At the moment I'm working on a linting command for BlogMore. Having given up on Copilot/Claude for this, I've been having quite a bit of success with Gemini CLI. But while doing this, I've noticed some odd things with it. It does have this habit of cargo-culting some changes, or just rewriting code that doesn't need it.
For example, the tests for the new linting tool: it keeps adding import
pytest near the top of the test file despite the fact that pytest doesn't get used anywhere in the code. Every time, I'll remove it, every time it adds more tests, it'll add it back.
Another thing I've noticed is it seems to be obsessed with adding indentation to empty lines. So, if you've got a line of code indented 8 spaces, then an empty line, then another line of code indented 8 spaces, it'll add 8 spaces on that empty line. That sort of thing annoys the hell out of me1.
But the worst thing I just ran into was this. It had written this bit of code:
def lint_site(site_config: SiteConfig) -> int:
"""Convenience function to run the linter.
Args:
site_config: The site configuration.
Returns:
0 if no errors, 1 if errors were found.
"""
linter = Linter(site_config)
return linter.lint()
On the surface this seems fine: a function that hides just a little bit of detail while providing a simple function interface to a feature. But that use of a variable to essentially "discard" it the next line... nah. I dislike that sort of thing. The code can be just a little more elegant. So seeing this I edited it to be (removing the docstring for the purposes of this post):
def lint_site(site_config: SiteConfig) -> int:
return Linter(site_config).lint()
Nice and tidy.
I then had Gemini work on something else in the linting code. What did I see towards the end of the diff? This!
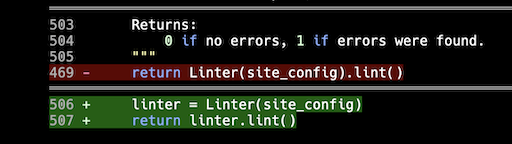
Sneaky little shit!
Now, sure, the idea is you review all changes before you run with them, but knowing that it's likely that any given change might rewrite parts of the code that aren't related to the problem at hand adds a lot more overhead, and I wonder how often people using these tools even bother.
I've seen some IDEs do that on purpose too; I've got Emacs configured to strip that out on save. ↩