Well, what a surprise, nobody could have seen it coming: it does seem to be bait and switch season in LLM/agent land.
As I mentioned earlier today, when I ran up Gemini CLI to have it work on a change to BlogMore in the background, I got a notification that I should be swapping to Antigravity CLI instead. I let Gemini CLI get on with the change anyway, but resolved to install Antigravity CLI and give it a go. While there's still a touch under a month of use of Gemini CLI to go (based on the blog post), it seems sensible to get to know the new tool as soon as possible.
Installing Antigravity was a little bit of a faff. Looking at the documentation, you have to install the main application itself first, authorise with that, and then you can install and use the CLI. Fair enough. Rather than download the DMG from their website, I decided to go with the Homebrew installation (I like to try and keep track of what I have installed and this helps me do that).
So I installed that, ran it up, went through some setup questions, then finally got dropped in something that looked like it wanted to be an IDE of sorts. Nah, I'm fine, I like to work elsewhere. But that was okay given that I just wanted to get to the CLI anyway. Before I did that though, having installed this app, I saw that it was showing a "Restart to update" notification. So I did that, waited a wee while, and then finally was presented with something that looked totally different. Now I had an application that looked almost exactly like the main Gemini website (or the Gemini macOS application).
So that was kind of weird.
Finally I was in a position to install the CLI itself. From what I can see it's not available via Homebrew yet, and the installation instructions are the usual "curl this through bash, trust me bro" affair. Having done that (yes, yes, I know...), I was all set.

Credit where it's due, when I ran it up it just worked. As in: I didn't need to authorise again or anything like that; the fact that I'd set everything up via the main application did seem to have done that job.
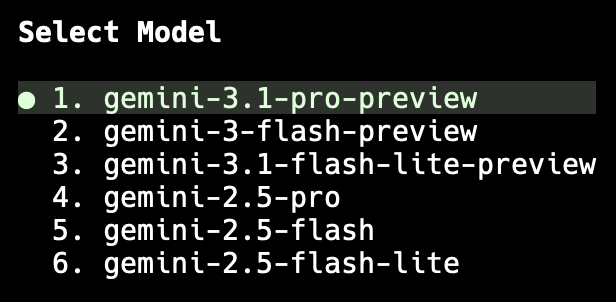
After this though, it kind of went a little downhill. The first thing I noticed was the set of models available was rather different from Gemini CLI. I mean, okay, that's fair, I guess you expect things like that to change, but in my inexperienced1 view of what these agentic tools offer, it looked like all the options were a little more... pricey, perhaps?

Still, I'm sure that sensible defaults are chosen out of the box, so it seemed like a good time to give this new tool a shot. I had a nice little problem for it to work on so that felt like a great test. It's hard to say for sure, but I feel like an issue like that, with the right prompt, would have used up somewhere between 3% and 5% of the daily quota in Gemini CLI, using Auto (Gemini 3). That was the default out of the box and, aside from tapping the models to try and unstick them, I've never really set it to anything else and the results have always been fine. With all this in mind I set Antigravity to work. Given that there didn't seem to be any sort of "Auto" option, I let it go with Gemini 3.5 Flash (High), which is what it was set to out of the box.
Yikes.

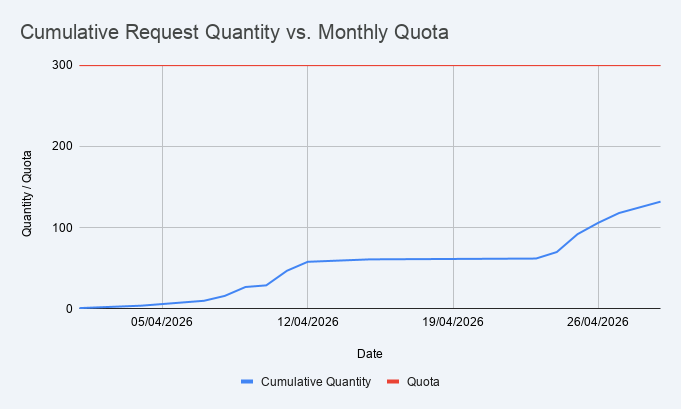
As I read that, and as I recall what happened, it took about 25 minutes to get to a reasonable solution to the request, with me pushing back on a couple of wild choices it made about how to change the code around. In doing this it left me with just 20% of the quota free for the next four and a half hours.
Yikes.
This is fine in this particular situation, where I'm conducting a long-term experiment and often letting the tool run at reasonably self-contained problems, in the background, while I get on with other more important things. But if I were to try and use this, as I have Gemini CLI, for an evening of sofa-hacking, refactoring lots of code or adding a handful of new features... that's not going to be sustainable. Any such session is going to grind to a halt pretty quickly. Presumably the intended solution here is that I buy myself lots of "AI credits".

I will experiment more, and intend to try and work out what the point, purpose and impact of each of the models are, as found in Antigravity. Doubtless there's a smarter approach I can take where it'll cost less quota for similar results. What is for sure though is that Antigravity CLI is not a drop-in replacement for Gemini CLI. It seems to be a different way of working, with different models, and different considerations. Also with less openness too.
It's interesting to drop in on the Gemini CLI subreddit, where the members seem to be experiencing what the Copilot folk were a week or so back. People finding they're chewing through their quota in no time, only with the added frustration of having to transition to a whole new application that seems to be lacking some features they're used to.
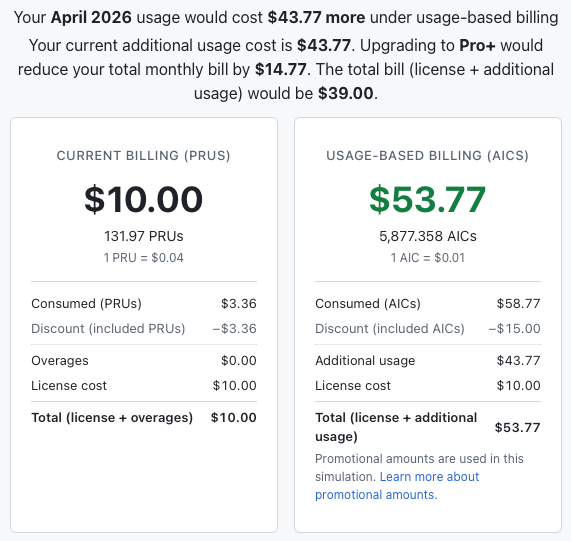
None of this is shocking to me -- although I'll admit that I thought the Gemini CLI ride might last a wee while longer than it did -- nor, I'd hope, to anyone else, but it continues to be fascinating to watch the squeeze being applied all around this tool space. This is going to be an increasingly worse time for anyone wanting to mess with agents for hobby projects. The idea of a tool that lets you get unambitious projects done for the price of a coffee or two, per month: that was a reasonable prospect. When the real cost turns out to be similar to an actual utility bill for your home... I know some people have expensive hobbies, but this would not seem to be a rewarding one at the sorts of costs we're starting to look at.
Once again, it's going to be interesting to see how engineering departments, and AI-embracing companies as a whole, react, as they become more and more invested in these third-party services, and less able to actually do things themselves, while at the same time the suppliers of those services squeeze them harder to try and make this adventure pay off.
I say "inexperienced", but perhaps I'm being unfair to myself here. While I'm not 100%, all in, fully-steeped in agentic lore, and even though I've not been living this stuff full time for the past year or so, I do feel I'm a good representation of someone with a long background in the software development industry who is coming to these tools with reasonable expectations. ↩