After releasing blogmore.el v2.6 this morning, I noticed something about the post: the text that was marked up with <kbd> wasn't really standing out as keys. In blog posts, as in documentation, if I mention the name of a key, I like to mark it up with <kbd>. Ideally, with such markup, the styling of the page it's being used on will make it clear that it's supposed to be read as a key.
I've never put any such styling into the default styles made available in BlogMore.
So here we are with BlogMore v2.9.0, now with a bit of markup, and theme support, for keys marked up with <kbd>. So now, hopefully, if I say you should press Ctrl+F4 to make this blog look better, those keys should stand out a little better than they used to.
There's no question that the experiment that is BlogMore has resulted in me blogging more. Although my previous setup wasn't exactly all friction, there's something about "owning" most of the tools and really knowing how they work, and being able to quickly modify them so they work "just so", that makes me more inclined to quickly write something up.
I can see this if I look at the numbers in the archive for this blog. In March alone I wrote 43 posts; that's more than I wrote in any whole year, other than 2023. While I suspect this will start to calm down as work on BlogMore and blogmore.el settles down, I sense I'll be writing a bit more often for some time to come.
Then I realised I had a problem in blogmore.el. It assumed that the Markdown file for a new post (blogmore-new) would always be created in a subdirectory named after the year, underneath the defined posts directory. Until today that was the case1, but now I wanted it to work differently.
So this is why I'm making a second release in one day: I added the ability to configure the subdirectory where a new post is created. I've changed the default now so that it assumes the user wants the subdirectory to be YYYY/MM/DD (because more granular feels like the right default). In my case I don't want that, I just want YYYY/MM, but now I can configure that. The value that is set is a function that returns the name of the subdirectory, so in the case of my blog I have it as:
(lambda()(format-time-string"%Y/%m/"))
On the other hand, for my photoblog I want the full date as a subdirectory so I can leave it as the default. The whole use-package for blogmore now looks like:
(use-packageblogmore:ensuret:defert:vc(:url"https://github.com/davep/blogmore.el":rev:newest):init(add-hook'blogmore-new-post-hook#'end-it)(blogmore-work-on"blog.davep.org"):custom(blogmore-blogs'(("blog.davep.org";; Root directory for posts."~/write/davep.github.com/content/posts/";; Subdirectory for new posts, relative to the root.(lambda()(format-time-string"%Y/%m/")))("seen-by.davep.dev";; Root directory for posts."~/write/seen-by/content/posts/"))):bind("<f12> b".blogmore))
Technically this is a breaking change because it bumps the meaning of each "position" in the values within blogmore-blogs. However, in my case, because I was only ever defining the blog name and the top-level directory for the posts (both mandatory), this didn't break anything; I also strongly suspect nobody else is using this so I very much doubt I'm messing with someone else's setup2. If I have I apologise; do let me know.
Anyway, all of this goes to explain why the heck I made two releases of the same package back to back in the same day. This is what happens when my namesake is having fun outside and so I just want to sit on the sofa, hack on some code, and watch the chaos in the garden.
For my blog, which again shows that blogmore.el started as a quick hack for getting work done on my blog, but I also want to make it as configurable as possible. ↩
Even if someone else is using this I would suspect they hadn't configured anything more than I have. ↩
Like most people, I imagine, I first ran into transient when first using Magit. I took to it pretty quickly and it's always made sense to me as a user interface. But... I've never used it for any code I've ever written.
I think, incorrectly, I'd half assumed it was going to be some faff to set up, and of course for a good while it wasn't part of Emacs anyway. Given this, I'd always had it filed under the heading "that's so neat I'll give it a go one day but not at the moment".
Meanwhile... ever since I did the last big revamp of my Emacs configuration, I found myself leaning into a command binding approach that does the whole prefix-letter-letter thing. For reasons I can't actually remember I fell into the habit of using F121 as my chosen prefix key. As such, over the past 10 or so years (since I greatly overhauled my Emacs setup), I've got into setting up bindings for commands that follow this prefix convention.
So when I created blogmore.el I set up the commands following this pattern.
(use-packageblogmore:ensuret:defert:vc(:url"https://github.com/davep/blogmore.el":rev:newest):init(add-hook'blogmore-new-post-hook#'end-it)(blogmore-work-on"blog.davep.org"):custom(blogmore-blogs'(("blog.davep.org""~/write/davep.github.com/content/posts/")("seen-by.davep.dev""~/write/seen-by/content/posts/"))):bind("<f12> b b".blogmore-work-on)("<f12> b n".blogmore-new)("<f12> b e".blogmore-edit)("<f12> b d".blogmore-toggle-draft)("<f12> b s c".blogmore-set-category)("<f12> b a t".blogmore-add-tag)("<f12> b u d".blogmore-update-date)("<f12> b u m".blogmore-update-modified)("<f12> b l p".blogmore-link-post)("<f12> b l c".blogmore-link-category)("<f12> b l t".blogmore-link-tag))
It works well, it makes it nice and easy to remember the bindings, etc. Nobody needs me to sell them on the merits of this approach.
