I've just made a small update to textual-enhanced, my core library used for most of my Textual-based applications. In v1.6.0 I've extended the "constructor" for ModalInput to allow passing in optional values for password, suggester, title and sub_title.
Most of the time I just want to quickly call on ModalInput to get input from the user. If I need anything more fancy, I roll my own dialog. But in some work I'm doing on Rogallo, it would be helpful for me to at least set the suggester. So, without adding every optional parameter for the Textual Input widget, I've extended what can be passed in to what I think will be a useful subset for my applications.
While adding the del method to the history classes, to make it easier for me to manipulate them as if they had the interface of a Python list, I totally forgot to add a clear method. Rogallo will need to be able to 100% clear history, as well as remove individual entries in the history, so that's kind of needed too.
I've just updated BagOfStuff with a change and addition, in anticipation of some work I'll be doing on Rogallo in the near future. The change is a small and simple one, adding del support to the history classes.
The addition is a simple cache manager. For now it's just a straightforward bit of code that, given a set of keyword arguments, creates a unique hash, sets up a directory, and returns a base filename within it. From there, any calling code can detect if the file(s) exist and make use of it/them, or otherwise get on with some work and populate the cache.
Of course, in the case of Rogallo, this is all going to be used to cache the Gemtext that is retrieved from capsules.
On the one hand, this looks like a fun idea: sort of a Second Life for websites. On the other hand, it's the worst of the Internet, which is no surprise.
The FSF, in effect, does what the FSF is there to do: defend the copyright of GNU Emacs (among other projects). Meanwhile someone attempts to contribute a patch written by a large language model, and seemingly gets offended that it's rejected. I think the worst part about it is they seem to think that being honest about using an LLM should let their contribution in.
A pretty fun Reddit post that contains a potted history of the evolution of Second Life. I've had an account for a good chunk of that time, and it all reads about right to me.
I love flying, even though I rarely do so -- I'm not one for travel. But when I get the chance to fly I find it hard to not just sit there, staring out of the window, marvelling at the view.
Today I got the chance to get a pretty good view of the area close to where I used to live when I first started this blog (and also where I lived when I maintained the blog that came before).
The route I flew actually covered a couple of places from my past life, going fairly close to York (where I was born and spent the first 18 years of my life), then carrying on down into Lincolnshire (where I used to live before moving to Scotland).
Much of the route was over broken cloud that made it tricky to really see obvious landmarks, although around Lincolnshire (without knowing I was over it at the time) I did see some shapes in the landscape that looked familiar. Then, after a small turn, and after a wee while, the cloud cleared and suddenly it was very obvious where I was. I had this excellent view of the Wash.
I know this sort of thing is conventional, everyday, and boring for many folk. Me: nope, not a chance. That I can have this sort of view is still a wonder to me.
I've just done a quick update to BlogMore, bumping the version to v2.44.1. This release fixes an issue with auto-cover generation where, if you changed some properties relating to a post (or the blog as a whole), the auto-covers weren't being updated to reflect those changes.
A good example is the description of a post. In the editorial-style cover, the description is shown; this is taken either from the first paragraph of the post or, if you've provided a description front matter value, it's taken from that property. The problem was that if you changed the post such that the text of the description changed, after a cover had been generated, it wasn't regenerated because it was already in the cache.
So this release is a bit more aggressive about when it will ignore the cached cover and generate a new one. The result is that the cover will reflect the changes.
There is, of course, a small downside to all of this (which was also an issue for v2.44.0 too): if you're working on a new post in serve mode, any time you change something that causes the cover to be recreated, the older versions of the cover will be left in the cache; in other words, there's a storage overhead to all of this.
For now, I'm just going to live with this downside (BlogMore has a cache clearing command anyway, so if it becomes an issue you can always use that). In the near future, though, I think I'm going to add a smart-clear sub-command to the cache command (or perhaps a --smart switch to the clear sub-command). This will go through the cache and find all the files that aren't currently "valid" and remove them, leaving all the "good" cache entries intact. That should be useful for occasional housekeeping without needing to wipe out the whole cache, and so greatly slowing the next build of a site because every single cover needs creating again, and every single optimised image needs generating again (if you have image optimisation turned on).
I've updated Rogallo to v0.4.0. The main new feature in this release is support for capsule-requested user input. There are some other simple additions too.
I've added a Reload command, bound to F5 by default. As you might imagine, it reloads whatever page you're looking at right now.
I've also added a pair of commands for copying things to the clipboard. There is CopyLocationToClipboard (bound to ctrl+shift+c by default) which, as the name suggests, copies the current location (either the Gemini URI or the path to the file depending on what you're viewing) to the clipboard. In a similar way, CopyDocumentToClipboard will copy the content of the document you're viewing (bound to alt+shift+c by default).
It's worth noting that the default bindings for both of those aren't going to be ideal for some terminals. They should be fine in any terminal that supports the Kitty keyboard protocol, but will likely do nothing elsewhere. This can be changed to your taste via the configuration file1.
