked fibre; it was that it wasn't even possible to get it to the house. For some time it wasn't clear that it ever would be. So I was back on 35Mbps down and 3Mbps up, on a good day. Not a good streaming experience at all.
I tried. I had a few sessions. Sometimes it would fail. Sometimes it would work but the quality would be bad. It wasn't a good time. Because of this I've taken an extended break from streaming.
The complete lack of availability of fibre changed a couple of months ago. Since moving I've made a point, every few weeks, of going and seeing if there are any plans to run fibre to our location. Finally, back in March, one day, I checked and I COULD ORDER FIBRE!
I'd actually been through this whole thing once before. When I moved back in 2019, I went from a 35/3 connection (which still seemed pretty fast then) down to a horrible 5/0.6, on a good day, kind of connection. That was hard (although a deeply worthwhile trade under the circumstances at the time). When I finally got fibre at that place it was amazing. I went from 5/0.6 to 950/150 overnight. It felt like I had my whole Steam Library locally available the whole time.
So, when I realised that fibre was available to me again, that was an instant sell. As I say, this happened back in March and I still don't have it, because actual digging and stuff has had to happen. People had to write to people to get permission to do things, and so on. It's been kind of agonising watching the slow but steady progress towards being very online again.
But, soon enough, I should be back. I won't stream as much as I used to, just because the move entailed having other things to be doing in my evenings, and having new responsibilities. But I do aim to get some gaming in two or three times a week, most weeks. Also, whereas the last few times I've streamed it's been me mostly messing about in Death Stranding 2, once I have a reasonable connection again I think it'll be time to pick a new game and (attempt to) play it through.
No plans on which game yet, but there's a handful on my "to consider" list.
I wasn't quite planning on making a new release of BlogMore so soon after the previous version, but I had a couple of ideas that I wanted to add, and then also got a nifty request too; so here we are: we have v2.23.0.
The first couple of changes relate to the cache. In the previous release I added a cache of the FontAwesome metadata, which in turn means that a cache directory is being created. I felt it would be fair and useful to provide a command that both lets the user know where the cache lives, and to also remove it. So now BlogMore has a cache command with two sub-commands:
location: tells you where the cache directory is located
clear: removes the cache directory
Also, now that we have a cache directory, it makes sense to use it a bit more to squeeze even more time out of the build process. So starting with this release, per content directory, the various icons that are created for the site are cached. This means that if the source image doesn't change, for each subsequent build there's no conversion and resize for every variation. This saves a good fraction of a second, making the build of my blog feel noticeably quicker.
Finally, earlier today, Andy asked if it would be possible to have the BlogMore serve mode auto-reload any page being viewed in a browser, when the site is regenerated. It was something I'd considered myself a couple of times so that was a good reason to finally look into it. Not knowing how this could be achieved1, I prompted Gemini for an idea, stressing I wanted a solution that didn't disturb a generated site; it came up with a convincing solution. I let it run at it and, along with a few changes of my own, it seems to be working a treat.
This, of course, now makes me want to squeeze even more time out of the build process.
Web development has never been my primary area of knowledge. ↩
While I've had some troubles with it -- as can be seen here, here and here for example -- I'm mostly having an okay time. The code it writes isn't too bad, and while it seems to need a little more direction and overseeing than I've been used to while using Copilot/Claude, it generally seems to arrive at sensible solutions for the problems I'm throwing at it1.
One difference with working with Copilot CLI that I have noticed, however, is that Gemini doesn't seem to care for cleaning up after itself. When faced with a problem it'll often write a test program or two, perhaps even create a subdirectory to hold some test data, run the tests and be sure about the outcome. This is good to see. It's not unusual for me to do this myself (or at least in the REPL anyway). But it really doesn't seem to care to actually clean up those tests. A handful of times now I've had it leave those files and directories kicking around. I've even said to it "please clean up your test files" and it's gone right ahead and done so, which suggests it "knows" what it did and what it should do.
