So after the screw-up by Openreach and EE, where I was promised full fibre and then it never happened, I'd assumed that nothing was going to happen for quite some time. I was told that (likely) Openreach would contact me when they'd solved whatever the problem was, but I wasn't holding out much hope that it would be a swift turnaround.
Yesterday, however, I got an email from EE claiming that full fibre was available at my address. While sceptical about this, assuming it was just some marketing nonsense that wasn't paying attention to the details of where I live, I called them to check. I explained the problem, I had them read the notes on my account, I had them acknowledge all that had happened and they reassured me that, for real, no kidding, no nonsense, this was all gonna happen this time.
So... watch this space. I already have an installation date (it's next month) just from the order-planning call -- something which didn't happen the last time. Within the next few weeks, I will either finally be returning to streaming, and enjoying all the other benefits of full fibre, or I'll be writing yet another post about how EE and Openreach messed up.
After last weekend's attempt at making a couple of stotties, I thought I'd have another go. This time the aim was to try and get the classic shape, mostly by trying to ensure they were rounded and also flatter before going into the oven.
The dough post-rise:
Ready for the oven:
Fresh out of the oven:
Side view:
So... still viable bread. Still going to get eaten. But I think this is obviously another fail when it comes to the (lack of) thinness and the shape after they come out of the oven.
There will be another attempt. I'm going to keep trying this until I get it right!
It's been a wee while now since I stopped using GitHub Copilot and switched to doing everything locally (in a tool sense, not a model sense) with the Antigravity CLI, so I thought I'd jot down how it's been going. Simply put, it's been going well.
I've found the CLI itself easy enough to work with (I've not really attempted to use the GUI application), and the default model choice has done a lot of work for me on BlogMore without issue. I think it's fair to say that, at this point, I'm finding it far more consistent than I was finding Copilot+Claude.
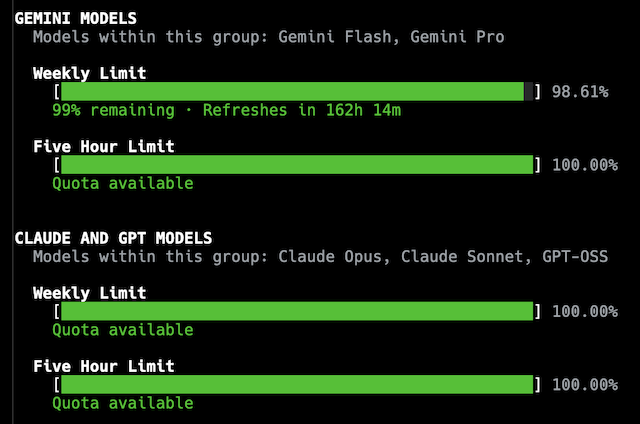
As for the initial confusion and concerns about quotas: I've found that that's calmed down, with me never obviously coming close to hitting my limit while working on any change to BlogMore. The worst I've seen is getting down to about 20% of the 5-hour rolling window, and even then that's been when I've pretty much finished the work I was doing.
The actual display of quotas has changed too, I noticed just this morning. Now, rather than showing progress bars per model, it's more like this:
While I suspect the weekly quota display will cause a smidge of anxiety to start with, mostly I appreciate that being added, and being so clear. Given the level of work I'm using this for, I can't see myself coming close to using it all up and having to wait. The quota does come with an explanation in the CLI too:
Within each group, models share a weekly limit and a 5-hour limit. Quota is consumed proportionally to the cost of the tokens. Thus, limits will last longer with shorter tasks or using more cost-effective models. The 5-hour limit smooths out aggregate demand to fairly distribute global capacity across all users, while your weekly limit is tied directly to your individual tier.
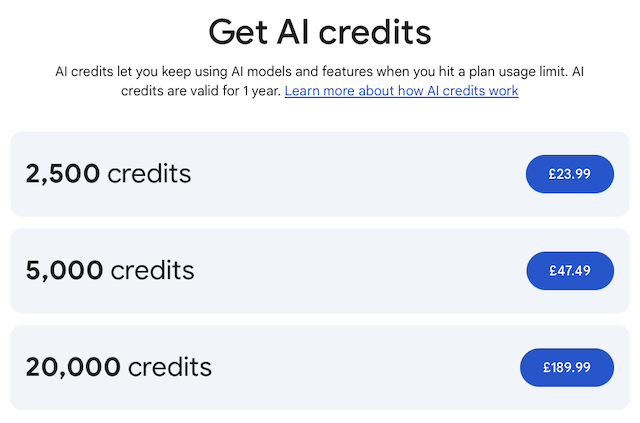
Digging a little deeper, I see there's a /credits command and, quite quickly, I can go from that to this in my browser:
I'm not sure exactly how much work 2,500 credits might represent, or what impact it would have or could have on the weekly quota; confusingly, if I follow the links from the CLI to see my usage, I see a message that says:
AI credits included with your plan have been replaced by product-based usage limits
So which is it? Do I have usage limits? Do I have a hard cap for a week? Can I extend it or not? Do I extend it using credits or not? I sense the messaging around this is all still a little mixed up. I do know that if I turn on credit fallback in /settings, I get a handy display of the credits I have left:
AI Credits: 1000
So this weirdly reads like I can and am using credits as a fallback to the quota, but also not.
