I just grabbed and opened up the MacBook Air and met this:
First time I've ever seen this and I've been using Ghostty for quite a while now.
To be fair, the MacBook did update to 26.4.1 overnight and has tried to get back to the state it was in before the restart, so I imagine that's the cause. But I've never seen this before.
I'm all good now; I ⌘-q the app and started it again and there's no sign of a problem.
The experiment with building an MCP server continues, with some hacking on it happening over a couple of hours while killing time in an Edinburgh coffee shop.
It is, of course, a solution looking for a problem, and I suspect I'm the only person who will ever use it, and even then only as a test, but building it is proving interesting.
The main changes in v0.2.0 are:
I turned the current search_guide tool into a line_search_guide tool (because that's what it was doing: a line-by-line search).
I added a body_search_guide tool that treats all the lines in an entry as a single block of text and then does the search in that (so searches over line breaks will work).
I added a read_entry_source tool that, rather than rendering the entry of a guide as plain text with all the markup removed, it instead delivers the underlying "source" for the entry; something that could be useful if you wanted to get an agent to convert it into another marked-up body of text.
I added a markup glossary resource, which technically tells an agent everything it needs to know about Norton Guide markup.
The latter one is interesting. I added it and did some experimenting locally and it seemed to be helpful and I could ask questions about markup and Copilot seemed to use it. Meanwhile, having installed v0.2.0 globally on my machine, and having enabled it, I'm finding that Copilot seems to have zero clue about the markup and instead is using the server to go off and read the guides to work out the markup1.
On the other hand, the new "get source" tool seems to work a treat.
So I suspect I still have some reading/experimenting to do when it comes to resources, so I can better understand why I'd want to provide them and what problem they solve.
All credit to it: it did find CREATING.NG and read the markup out of that. ↩
This morning I'm tinkering some more with NGMCP. Having done a release yesterday and tested it out by globally installing it with:
uvtoolinstallngmcp
I was then left with the question: how do I easily test the version of the code I'm working on, when I now have it set up globally? Having done the global installation I had ~/.copilot/mcp-config.json looking like this:
But now I want both. Ideally I'd want to be able to set up an override for a specific server in a specific repository. I did some searching and reading of the documentation and, from what I can tell, there's no method of doing that right now1. So I've settled on this:
and then in Copilot CLI I just use the /mcp command to enable one and disable the other. It's kind of clunky, but it works.
I did see the suggestion that you can write your MCP server so that it does a non-response depending on the context, but that seems horribly situation-specific and wouldn't really help in this case anyway because I want it to work in both contexts, depending on what I'm doing. ↩
Recently I've been thinking that it would be interesting to get to know a little about the Model Context Protocol and see what it's about and get a feel for how useful it might be, if at all, for anything I do.
As always happens when I want to try out something new, I reached for a problem I know well so I don't have to get bogged down in solving the problem itself. As almost always happens, I decided I should base it around Norton Guides.
Part of the point of MCP seems to be providing an interface over sources of data and actions, that an LLM might not otherwise be able to cope with, and so it sounded to me like providing a bridge to the content of Norton Guide files would be a perfect test. Of course, this isn't the first time I've bridged LLMs and NG files, but this is obviously intended to be a more generic solution than throwing a Markdown file at NotebookLM.
Earlier this afternoon I sat down and did some reading, and then decided to throw the problem at GitHub Copilot. I told it I wanted to use my NGDB library as the core of the tool, and that it should wrap it up with FastMCP. The initial result was... a bit of a mess. It sort of worked, sort of, but it also seemed to try and put together a project that mostly looked how my Python repos look, but with some bits just wrong.
So far I've given the code a fairly quick read over, and I can see what it's doing and how it's going about this. This approach obviously has the disadvantage that I didn't hand-write it so there's still a lot to read to really appreciate what's going on; on the other hand, it does have the advantage that it's implemented a tool based on my library so I know what to expect it to be doing.