This also feels like a new source of mess for all the people who commit their executables and the like to their repositories. That should be fun.
The thing I don't know or understand, at least at the moment, is if this is down to the CLI harness itself, or the choice of model, or a combination of both, or something else. I'm curious to know more.
There is a weird thing I'm seeing, which I want to try and properly capture at some point, where it'll start tinkering with unrelated code, I'll undo the change, it'll throw it back in the next go, I'll undo, rinse, repeat... ↩
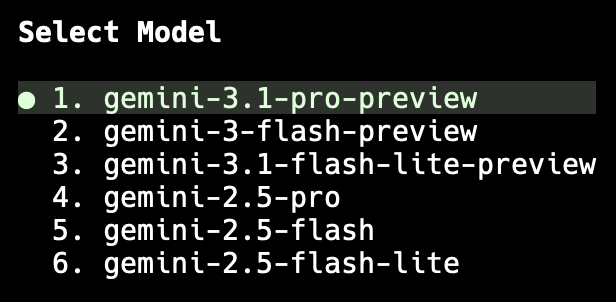
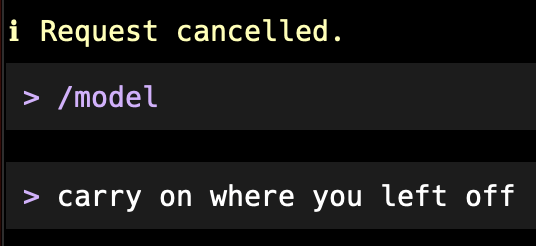
I was working on something new for BlogMore and, sure enough, after a wee while, we got stuck in "Thinking..." mode. So I hit Escape and asked to pick a different model. I chose to pick manually, and went with gemini-3.1-pro-preview.
I then literally asked that it carry on where it left off...
...and it did! It worked. No more sitting around thinking for ages.
Watching the quota after doing this, it looks like the model I was using ate quota faster, but that was worth it given I've never come close to hitting full quota with Gemini CLI.
Once the immediate job was done, I went back to auto and it worked for a bit, only to get stuck thinking again. I repeated this process and it did the trick a second time. From now on I'm going to use this approach.
It does, again, highlight how unreliable these tools are, but at least I've found a workaround that works for now.
After starting to make use of the GitLab/Codeberg sync approach for various repositories, I found that my muscle memory in Magit was getting the better of me and, on occasion, I'd push a new branch to backups when I wanted origin. I sensed there had to be a way round that.
As mentioned a couple of days ago, I've been toying with finding areas of improvement in respect to the performance of BlogMore. Until now, for good reasons, I've not really paid any attention to how fast (or slow) BlogMore is when it comes to generating my blog. While it's never been blindingly fast, it's always been fast enough and I was more keen on making it work right. So for a good while the focus has been on well-formed output, stuff that keeps the crawlers happy, that sort of thing.
But now that I'm in a place where new features aren't really so necessary, it does feel like a good point to find any easy wins in speeding up the code. I think it's gone well.
BlogMore v2.22.0 contains quite a few internal changes that speed up some core parts of site generation. Many of the things identified by Gemini, back when I first kicked this process off, have been done. The amount of Markdown->HTML conversion work has been vastly reduced, which has had a pretty big impact on all sorts of things. There's also caching of the FontAwesome metadata1 which should save a fair bit of time on slower connections. I did avoid the whole business of parallel processing as I dabbled with this near the start of the project and I could not wrangle a win out of that at all; given how much of a win I've had with these changes, I doubt that would change (it could conceivably make things worse).
So, how much faster is it? Roughly, based on my tests, a site generates in about 1/4 of the time it did before. On my M2 Mac Mini my blog builds in under 3 seconds; with v2.21.0 it took around 13 seconds. In my case that's with all the optional features of BlogMore turned on.
Naturally this work has touched on a lot of internals of the code, and made significant changes to the generation pipelines of lots of different pages and features. I've done my absolute best to compare2 the output of v2.21.0 and v2.22.0 and I can't see any significant differences3. When trying out v2.22.0 I would suggest paying just a little extra attention to the result, to be sure you're happy that nothing has changed.