Schrödinger’s Quota?
I'll dig around some more and see if I can find a definitive answer.
All that said: barring any changes that might upset things (which, let's be honest, is something that's highly likely given the state of the AI/agentic coding world), I think I'm happy with how this is going. For now, at least, BlogMore's primary development tool will carry on being Antigravity.
By pure coincidence, it's six years ago tomorrow that I finally, after years of running Emacs with a bright white background, moved to using a dark theme. It took a little bit of getting used to but eventually I got very comfortable with it, and since then have run everything I can in a dark mode too.
On occasion, in the last year or so, I've had this urge to move to something darker. Also, in part, it's an urge to change things up a little. I felt it was time for a refresh of how my Emacs looks. I've tried a few themes, but none have ever stuck. When trying them I've run into various issues:
It just didn't look nice at all
Too many other things I use in Emacs didn't get themed
It looked like there was going to be too much work to do to really theme things well
However, yesterday evening, after making an effort to simplify my mode line, I was determined to find a darker theme that I would be happy with. I think I finally managed!
I've settled on modus-vivendi from modus themes. Out of the box it felt right, and from what I can see in the documentation there's an amazing amount of customisation you can do. The key point there too is the documentation; there's so much of it, it's incredibly comprehensive.
For example: the default choice for the mode line is to have an unsubtle border around it -- presumably to create a good contrast. I found that far too distracting and was wondering what I could do about it. I didn't have to wonder long, the documentation addresses exactly that situation.
Another downside I ran into is that the colours that were showing in the mode line, when I switched to mood-line yesterday, were gone. I spent a short amount of time last night, and a good hour or so this morning, trying to wrangle mood-line into something I liked, but I just couldn't get anything sensible going. Eventually I cracked, fired up Antigravity, prompted it with:
I am using mood-line for my mode line -- see init.d/packages.d/melpa/mood-line.el and https://github.com/emacsmirror/mood-line
I am using https://protesilaos.com/emacs/modus-themes as my theme
I would like to have finer control over the parts of the mode line I've configured. For example, I'd like the buffer name to stand out in an informative colour, but one that is part of the modus theme's colour scheme.
Don't make changes yet, but help me understand how I should do this in a maintainable way.
and then spent about 20 minutes going back and forth, refining what I wanted; this got me a result I'm happy with from a visual point of view. I still need to fully review the code and the approach it took, but it isn't too far removed from what I'd been trying myself.
Overall I'm pleased with the result, and this is the longest I've stuck with a new theme (at this point I'm probably about 4 or 5 hours into working in it). I think that says something significant. I can see myself still wanting to tweak some aspects of it though. For example, the left-hand fringe doesn't feel quite right, in a way I can't quite put my finger on. While I want it to stand out from the main editing area, it feels... disconnected in some way. Also the background colour of the mode line still feels like it doesn't quite blend how I'd like.
Now to see if this lasts...
Seriously, just the once, but that happened. I took that as a sign from the Lisp gods that I was doing something sinful. ↩
Every so often I get the urge to change how Emacs looks. Ever since I finally fell to the dark side, my Emacs has stayed looking pretty much the same. I like how it looks, but I do keep having this urge to find a darker theme, and to also make things just a wee bit more minimal.
At one point I was very much about, and in favour of, having as much information as possible in the mode line. Eventually I realised I didn't use that much and tried to declutter somewhat, mostly cleaning up minor mode information with diminish. Even then though, I had this feeling that there was still more information in the mode line than I really needed.