There will be more code reading happening, and I also intend to look to tidy up the code more and perhaps hand-add some more features.
I very much doubt that this particular MCP server is going to be any use to anyone, but as a proof of concept it works well for me. If I were in a position of needing to build something genuinely useful, I now have a start and a vague idea.
On the other hand: once again, as with other projects I've done related to Norton Guides, this is a tool that helps keep the content available and accessible; that alone is one reason for me to tidy this up and move it towards v1.0.0 and keep it maintained.
If you fancy having a play, some (currently Copilot-generated) documentation can be found on the server's dedicated site. When I get a bit more time I'm going to flesh this out.
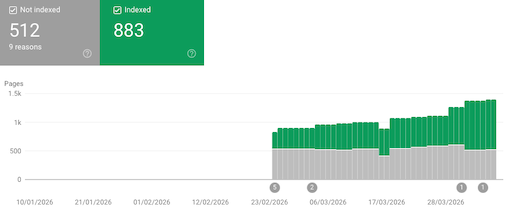
Following on from yesterday's release of BlogMore, I've been looking at some more information in the Google Search Console, which helped me uncover a couple more bugs in relation to URL generation.
This time I noticed a couple of issues, both related to the clean_urls setting. The first was that, in the recently added calendar page, all of the URLs for the links into the date-based archive weren't taking clean_urls into account. That's now fixed.
The second problem was the canonical<link> tag in the headers of the various archive pages (categories, tags, date-based): none of the URLs used in the tag were being cleaned up if clean_urls was true. That's now also fixed.
The main "problem" those two issues were causing was Google was seeing the sitemap for my blog declare one URL, but discovering different versions of the URL elsewhere; the main offending part here being the canonical URL declaration that disagreed with the sitemap.
To the best of my understanding the above fixes should clean a lot of that up.
Also in this new release is a small new feature. After cleaning up the sitemap generation in v2.12.0 I got to thinking that, perhaps, there would be occasions where a user would want to be able to add extra items to the sitemap. With this in mind I've added the sitemap_extras configuration property. With this you can declare extra URLs to drop into the sitemap, if one is being generated.
sitemap_extras:-/some/path/-/some/file.html
I don't think I have a use for this right now, I'm not sure I'll ever have a use for it, but it feels like a low-cost feature to add that could be useful to someone at some point.
This was a nice find yesterday: I think I came across it when someone I follow on Mastodon boosted a post from the account related to the site; it's a site called powRSS. The concept is pretty simple: collect links to all sorts of small blogs on all sorts of topics, and then provide a honking great discovery feed/pool. You can read more about the idea on their about page.
For sure, this sort of thing isn't exactly novel: those of us of a certain age will fondly remember the fun of webrings and other similar initiatives, not to mention feed aggregation sites where you could discover trending blogs or see what your friends were reading, and all that. But, to some degree, that fell out of favour and/or the limelight when social media got really popular.
So, with this in mind, I've made a change I've been planning from the start and have added a --split option. If used, if the generated file looks like it's going to hit the word limit, a second (or more) file will be created. The naming scheme is simple enough: if you ask obs2nlm to create an output file called dirt.md and it needs to run over, it'll then create dirt-2.md, dirt-3.md, and so on. The idea then is that, rather than upload that single Markdown file as a source, you upload all of the generated Markdown files.
Given you get up to 50 sources per notebook, this should see me right for any reasonable vault. As for if it will affect the quality of the results I get when I query the notebook... that's hard to say until I find myself in that situation. If Google are to be believed it shouldn't be an issue, and the alternative is to fall foul of the limit so this seems like the only sensible solution.
I've also added a --dry-run command line switch too; this should be handy for checking how big a vault is when compared to the word limit, without actually generating any files.
There are two motivations for this: the first is that, when it comes to my day job, I have cause to interact with people who do use the search console a lot, and so it's worth understanding what they work with and why it matters to them. The second reason is it's a reasonable measure of how good a site BlogMore generates.