Talking of a document's content: I've also added a ToggleView command (bound to F3 by default) which toggles the document's view between a rendered view and a plain text (source) view. So if you're looking at a page like this:
and want to know what the underlying source looks like, just toggle the view:
Finally, the most significant addition is support for capsule-requested user input. This handles a 10 or 11 response from a server, prompts the user for input, and then sends it back as a query.
It's worth noting that the sensitive input (response 11) isn't done in the most obvious way, on purpose. Normally I'd have taken the "do obscured password input" thing, which is supported by Textual's Input widget. The problem there though is that an input request from a Gemini server expects and allows for multi-line input2; that requires the use of a TextArea; it doesn't support password-style input.
So what I've done instead is, if it's a sensitive input request, I simply greatly lower the contrast of the text vs the background. This should match the "reduce shoulder-surfing opportunities" requirement while not making it impossible to see what you're doing.
Normally I wouldn't be satisfied with this approach given that the text will still be visible, but I think it's a fair solution given one glaring problem with Gemini's sensitive input facility: the input is always sent back as a URI query string. That means that the resulting input is part of the URI, will be visible in any URI display on the screen, will be part of the history, etc. The sensitive part is only about making it less obvious at the moment of input, so I think this approach is in that spirit.
So... that's it for v0.4.0, and that's also likely it for the next week or so. I'm going to be super busy in AFK life next week and into the week after, so work on Rogallo will pause. It's almost a shame, I'm having tons of fun working on it.
As mentioned in another post about Rogallo, how to do that will be documented when I get round to writing the documentation for Rogallo. Meanwhile look at similar documentation for Hike to get an idea of how to go about it. ↩
Well, technically, it's an optional feature of a client; the specification says "Clients MAY allow for the entry of input composed of multiple lines". I wish Rogallo to be one such client. ↩
It's been a short while since I last made a release of BlogMore; in fact, the time since the last update might be the longest I've gone between versions since the first release. I think this might mean it is actually more or less feature complete!
More or less.
Except... I did have to spend a bit of time (and some Antigravity quota) this morning adding something I've been wanting to add: automatic generation of cover images aimed at social media sites (so the kinds of images that show up when you post to Mastodon, Bluesky, or that other terrible site some people still seem intent on using for some perverse reason).
BlogMore has supported the declaration of a cover from the very first release. This was done in a way that it was up to the author of the post to create and include the image. Personally, in my posts, I've tended to set the cover to point at the most relevant image in the post, if a post has any images. I've also had BlogMore always work such that a post without a cover has the social image set to the site's logo image (if it has one).
This works, but it does mean that all of the posts I make that have no cover (feels like that's roughly half of them -- I could probably do something fun with the dump of posts to know for sure) simply show my masked face when I share them. That's by design, but not ideal.
So v2.44.0 adds support for an "auto covers" feature. I've tried to do this in a way that is fully backward-compatible. The feature itself is off by default, won't override any covers you have specifically set for posts, and can also be used and controlled on a per-post basis.
The core of the feature is controlled by a new auto_covers section in the configuration file. In here you can control if the feature is on or off by default, what layout to use for the cover images, what colours to use, and so on. There's plenty to experiment with and it should be fairly straightforward to create covers that look unique to your blog.
There are three styles of cover that can be generated. The minimalist does as the name suggests: it tries to keep things as minimal as possible (and will generally result in the smallest file).
The split type is a little richer, including the site logo if you've set one. Generally the image size will be bigger than minimalist.
Finally there is editorial, which includes the title, logo, the description for the post, the category and the tags. Because this is the busiest style it will generally result in the biggest file.
As you might imagine, generating these images for every post that doesn't have a cover set can be very time-consuming. Because of this the generated images are cached, so subsequent site generations should hardly ever be affected (unless you change any of the parameters relating to cover generation).
ℹ️ Note
As with image optimisation, this does mean that more storage is going to be used between blog builds. If you use this cover feature, not only will more images be created in your static site output, but the BlogMore cache related to the blog will also grow. Keep this in mind when deciding to use this feature.
It might also be the case that you don't want to generate cover images for all of your historical posts, but you do want them for all future posts. That approach is possible. All you need to do is set everything as you want it in the configuration file but set enabled under auto_covers to false. Then, for any post where you do want an auto-generated cover, simply set auto_cover in its frontmatter to an appropriate value. To go with the default settings, set it to default, or if you want to control the layout per-post, set it to the desired layout for that post.
To try and summarise, the rules for selecting a cover for a given post are something like:
If it has a cover set in its frontmatter, that is used.
If it has an auto_cover set to anything other than none in its frontmatter, the desired type of auto-cover will be used.
If it has neither cover nor auto_cover set, a cover will be generated if auto_covers.enabled is set to true.
Hopefully that's clear.
