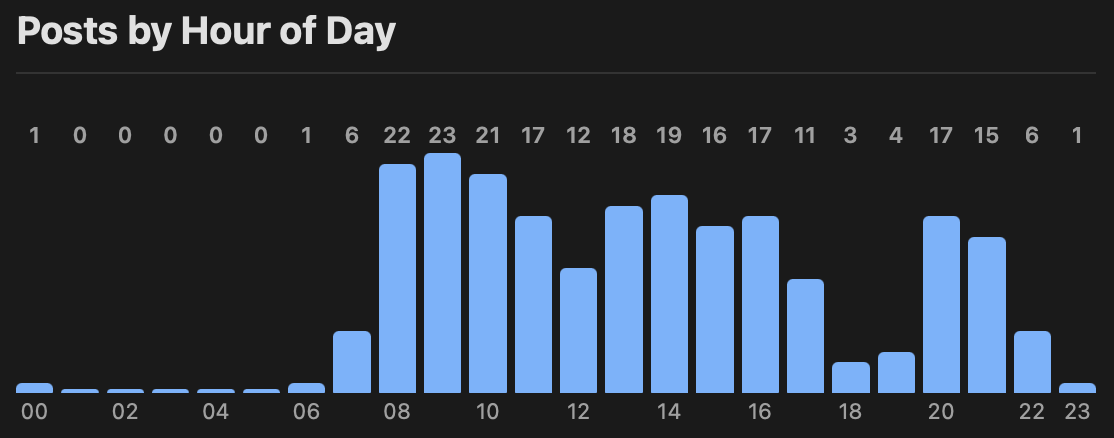
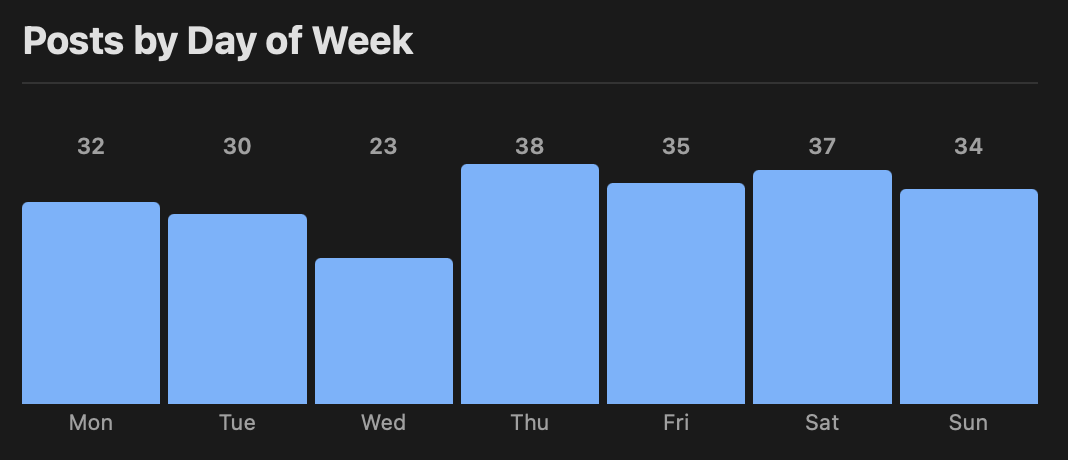
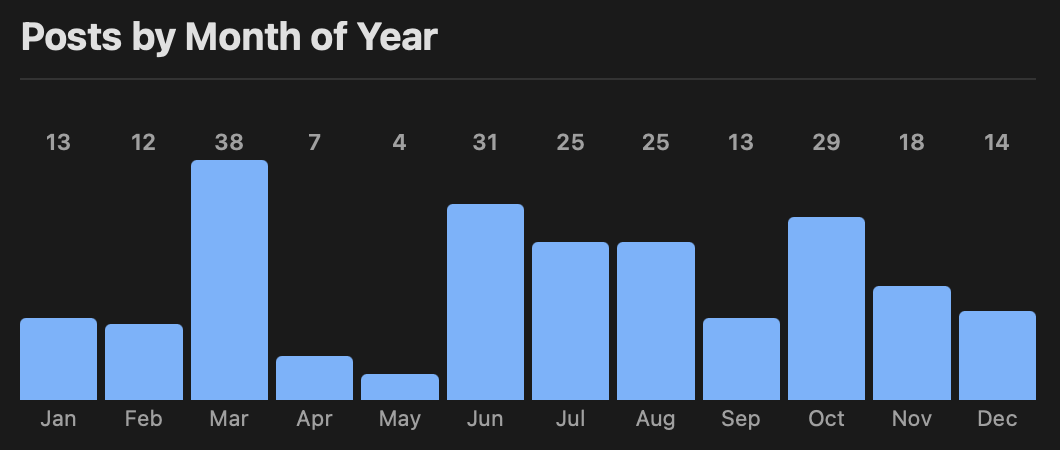
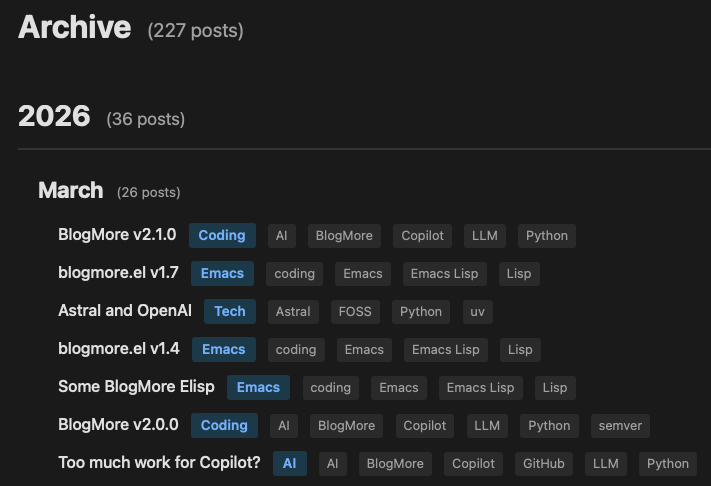
Recently I've been thinking that it would be interesting to get to know a little about the Model Context Protocol and see what it's about and get a feel for how useful it might be, if at all, for anything I do.
As always happens when I want to try out something new, I reached for a problem I know well so I don't have to get bogged down in solving the problem itself. As almost always happens, I decided I should base it around Norton Guides.
Part of the point of MCP seems to be providing an interface over sources of data and actions, that an LLM might not otherwise be able to cope with, and so it sounded to me like providing a bridge to the content of Norton Guide files would be a perfect test. Of course, this isn't the first time I've bridged LLMs and NG files, but this is obviously intended to be a more generic solution than throwing a Markdown file at NotebookLM.
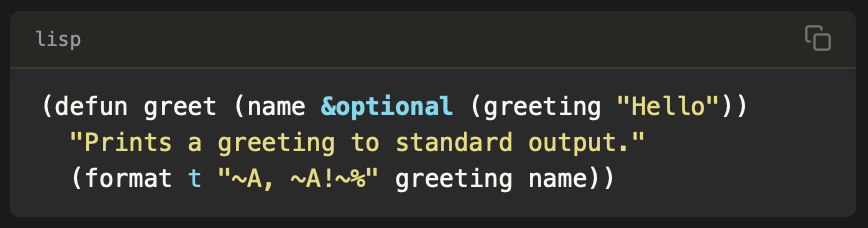
Earlier this afternoon I sat down and did some reading, and then decided to throw the problem at GitHub Copilot. I told it I wanted to use my NGDB library as the core of the tool, and that it should wrap it up with FastMCP. The initial result was... a bit of a mess. It sort of worked, sort of, but it also seemed to try and put together a project that mostly looked how my Python repos look, but with some bits just wrong.
I did some cleaning up, did some testing, did some tweaking, and eventually I had something working.

So far I've given the code a fairly quick read over, and I can see what it's doing and how it's going about this. This approach obviously has the disadvantage that I didn't hand-write it so there's still a lot to read to really appreciate what's going on; on the other hand, it does have the advantage that it's implemented a tool based on my library so I know what to expect it to be doing.
There will be more code reading happening, and I also intend to look to tidy up the code more and perhaps hand-add some more features.

I very much doubt that this particular MCP server is going to be any use to anyone, but as a proof of concept it works well for me. If I were in a position of needing to build something genuinely useful, I now have a start and a vague idea.

On the other hand: once again, as with other projects I've done related to Norton Guides, this is a tool that helps keep the content available and accessible; that alone is one reason for me to tidy this up and move it towards v1.0.0 and keep it maintained.
If you fancy having a play, some (currently Copilot-generated) documentation can be found on the server's dedicated site. When I get a bit more time I'm going to flesh this out.