I don't know if it's just that GitHub Copilot is having a bad time at the moment, or if I've run into a genuine problem, but all isn't well today. After merging last night's result I kicked off another request related to a group of changes I want to make to BlogMore. It's a little involved, and it did take it a wee while to work on, but mostly it got the work done.
Again, as I said in the earlier post, I won't get into the detail of these changes yet, but they're fairly extensive and do include some breaking changes, so it's probably going to take a wee while to have it all come together. Claude's first shot at the latest change was almost there but with the glaring bug that it did all the work but didn't actually add the part that reads the configuration file settings and uses them (yeah, that's a good one, isn't it?).
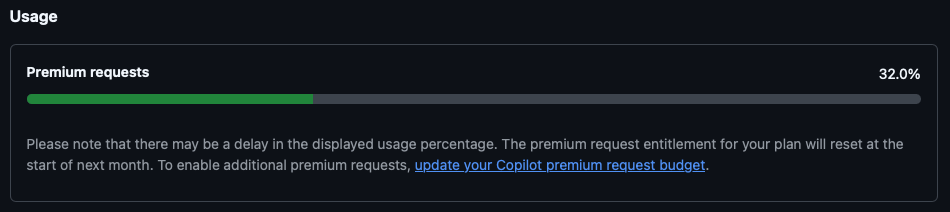
This surprised me. After the past few weeks I've had sessions where I've requested it do things way more frequently than this morning. I'm also nowhere near out of premium requests either:
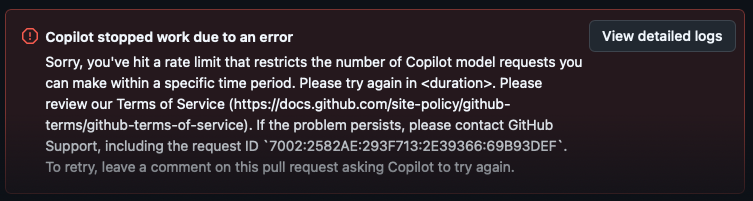
While the error, as shown, might be valid and might be down to my actions, it's massively unhelpful and doesn't really explain what I did to cause this or even how I can remedy it. This is made all the more frustrating by the fact that it seems to be saying I need to wait <duration> to try again. Yes, literally a placeholder of <duration>. O_o
One thing is for sure: this is another useful experiment in the current experiment. It's worth having the experience of having the tool screw with the flow. It doesn't come as a surprise, but it's a good reminder that using an agent that is hosted by someone else means you fully rely on their ability to keep it working, the whims of their API limits, and perhaps even your ability to pay.
Last night, while tinkering with another BlogMorefeature request, I ran into the sudden rate limit issue again. As before, there was no warning, there was no indication I was getting close to any sort of limit, and the <duration> I was supposed to wait to let things cool down was given as <duration> rather than an actual value.
So this time I decided to actually drop a ticket on GitHub support. Around 12 hours later they got back to me:
Thanks for writing in to GitHub Support!
I completely understand your frustration with hitting rate limits.
As usage continues to grow on Copilot — particularly with our latest models — we've made deliberate adjustments to our rate limiting to protect platform stability and ensure a reliable experience for all users. As part of this work, we corrected an issue where rate limits were not being consistently enforced across all models. You may notice increased rate limiting as these changes take effect.
Our goal is always that Copilot remains a great experience, and you are not disrupted in your work. If you encounter a rate limit, we recommend switching to a different model, using Auto mode. We're also working on improvements that will give you better visibility into your usage so you're never caught off guard.
We appreciate your patience as we roll out these changes.
So, in other words: expect to be rate limited more on this product we're trying to get everyone hooked on and trying to get everyone to subscribe to.
Neat.
I especially like this part:
We're also working on improvements that will give you better visibility into your usage so you're never caught off guard.
You know, if it were me, if I wanted to build up and keep goodwill for my product, I'd probably do that part first and communicate about it earlier rather than later.
I guess this is why I don't hold the sort of position that gets to make those decisions.
I guess it was inevitable1, but yesterday GitHub announced a new opt-out approach to learning from people's interactions with Copilot. I don't have anything novel or insightful to say on this switch, and I'm sure folk with better-informed opinions have already rushed out posts and articles about this, but I did want to jot down just how curious I am to see this roll out.
For starters: for me this feels like one of those things that will get a lot of backlash, and in a day or so GitHub will say they're pausing rolling this out while they reevaluate this approach2. Then, eventually, they roll it out anyway after a "period of consultation with the community". That sort of thing.