Despite this post having images in it, I've not set a cover for it and I have the following setup in my configuration file:
This should mean that, if I've got this all working correctly, this post, and all historical posts without a cover, get auto-generated covers. This should also be very evident as you hover over posts in the graph.
I've released Rogallo v0.3.0, which mostly concentrates on adding command line support and sorting support for browsing files in the local filesystem. There are also a couple of cosmetic configuration options thrown in.
Starting with the cosmetic configuration options: I got to feeling that the URI-containing tooltips that show on mouse-hover over a link might be a bit much for some people, so I've added show_link_tooltips to the configuration file1. Set it to false to make the tooltips go away.
Similar to this I've also added disable_animations. Out of the box Textualloves its animations. This is arguably most noticeable if you have a long body of text in a scrolling widget (such as the document viewer in Rogallo), as you use PgUp, PgDn, Home, End, etc., it'll scroll in a fancy animated way. It looks cool for a moment but I can imagine plenty of people getting sick of it, or feeling sick because of it (I sense this is an a11y issue too). With this in mind if disable_animations is set to true they'll all be turned off.
Rogallo now also has a number of command line options that can come in useful. In part borrowing from a number of my other TUI applications, and also adding some specific to Rogallo itself. They can be easily found with the --help switch:
Because I feel it's important that people know where applications drop things in your filesystem, there is the directories command, which shows you which directories are used by Rogallo.
The how of changing bindings still needs to be documented, but it's the same as with most of my other TUI applications, so if you look at how it's done in OldNews, for example, you should get the idea.
This command can be used to open a location from the command line. You can pass it either a URI for a Gemini capsule, or the path to a file in the local filesystem.
Talking of viewing files in the local filesystem... that's now supported too. This is something I wanted to build in from the start, as I feel it could be handy to anyone writing gemtext files prior to deployment. I sense there might be a couple of edge cases relating to this that I might still need to iron out, but mostly it seems to be working well.
At some point I'll probably also pull in textual-fspicker so that the user can browse for files to view, making it just a little easier to open a file in some cases.
So far, to connect to a Gemini capsule, it's been necessary to provide the full URI. That's kind of annoying. It had been deliberately left like this until I sorted the work to allow specifying local files, as I wasn't quite sure how it would all interact. Now that I've got that in place I could address this too. So whereas before you had to type gemini://davep.gemcities.com/ to get to my test capsule, now it's enough to enter davep.gemcities.com.
There is some guesswork going on in the background, with the resolution rules looking something like this:
Have I been given a URI that is obviously a Gemini URI?
If not, if it has no scheme, and it matches the name of a file in the filesystem, let's assume the user meant that.
If it's not a file in the filesystem, and it doesn't have a scheme, let's slap gemini:// on the front and see how we get on with that.
None of the above applied, yet it has a scheme: throw it at the operating system's URI resolution system.
In casual testing so far this is working out well.
I'm still having a blast working on this, and there's still a lot more to do. The TODO list is staying pretty constant in size at the moment because, as I knock an item off, I seem to keep finding new things I want to add or improve. I see this as a good thing.
I have a very busy AFK life for the next week or so, so I don't imagine too many updates during that period. Once things have settled again I want to try and tackle the two big issues of user input and client certificates. I'll be happy that Rogallo is getting close to generally usable when I know I can log in and water my plant in Astrobotany.
~/.config/rogallo/configuration.json on most systems. This and all the options within will eventually be documented, when I get round to creating the site to document Rogallo. ↩
It looks like I'm going to have a fairly interrupted work day today. I was woken up in the early hours of the morning by a pretty impressive storm. While most of the lightning was IC, it was almost constant for a good thirty minutes or so. Given it was still dark, it was an impressive show.
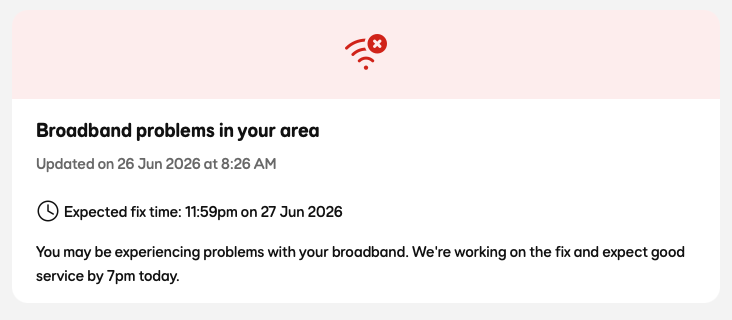
Around 08:00, it started up again. Some time between 08:00 and 08:30, I lost broadband. A quick check of the status page showed it wasn't just me...
That 19:00 expected fix time doesn't look so good for getting a lot of quality work done today. I would expect that to be an initial pessimistic estimate, but it still suggests it's likely not a straightforward issue.
You've got to be somewhat thankful for a couple of bars of 5G, an unlimited plan for mobile data, and a Mac-to-iPhone tethering setup...