So, just now, as an experiment, I've decided to start fairly clean. I've dropped powerline and instead decided to have a play with mood-line. Rather than use one of its pre-configured formats, I've had a go at rolling my own:
For any given buffer the mode line display is now:
The status of the buffer
The name of the buffer
The major mode of the buffer
The git status for what I'm working on
The cursor position
Honestly, I'm struggling to think of anything else I really need to see. Sure, I can imagine there's the odd minor mode I might need to know about, but generally I either have them enabled all the time anyway, or it's something so obvious that I know when it's not enabled.
I'm going to run with this for a while now and see how I feel. I can sense that I might want to tweak a couple of things (at the moment the left-hand side will move when I change the unsaved status of the buffer; on the right there's nothing that tells me that this file I'm editing right now is new to the repo and not part of it yet), but this basic configuration feels clean and right.
Meanwhile... the search for a theme that is darker and I actually prefer over the sanityinc-tomorrow themes continues. I fear this is going to be a lot harder.
Damn. Oh damn. My Reddit account is now old enough to buy beer1. O_o
While I probably have accounts somewhere that are older than this, that's still a pretty long time to have held an account somewhere and still be actively using it.
I remember I'd been reading Reddit for a couple of years before I finally made an account; I can't quite remember what prompted me to do that. In that time I've been more or less active there (although seldom one to post things or make comments -- normally I just consume and vote). From what I can tell that suggests I was starting to read Reddit within a year of it being launched.
I vaguely remember those old days. I remember all the conversation when it moved away from being developed in Lisp. I can't remember if I was visiting it around that time.
I do have the charter member badge because, back when gold was launched, I was reading the site a lot and it seemed sensible to support it at the time. I've long since let that subscription lapse. I see zero benefit in Reddit Premium.
For some time, a couple or so years back, when they killed off most third-party clients, I stopped using the site for a while. These days I have got back into the habit of reading it again. While I do occasionally check in on a handful of Lemmy subscriptions, and do keep thinking I should probably look into lobste.rs2, it's hard to break the habit of opening the Reddit app and scrolling for a wee while. I've yet to finally and fully replace it.
I should go look at some of my other longer-serving accounts on websites and services and see exactly which is my oldest one.
Another quick update to blogmore.el, again to fix an issue I've run into with the new frontmatter-handling code. This time it's to address an actual crash that could happen if a property was available but empty. For example, if a post had frontmatter that looked like this:
And I then went to use blogmore-add-tag, I'd get a crash saying:
Wrong type argument: sequencep, :null
The reason being that tags was being parsed with a value of :null, rather than (as before) having a value of nil (which of course meant I had a nice empty list to do things with). It was an easy enough fix.
At this point I think I've managed to shake out any serious issues with the proper YAML-parsing approach to frontmatter, as I've used it to write a handful of posts now.
A quick little update to blogmore.el to fix a couple of issues introduced by the new YAML-parsing approach to reading frontmatter; both pretty much stemming from how falsy values are handled.
Simply put, both boolean false values, and also empty values (something that could commonly happen with tags and series) would end up showing up in the frontmatter as null. This release handles that situation.
Also, under the hood, I cleaned up some repeated boilerplate related to how the cached dump calls to BlogMore took place. The code for categories, tags and series data was almost exactly the same, save for the actual name of the thing being dumped. So I turned it all into a macro:
(defmacroblogmore--cache-dump(dump-name)"Generate a function to get DUMP-NAME from BlogMore, with caching."(let((cache-name(intern(format"blogmore--current-%s-cache"dump-name)))(getter-name(intern(format"blogmore--current-%s"dump-name))))`(progn(defvar,cache-namenil,(format"Cache for the list of %s from existing posts."dump-name))(defun,getter-name(),(format"Get a list of %s from existing posts."dump-name)(or,cache-name(setq,cache-name(blogmore--list-of,(symbol-namedump-name))))))))
and now the defvar that creates the variable that holds the cache, and the defun that creates the getter function for the data, are reduced to this for all three collections of values:
Sure, I probably could have done all of this in a single global, a central getter function, and a hash table, but the macro approach feels so much more elegant, and more... lispy.
As normally happens, I then went on to tag the release on GitHub, followed by writing the blog post to announce the new version. While doing this, despite the fact that it wasn't necessary given the nature of the change, I decided to update BlogMore in my blog's repository. That's when things started to look odd.
I did the usual make
update but nothing new appeared. Now, it's not unheard of that I do this and no new version of BlogMore appears. Often I do it a couple more times and it's fine. So I kept trying every minute or two and still nothing. So I checked back on PyPI. Sure enough, a search showed that it had updated:
(The 16 minutes being about the time since I'd made the release), but when I clicked through it was showing the last version from a couple of days ago. Even when I looked at the release history it was saying the latest version was the previous version:
Odd.
