As I've written about a few times in the last week or so, the journey with AI-based coding tools has hit an interesting time when it comes to prices, quotas, usage, availability and all that. Having come into all of this via a place where it was a flat fee, and where I didn't really need to think about input tokens and output tokens and so on, I'm pretty ignorant of what that all means in terms of scale. If I'm looking at a new tool and I see prices and/or quotas for in/out tokens, it means nothing to me. I can't relate to it. I've never had to care about it.
While using Gemini CLI to quickly make a change to BlogMore this morning, I was reminded that at the end of a session it does tell me this:
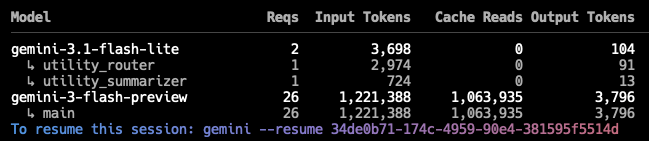
Seeing that got me thinking: is there a way to get the total usage for all of my sessions, or at least the sessions that have still been retained (I'm guessing they expire after a wee while)? After a little bit of searching I found ccusage. That looked exactly like the sort of thing I was after.
Now, this is only going to be good for Gemini (it says it supports Copilot too, but it seems to be failing to find any Copilot sessions), but it should give me a feel for what my token usage looks like.
I work on BlogMore on two different machines: the MacBook Air and also a Mac Mini I have in my office. Here's all of the available token usage data I can get out of the Air:
| Date | Input | Output | Cache Read | Total Tokens | Cost (USD) |
|---|---|---|---|---|---|
| 2026-04-29 | 235,238 | 20,282 | 773,642 | 1,032,608 | $0.23 |
| 2026-05-01 | 315,001 | 3,181 | 447,556 | 768,532 | $0.20 |
| 2026-05-02 | 2,621,628 | 52,290 | 18,260,597 | 20,955,447 | $2.44 |
| 2026-05-03 | 3,627,846 | 30,538 | 11,819,279 | 15,509,213 | $5.74 |
| 2026-05-04 | 869,829 | 49,163 | 2,721,074 | 3,656,649 | $0.77 |
| 2026-05-09 | 2,287,760 | 50,081 | 9,973,764 | 12,327,819 | $1.84 |
| 2026-05-10 | 1,019,550 | 34,556 | 8,061,897 | 9,125,838 | $1.05 |
| 2026-05-11 | 1,112,123 | 35,610 | 10,523,348 | 11,689,576 | $1.24 |
| 2026-05-13 | 1,506,513 | 41,802 | 7,561,168 | 9,124,651 | $2.88 |
| 2026-05-15 | 123,161 | 3,155 | 587,248 | 716,813 | $0.11 |
| 2026-05-16 | 111,334 | 14,836 | 519,161 | 646,275 | $0.13 |
| 2026-05-17 | 940,485 | 36,171 | 7,682,314 | 8,706,034 | $1.41 |
| 2026-05-18 | 67,033 | 1,357 | 205,921 | 275,707 | $0.05 |
| 2026-05-21 | 60,904 | 1,182 | 119,055 | 184,117 | $0.05 |
| Total | 14,898,405 | 374,204 | 79,256,024 | 94,719,279 | $18.13 |
And also the same for the Mac Mini (which gets used less frequently for this sort of thing):
| Date | Input | Output | Cache Read | Total Tokens | Cost (USD) |
|---|---|---|---|---|---|
| 2026-05-04 | 212,178 | 31,631 | 2,128,074 | 2,389,927 | $0.36 |
| 2026-05-05 | 1,108,903 | 31,997 | 6,222,868 | 7,374,732 | $1.13 |
| 2026-05-08 | 30,899 | 1,194 | 64,074 | 98,146 | $0.03 |
| 2026-05-11 | 1,339,333 | 27,399 | 8,074,904 | 9,459,253 | $1.21 |
| 2026-05-12 | 952,057 | 53,023 | 12,751,539 | 13,838,943 | $1.52 |
| 2026-05-18 | 166,875 | 4,774 | 651,417 | 827,746 | $0.22 |
| 2026-05-19 | 449,087 | 23,976 | 3,236,324 | 3,721,558 | $0.54 |
| 2026-05-22 | 335,151 | 10,012 | 1,919,815 | 2,272,553 | $0.32 |
| Total | 4,594,483 | 184,006 | 35,049,015 | 39,982,858 | $5.33 |
In both cases I've removed a couple of columns to make the tables fit better. The first was the model name (varying between gemini-3-flash-preview and gemini-3.1-pro-preview), the second was Cache Create (which was always 0 all the way down).
From what I can see, it would appear that these two tables do cover my increasing use of Gemini CLI for doing work on BlogMore (the first intensive use being back around the 5th of this month, if I recall correctly). So this would seem to be a reasonably informative way to view things.
All of which is to say, over a roughly three week period, while getting things done, I've used getting on for 20,000,000 input tokens, and around 600,000 output tokens (presumably I do also need to be keeping the 114,300,000 cache read tokens in mind too). With this in mind I might now be able to make more sense of the pricing I see for various tools.