It lives in ~/.cache/blogmore on Unix and Unix-like systems, or %LOCALAPPDATA%\blogmore\cache on DOS/VMS-influenced systems. ↩
Lots of diff -rq and then diffing an assorted sample of files that showed differences to inspect what was actually different. ↩
Actually, there's a small difference in the context shown in backlinks, but this was a deliberate change and a very small cosmetic enhancement. ↩
Well, it's here: GitHub's tool to let you see how much better off you're going to be under the new Copilot billing system that comes in next month. It's... something.
But let's set the background first. I'm here (in Copilot usage space) as an observer, spending time on an experiment that started with the free pro tier and then transitioned into the "okay, I'll play along for $10 a month, the tool I'm building is fun to work on and is useful to me" phase. I doubted it would last forever -- the price was obviously too good to be true for too long -- but I wasn't expecting it to collapse quite so soon and in quite such a spectacular way.
When GitHub announced the move to usage-based billing I was curious to see if I'd be better off or worse off. It was hard to call really. My use of Copilot is sporadic, and as BlogMore has started to settle down and reach a state approaching feature-saturation the need to do heavy work on it has reduced. I did use it a fair bit last month, but that was more in tinkering and experimenting mode rather than full development mode1, so it's probably a good measure.
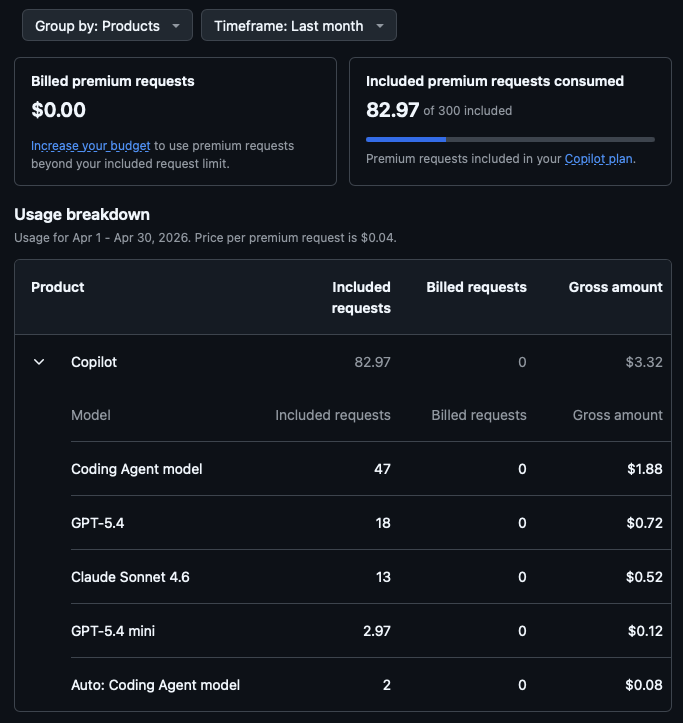
Checking the details on GitHub, it looks like I used a touch under 1/3 of my premium requests.
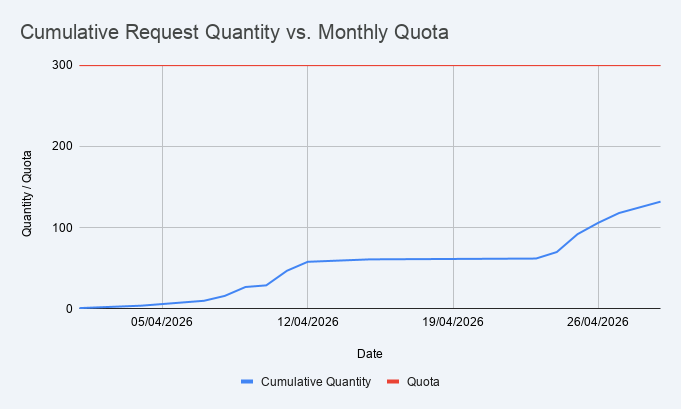
It also looks like the usage came in a couple of bursts lasting a few days, with a pretty flat period in the middle of the month.