So far the results have been pretty good, and the console has helped me find oddities and things that need tidying up.
So this release of BlogMore includes a couple of changes that stem from looking at the latest updates in the console.
The first is that I've cleaned up how the sitemap.xml gets generated. I noticed that if I had any HTML inside my extras directory it was turning up in the sitemap; something I didn't intend and didn't want. So that's now fixed: only pages generated by BlogMore will appear in sitemap.xml1.
The second is that the stats page, despite being in the sitemap, had a noindex header for some reason. That's now been fixed. The only generated page I've intentionally set up so that it isn't indexed is the search page.
Finally, there's one change unrelated to the above: I realised that if you have with_read_time set to false, the reading time stats still appeared on the stats page; that seems unnecessary and unwanted on a site that doesn't show reading times. So, as of v2.12.0, that section of the stats won't show if reading times are turned off.
Now I think about it, I suppose there might be occasion where someone wants extra HTML to appear in the sitemap. I might consider the idea of allowing extra entries to be declared via the configuration file. ↩
After adding the streak display to the stats a couple of days back, I got a little more obsessed with knowing what sort of runs of days of posting to the blog I had. I even said in that post:
It almost makes me want to do a whole-blog-lifetime version of it, or perhaps some sort of more calendar-oriented version of the archive.
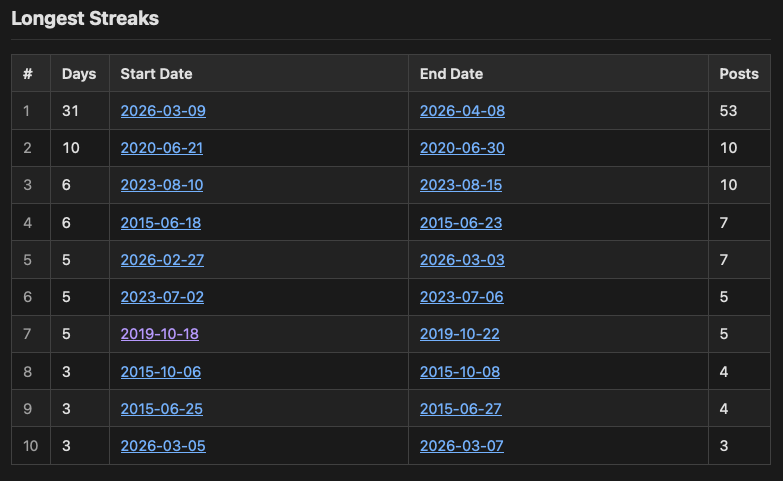
Despite saying that I fancied the idea of that calendar-type view, first off I got to thinking it would be interesting to see a table of my 10 longest streaks. So that got added and can now be found in the stats page.