I've not read further this morning, but before going to bed last night it wasn't a happy time in the comments section of the FAQ. I can also see why some would be cynical about this change, given the tone of some of the questions and answers in that FAQ. I'll hand it to them: they're pretty candid and honest with the FAQs, but kinda yikes too.
Here's the key thing I'm curious about, and which I'll be thinking about and watching for movement on in the next few days: all the talk here seems to be about protecting the privacy of the proprietary code of businesses3. That... is understandable, from a business point of view, from a commercial adoption point of view, from a "we want all software engineering departments to use Copilot" point of view. But how the heck are they really going to manage that?
We do not train on the contents from any paid organization’s repos, regardless of whether a user is working in that repo with a Copilot Free, Pro, or Pro+ subscription. If a user’s GitHub account is a member of or outside collaborator with a paid organization, we exclude their interaction data from model training.
This seems somewhat unclear to me. Let's walk this one through for a moment: my GitHub accountis a member of a "paid organisation". My account is also my account, for my personal code, I've had it a long time and it's filled with a lot of FOSS repos and I keep adding more. So which scenario is the right one here?
Because I'm currently a member of at least one "paid organisation" I'm always opted-out of this training no matter how the opt in/out setting is set and no matter what code I work on?
Because I'm currently a member of at least one "paid organisation" I can opt in when working on code that is from a repository which is mine, but I'm opted out when I'm working on code from a repository belonging to the paid organisation?
I think it reads like it's #1. But then that seems rather odd to me because, if I go and look at my settings right now, I can elect to opt in/out of this training system. If the correct reading is #1 why not just disable that setting altogether and say below it that I'm opted-out because I'm part of a paid organisation?
Which sort of suggests we should perhaps read it as #2? If that, that raises all sorts of questions. How would Copilot know I'm working on code from such a repository? Sure, it's not impossible to infer if I am working within the context of a given repository, doing some fun stuff to work out the origin and so on, but it feels messy. It also feels like a scenario that could end up being incredibly leaky. It really would not be difficult to run into a scenario where I'm working on some non-Free code but in an environment where the licence isn't clear, or where it appears that the licence4 would permit such training.
ℹ️ Note
Editing to add: there is even a comment where it is acknowledged that someone could be working in such a way that it's impossible to know the provenance of the code: "Copilot ... can even work when you are not connected to any repo."
Or... perhaps there's a #3, or a #4, or so on, that I've not even considered yet. The fact that software engineering departments suddenly have to start thinking about this issue (yes, I know, it's been a background issue for a while but this really drags it out into the open) is going to make for a few interesting weeks, assuming people care about where their code ends up.
Who knows. Perhaps, in some strange way, this is how all software ends up being Free.
And I think a bit of me is surprised that they weren't just doing it anyway. ↩
This isn't a prediction, I'm just saying it feels like that sort of announcement. ↩
It's not that simple, but to save getting into the deep detail... ↩
I'm using licence here as shorthand for a lot of things to consider relating to who should have access to the code and how. ↩
Well, it's here: GitHub's tool to let you see how much better off you're going to be under the new Copilot billing system that comes in next month. It's... something.
But let's set the background first. I'm here (in Copilot usage space) as an observer, spending time on an experiment that started with the free pro tier and then transitioned into the "okay, I'll play along for $10 a month, the tool I'm building is fun to work on and is useful to me" phase. I doubted it would last forever -- the price was obviously too good to be true for too long -- but I wasn't expecting it to collapse quite so soon and in quite such a spectacular way.
When GitHub announced the move to usage-based billing I was curious to see if I'd be better off or worse off. It was hard to call really. My use of Copilot is sporadic, and as BlogMore has started to settle down and reach a state approaching feature-saturation the need to do heavy work on it has reduced. I did use it a fair bit last month, but that was more in tinkering and experimenting mode rather than full development mode1, so it's probably a good measure.