Then I got to thinking last night: why am I setting up all those bindings when I could probably do it all via a transient? So that was the moment to actually RTFM and get it going. The first version was incredibly quick to get up and running and I was kicking myself that I'd taken so long to actually look at the package properly.
This morning I've worked on it a little more and the final form is still pretty straightforward.
(transient-define-prefixblogmore()"Show a transient for BlogMore commands."[:description(lambda()(format"BlogMore: %s\n"(if(blogmore--chosen-blog-sans-error)(blogmore--blog-title)"No blog selected")))["Blog"("b""Select blog"blogmore-work-on)]["Post"("n""New post"blogmore-new:inapt-if-notblogmore--chosen-blog-sans-error)("e""Edit post"blogmore-edit:inapt-if-notblogmore--chosen-blog-sans-error)("d""Toggle draft status"blogmore-toggle-draft:inapt-if-notblogmore--blog-post-p)("c""Set post category"blogmore-set-category:inapt-if-notblogmore--blog-post-p)("t""Add tag"blogmore-add-tag:inapt-if-notblogmore--blog-post-p)("u d""Update date"blogmore-update-date:inapt-if-notblogmore--blog-post-p)("u m""Update modified date"blogmore-update-modified:inapt-if-notblogmore--blog-post-p)]["Links"("l c""Link to a category"blogmore-link-category:inapt-if-notblogmore--blog-post-p)("l p""Link to a post"blogmore-link-post:inapt-if-notblogmore--blog-post-p)("l t""Link to a tag"blogmore-link-tag:inapt-if-notblogmore--blog-post-p)]])
With this in place I can simplify my use-package quite a bit, just binding a single key to run blogmore.
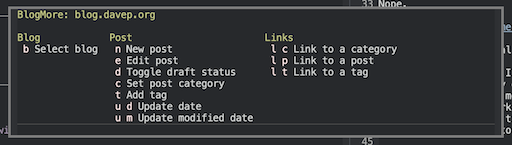
Now, when I'm working on a blog post, I can just hit F12b and I get a neat menu:
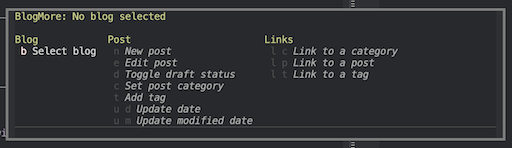
Better still, because of how transient works, I can ensure that only applicable commands are available, while still showing them all. So if I've not even got a blog selected yet:
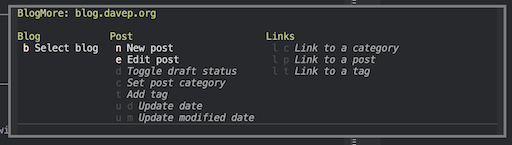
Or with a blog selected but not actually working on a post yet:
So far I'm really liking this approach, and I'm tempted to lean into transient more with some of my packages now. While on the surface it does seem that it has the downside of the binding choices being dictated by me, the fact is that the commands are all still there and anyone can use their own bindings, or I guess override the transient itself and do their own thing.
Yes, it is a bit out of the way on the keyboard, but so is Esc. I find my muscle memory has no problem with it. ↩
Back when I first really got into writing Emacs Lisp code, one of the first things I got very used to and really fell in love with was being able to eval-last-sexp (C-xC-e) the code I was writing, either to test it right there in the buffer, or to cause it to be bound so I could use it elsewhere. It was so different from any other mode of working I'd used before and it was really addictive as a way of hacking on code.
Also quite quickly I got used to the fact that eval-last-sexp wasn't so helpful with things like a defvar or a defconst, if I was changing them up to try out new ways of doing things with the code I was working on; there I had to remember to get used to using eval-defun (C-M-x). Hardly a great problem, but something to keep in mind1.
Pretty quickly, as I worked on longer packages, I found myself wanting to, in effect, unload a whole buffer of code and evaluate it again. From this desire came nukneval.el.
The original version of this has been sat around since 2002 or so, perhaps a little earlier, and has served me well every time I've been messing with a new package. While I suspect there is (now, perhaps was then too?) a better way of doing things, the approach used in nukneval helped me learn some things and served me well (and still does). Now it's muscle-memory to run it.
The way it works is quite simple: go to the start of a buffer, read each form, check if the car is of a given list of symbols, decide if it's something I want to unbind, and then pick either makunbound or fmakunbound and use that on the symbol. Finally, once the end of the buffer has been hit: eval-buffer.
I've just released v1.3 as part of my slow wander through my old Emacs Lisp packages, with this release cleaning up a deprecated use of setf to move point, and also rewriting the code so it's a bit cleaner and also gives better feedback.
Given I'm currently engaging in a slow background process of cleaning up some of my Emacs Lisp packages, removing some obsoleted practices, I've given make-phony.el a little bit of attention.