At this point, depending on how I searched and where I went, I'd either see that my latest upload wasn't available, or I'd get a 500 error.
Leaving aside the whole issue of having an account on Twitter these days anyway, I felt it wasn't that useful to point people at a resource that seems to have never been updated, so I did raise an issue about that.
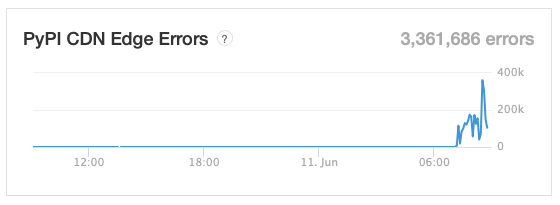
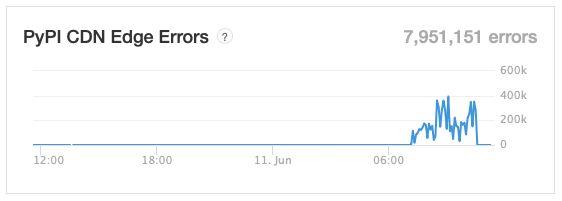
Digging around the status page at some point, despite the fact that the main display was green all the way, I did see a rise in "PyPI CDN Edge Errors". I'm not a web guy, I'm not an infrastructure guy, so I'm not really sure what this would mean, but it sounds like it's not a good thing.
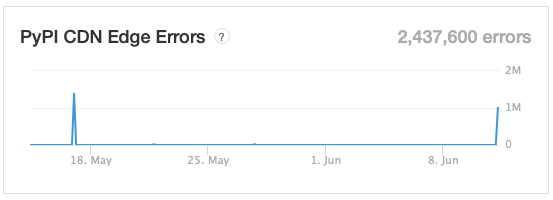
Opening the graph to look longer term, it did seem today was a spike, with another spike quite some time ago.
At this point I left it a while, not announcing the new version of BlogMore. I came back some time later and, finally, I could see 2.43.0 was showing! Also, this seemed to coincide with the above graph calming down again.
Seeing this I went to upgrade BlogMore in my blog's repo/venv and this time it all worked.
Yay!
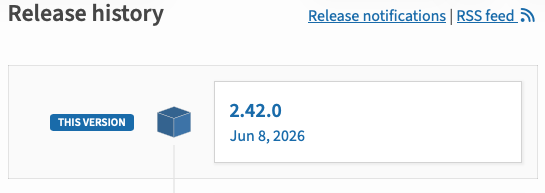
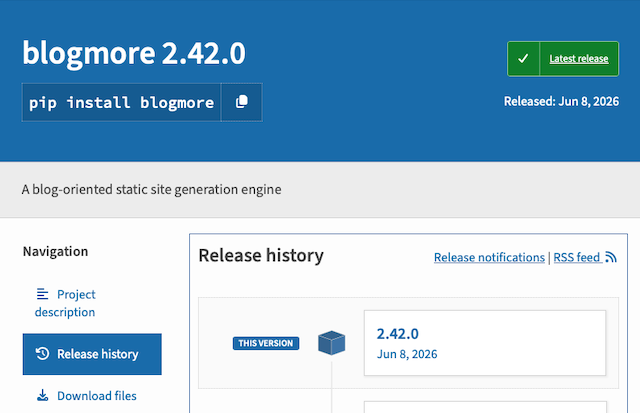
At that point I left it alone and went about my work day. However, I don't think whatever is going on is over. Despite the fact that it was showing BlogMore as being v2.43.0 earlier today, once things were settled, I just checked again as I started to write this and:
The search index on PyPI shows it as having been updated about 8 hours ago (as I write this), but the page itself shows that the latest version is from 2 days ago. At least installing it gives me 2.43.0:
After recently adding Mermaid and maths support to BlogMore, I got to thinking that it now has connections with a handful of third-party resources. While almost all of them are optional (only FontAwesome comes close to being a hard requirement), it does mean that there are resources the user doesn't directly supply or control, and for which the URLs are hard-coded in the source for BlogMore.
Of course, it's not an all-or-nothing setting; you can just set one of the values. So if you wanted to override the force_graph value it's enough to do:
Hopefully this adds some useful flexibility. As well as giving the option to use a different version of a resource, it also allows you to host your own copy and refer to that instead. Heck, it would even allow totally replacing a library with a different one that has the same API, should you ever find yourself in that situation.