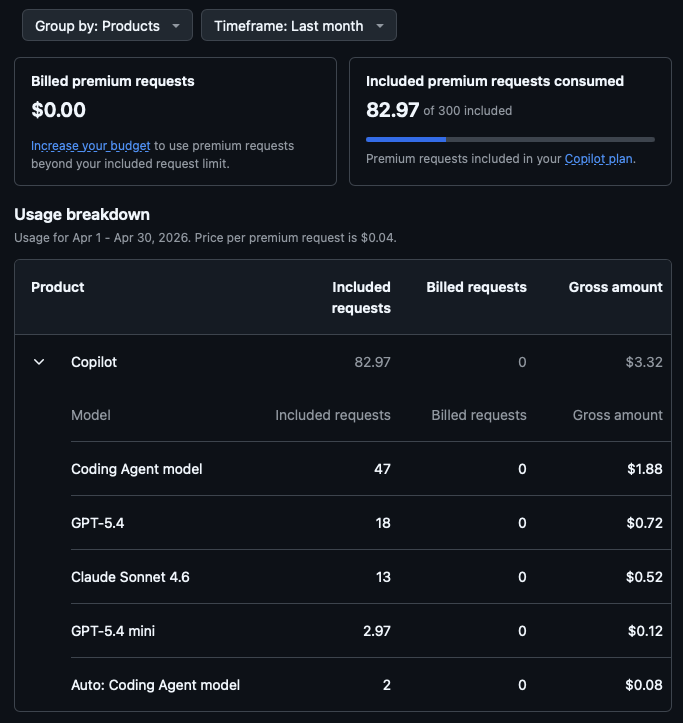
Checking the details on GitHub, it looks like I used a touch under 1/3 of my premium requests.
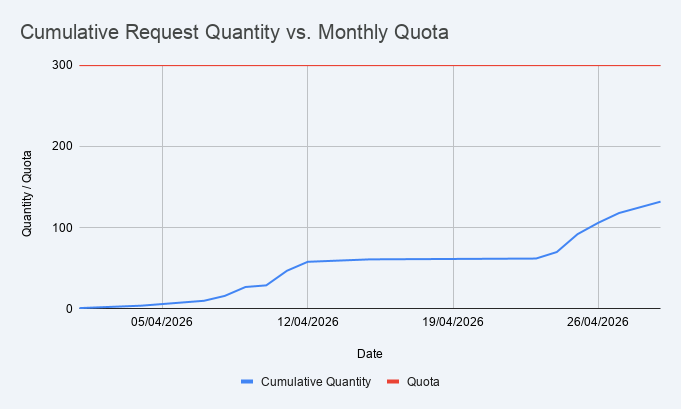
It also looks like the usage came in a couple of bursts lasting a few days, with a pretty flat period in the middle of the month.
So, technically, GitHub won. I paid them $10 for 300 premium requests, I left a touch over 2/3 unused. I think it's fair to suggest that I'm a pretty lightweight user, even when I have a project under active development.
This is where the new usage-based preview tool comes in. Launched yesterday, it lets you take your existing usage stats and see how much it would have really cost you.
The app itself comes over as being hastily spat out with an agent and little communication between responsible teams. You'd think you just press a button when viewing some historical usage figures and get a display that shows you what it would cost under the new approach.
You'd think.
Nope. First you generate your report for a particular month. Then have to ask for it to be emailed to you as a CSV!
Even that part isn't super reliable. When I tried it last night it took a wee while to turn up, and that was after about 10 attempts where I got an error message saying it couldn't generate the report. This morning I tried again and I've yet to see the email, 30 minutes later2.
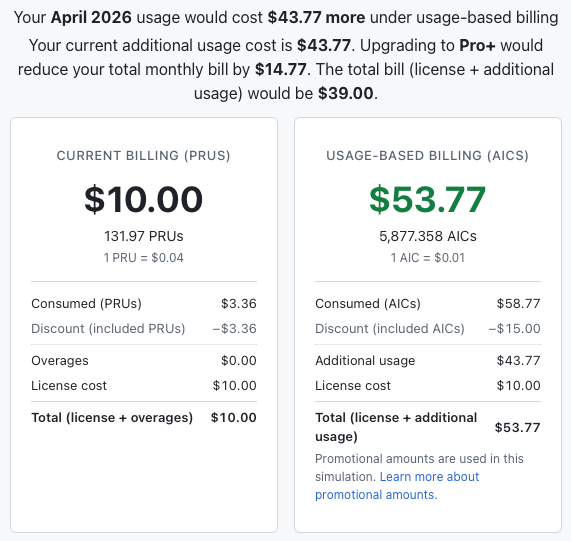
Having done that you click through to another page/app where you have to upload the CSV, to GitHub, that GitHub just sent you in an email. Brilliant. It then gives you the good news.
So what is my 1/3 use of the premium request allowance going to save me under the new approach to billing?
Amazing. I especially like the part where they spin it as: if I spent $39/month with them I would save money!
Watching this journey has been wild. The free Pro as a taster to get me onto $10/month I can go with, that's fair enough. For the longest time I never even paid it any attention. But watching GitHub give it to so many people, and especially so many students, and then watching them do shocked Pikachu when it cost them an arm and a leg and probably caused the degradation of the performance of their systems... who could possibly have seen this coming? Impossible to predict.