So, technically, GitHub won. I paid them $10 for 300 premium requests, I left a touch over 2/3 unused. I think it's fair to suggest that I'm a pretty lightweight user, even when I have a project under active development.
This is where the new usage-based preview tool comes in. Launched yesterday, it lets you take your existing usage stats and see how much it would have really cost you.
The app itself comes over as being hastily spat out with an agent and little communication between responsible teams. You'd think you just press a button when viewing some historical usage figures and get a display that shows you what it would cost under the new approach.
You'd think.
Nope. First you generate your report for a particular month. Then have to ask for it to be emailed to you as a CSV!
Even that part isn't super reliable. When I tried it last night it took a wee while to turn up, and that was after about 10 attempts where I got an error message saying it couldn't generate the report. This morning I tried again and I've yet to see the email, 30 minutes later2.
Having done that you click through to another page/app where you have to upload the CSV, to GitHub, that GitHub just sent you in an email. Brilliant. It then gives you the good news.
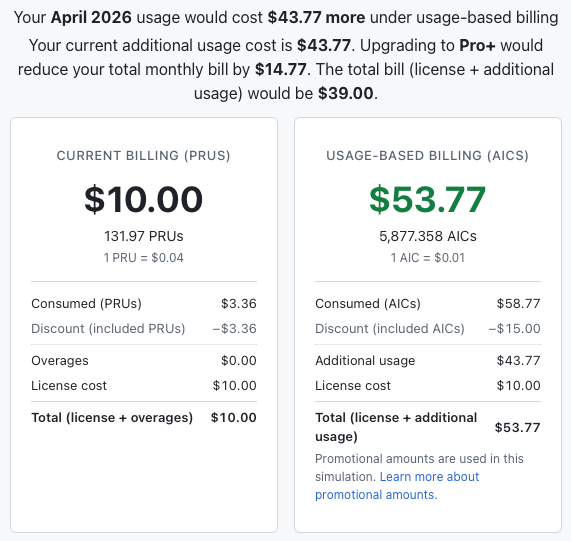
So what is my 1/3 use of the premium request allowance going to save me under the new approach to billing?
Amazing. I especially like the part where they spin it as: if I spent $39/month with them I would save money!
Watching this journey has been wild. The free Pro as a taster to get me onto $10/month I can go with, that's fair enough. For the longest time I never even paid it any attention. But watching GitHub give it to so many people, and especially so many students, and then watching them do shocked Pikachu when it cost them an arm and a leg and probably caused the degradation of the performance of their systems... who could possibly have seen this coming? Impossible to predict.
Back when I first wrote about my initial impressions of working with Copilot I wondered in the conclusion if I'd transition to a paying version of Copilot. I obviously did. At $10/month it was a very affordable tinker toy that gave me a new dimension to the hobby side of my love of creating things with code. But the prospect of paying $39/month for something in the region of 1/3 of requests that I had before: nah, I'm not into that.
It looks like this month will be the last month I keep a Copilot subscription. BlogMore will carry on being developed, I'll probably transition to leaning on Gemini CLI more (as I have been the last week anyway), and also start to get my hands dirty with the code more too.
This feels like one of the early signs of the bait and switch that the AI suppliers have been building up all along. Experimenting and better understanding how and why people use these tools has been seriously useful, and I can't help but feel that I accidentally started at just the right moment. Watching this happen, with actual experience of what's going on, is very educational. It's going to be super interesting to see if this same stunt gets pulled on a bigger scale, with all the companies that uncritically embraced AI at every level of their organisation.
It's going to be especially interesting to watch the AI leaders in those companies to see how they spin this, if and when the real costs are more widely applied.
Is my recollection. I should probably review the ChangeLog and see what I actually did add in April. ↩