Following on from yesterday's release, I've bumped blogmore.el to v2.5. The main change to the package is the thing I mentioned yesterday about the toggle of the draft status. The draft toggle yesterday was pretty simple, with it working like:
If there is no draft frontmatter, draft: true is added
If there is any draft frontmatter, it is removed
This meant that if you had draft: false set and you went to toggle, it would be removed, which is the same as setting it to draft: false.
Unlikely to generally be an issue, but I also couldn't let that stay like that. It bothered me.
So now it works as you'd expect:
If there is no draft frontmatter, draft: true is added
If draft: true is there, it is removed
If draft: false is there, it is set to draft: true
Much better.
Another change is that I fixed a problem with older supported versions of Emacs. I didn't know this was a problem because I'm running 30.2 everywhere. Meanwhile, thanks to package-lint-current-buffer from package-lint.el, I have:
Package-Requires: ((emacs "29.1"))
in the metadata for the package. Turns out though that sort used to require two parameters (the sequence and the predicate), whereas now it's fine with just one (it will accept just the sequence and will default the predicate). So of course blogmore.el was working fine for me, but would have crashed for someone with an earlier Emacs.
As for how I found this out... well I finally, for the first time ever, dived into using ERT to write some tests. While I've used testing frameworks in other languages, I'd never looked at this with Emacs Lisp. It works a treat and is great to work with; I think I'll be using this a lot more from now on.
Having got tests going I realised I should run them with GitHub actions, which then meant I managed to discover setup-emacs. Having found this the next logical step was to set up a matrix test for all the versions of Emacs I expect blogmore.el to work on. This worked fine, except... it didn't. While the tests worked locally, they were failing for some Emacsen over on GitHub.
And that's how I discovered the issue with sort on versions earlier than the one I'm using locally.
All in all, that was a good little period of hacking. New things discovered, the package improved, and a wider range of support for different versions of Emacs.
The fix was simple enough, and is another little interesting thing to keep in mind given that BlogMore is an ongoing Copilot experiment. When I first kicked off BlogMore I let it decide which library to use to handle Markdown (I'm more used to markdown-it-py via Textual and so via Hike), and so also let it decide which extensions made most sense given the request. I've honestly never run into the idea of metadata before, only ever dealing with or caring about frontmatter1.
On the other hand, I will say this: I was cooking dinner when the report came in; I pointed Copilot at the issue and let it figure it out. After eating, clearing things away, and general post-dinner chilling, I dropped into the repo to see what it had made of it and... it had figured the issue out and fixed it.
I guess technically they're the same thing, but here I mean I'm more used to the delimited YAML of frontmatter than whatever it is the meta plugin was dealing with. ↩
I've just released a little update to blogmore.el, adding blogmore-toggle-draft as a command. This came about in connection with the feature request that resulted in BlogMore v2.7.0 being released.
While I don't personally use draft for my posts, I can see the utility of it and if someone were to happen to use blogmore.el, it could be useful to have this bound to a handy key combination.
As for how it works: that's simple. When run, if there is no draft: frontmatter property, then draft: true is added. If draft: is there it is removed. Yes, it does mean that it will also remove draft: false too but... eh. Okay, fine, I might handle that case as a followup but I couldn't really imagine someone wanting to keep draft: false in the frontmatter.
If a post is ready to go, why bother with a header that means the same thing when it's not there?
While support for marking posts as drafts, and including or excluding them from a build, is something that's been in BlogMore from the start, it's not something I've ever used. These days, when I'm writing a post, especially if it's one that's taking a while to write, I'll do it in a branch and eventually PR into main before publishing. Given this it was useful to get a request relating to the feature as it helps me understand how someone else might use it.
When the post's title appears in the archive it will also appear obvious that it's still a draft too:
All of this is, of course, modifiable via the template API and via styling, so if the choice of colour or icon doesn't suit it can be modified to taste.
Some time in the late 1990s, after I'd been using GNU Emacs for a few years1, I grabbed a copy of Writing GNU Emacs Extensions. While I'd obviously created and added to and tinkered with my ~/.emacs some, I'd never written any non-trivial code. I feel it was around 1998 or 1999 that I really started to get into trying to write actual extensions, thanks to that book.
I can't remember what the first complete package was. I think it was actually 5x5.el2 but it might also have been binclock.el. Honestly, it's so long ago now that I don't have any good recollection and I don't have any record3. All of which is to say, binclock.el is one of my oldest bits of Emacs Lisp code, so it seemed fair that while I'm cleaning things up, I should give it a tidy too.
For anyone curious: it's a very simple binary clock type of thing. It opens a very small window and, depending on your settings, shows the time in various ways, all of which are in some way a binary display.
I can't say I've honestly ever had it running for more than a few moments, as an amusement, but I do remember it being a really helpful body of code to work on to help get familiar with Elisp. So, 27 years on from when I first opened the buffer to create it, it's tweaked and tidied and hopefully ready for another 27.
Would be cool if I'm around long enough to give it yet another tweak then.
I first met it on OS/2 of all places, in 1994, or thereabouts. ↩