Back when I first wrote about my initial impressions of working with Copilot I wondered in the conclusion if I'd transition to a paying version of Copilot. I obviously did. At $10/month it was a very affordable tinker toy that gave me a new dimension to the hobby side of my love of creating things with code. But the prospect of paying $39/month for something in the region of 1/3 of requests that I had before: nah, I'm not into that.
It looks like this month will be the last month I keep a Copilot subscription. BlogMore will carry on being developed, I'll probably transition to leaning on Gemini CLI more (as I have been the last week anyway), and also start to get my hands dirty with the code more too.
This feels like one of the early signs of the bait and switch that the AI suppliers have been building up all along. Experimenting and better understanding how and why people use these tools has been seriously useful, and I can't help but feel that I accidentally started at just the right moment. Watching this happen, with actual experience of what's going on, is very educational. It's going to be super interesting to see if this same stunt gets pulled on a bigger scale, with all the companies that uncritically embraced AI at every level of their organisation.
It's going to be especially interesting to watch the AI leaders in those companies to see how they spin this, if and when the real costs are more widely applied.
Is my recollection. I should probably review the ChangeLog and see what I actually did add in April. ↩
Now that we're near the end of the free or cheap GitHub Copilot party, I thought it might be interesting to look at how much BlogMore has "cost" me to build, and what it would have cost under the proposed new pricing structure that is coming in next month. While I've looked at the comparison for last month, I've not looked at the whole period I've been seriously using it.
So, for this review, I'm looking at all the data I can pull out of GitHub for the months of February, March, April and May of this year. Development of BlogMore started back in February and, while it hasn't been 100% the cause of my use of Copilot premium requests, it's been almost all of it. For the purposes of this review I'm just going to take the approach that all I worked on was BlogMore.
Remember that, even when I had free access, I had a maximum of 300 premium requests per month. Once I lost free access I had the same number of requests for $10 a month.
Here's how those months broke down:
Month
Paid
Premium Requests
%age
Predicted Price
February
$0.00
249
83%
$21.67
March
$10.00
140
47%
$56.38
April
$10.00
132
44%
$53.77
May
$10.00
34
11%
$53.69
Total:
$30.00
555
46%
$185.51
So, give or take, something that I've actually spent $30.00 on could have, at best, cost me $185.51. That's assuming that the "cost" of the models I was using stays the same. You can see that the costs have risen already in that the predicted price from February, where I used 83% of my premium requests, is a touch under half the cost for this month, where I've used just 11%. From what I can see in the raw data, it's down to some models suddenly being considered more expensive (perhaps I was doing something that just consumed more tokens, I'm not 100% sure if I'm honest, but I don't recall anything that seemed like harder work).
Who knows what the real costs will be come June.
Now, technically, the actual cost under the new regime could or should be $156, because it would be 4 lots of the $39.00/month plan, which would better cover that use1. Again though, that's assuming the actual cost of using whatever models remains pretty stable. It also assumes that I'd want to spend that much each month, and that I would be correctly anticipating that I'd need that much.
Also, this isn't even the total cost of getting this project done. As I've written recently: I've been using Gemini CLI more this month, and while the usage there is a flat cost, until now, that's changing too.
Now, of course, these aren't the only games in town. I could "go to the source" and just get a sub for Claude Code or something, and as Tim pointed out over in the Fediverse, something like Cursor does a lot of this and is just $20/month. Which all sounds fine, but what happens when those fleeing GitHub Copilot or Gemini CLI/Antigravity head over to something like Cursor? Is it sensible to expect the pricing to stay the same2?
I guess, at this point, I'm just mulling over the same issue time and again, but from different angles. It does seem clear to me, though, that in less than 4 months, in my experiment of "what happens if I use agents to develop a Free Software tool I want?", the market has gone from being entirely reasonable to pretty much unjustifiable from a price point of view.
It looks like some of those friendships have lasted a while.
Some saw the opportunity to create content out of the situation.
Some have figured out that the thing that costs money, costs money.
Someone used up half their monthly allowance on just 8 requests.
Although, of course, there's always someone who has to do it better.
To be fair though, at least one person loves the new system.
As for my subscription, which came about after I initially experimented with free access to the tool, I've not actually cancelled yet, but I can't see me making use of it much more. I might try a couple of prompts with it, along the lines of what I was doing while working on BlogMore, just to get a feel for how different the usage is now.
Meanwhile, though, I've found that I'm getting on a lot better with Antigravity and getting the bits done I want to do. I suspect this is how I'll keep tinkering with BlogMore, until Google come to their senses anyway.