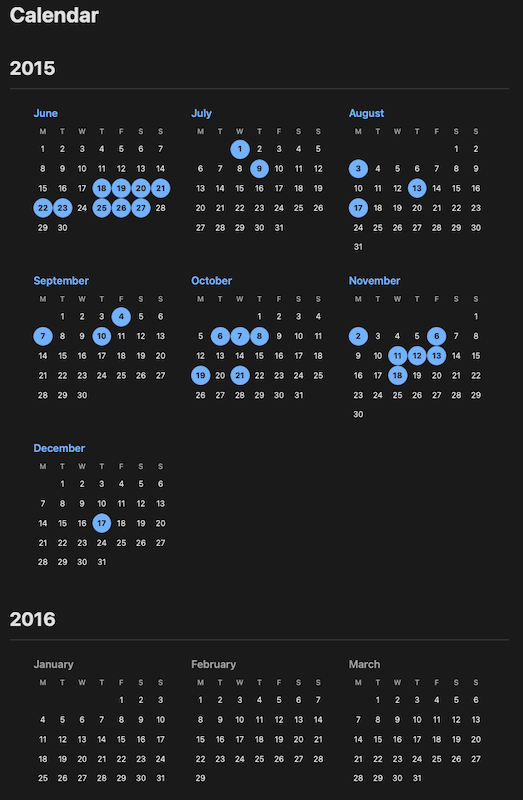
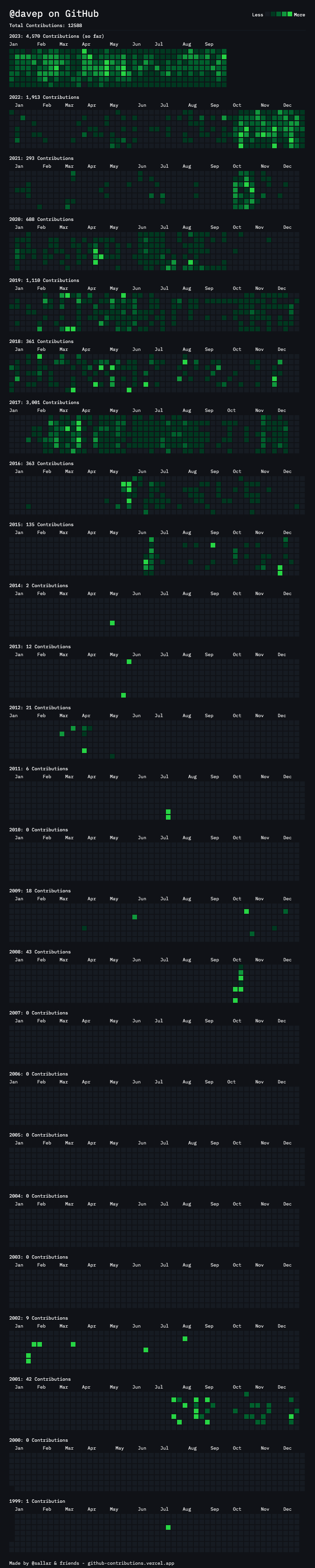
Having added that, I kept thinking about the whole-blog visual view of "here's the whole time of the blog, and here are the days you posted". I did think it might be interesting to use the same style and layout as the streak display -- perhaps something that would look like my whole contribution history on GitHub that I wrote about back in 2023 -- but the problem with that is it's tricky to make it work well on all display types. I needed something that would collapse better on smaller displays.
So now there is a with_calendar configuration option that, if set to true, will add a calendar link at the top of the site. By default it looks like this:
If it looks a little unconventional at first glance, that's because it is. I wanted something that started with the most recent month in which there's a post, and which then worked backwards. This way I can see things as a proper history. But I can also see that this might seem odd to some people. Given this, I've also added a forward_calendar configuration option that can be used (when set to true), to flip the calendar into a more normal flow.
As you might expect, the calendar links to other parts of the site: clicking on a day with a post takes you to the archive for that day, clicking on a month name where there are posts in a month takes you to the archive for that month, and the same again for a year title.
I'm pretty pleased with the result. In testing it seems nicely responsive to different display types and I'm also finding it to be yet another interesting way to discover older posts (and get a sense of when I was encouraged to post going back over the last 11 years of this particular blog1).
One final little feature I've added is a small enhancement to the read time that can appear on each post. While it's long since been possible to decide if you want it there or not, the calculation itself has been hard-wired to the assumption that 200 wpm is the reading speed of the reader. I've now added read_time_wpm as a configuration option so you can set it to suit your own taste.
I have other, much older, blogs out there on the net. One day I might merge them with this one and back-fill the whole thing. ↩
...those question headers are displaying differently, with the background colour no longer spanning the width of the window. I'd like to understand why.
It looks like, perhaps, at some point in the past, :extend was t by default, but it no longer is? Either way, explicitly setting it to t has done the trick.






{kind=link}