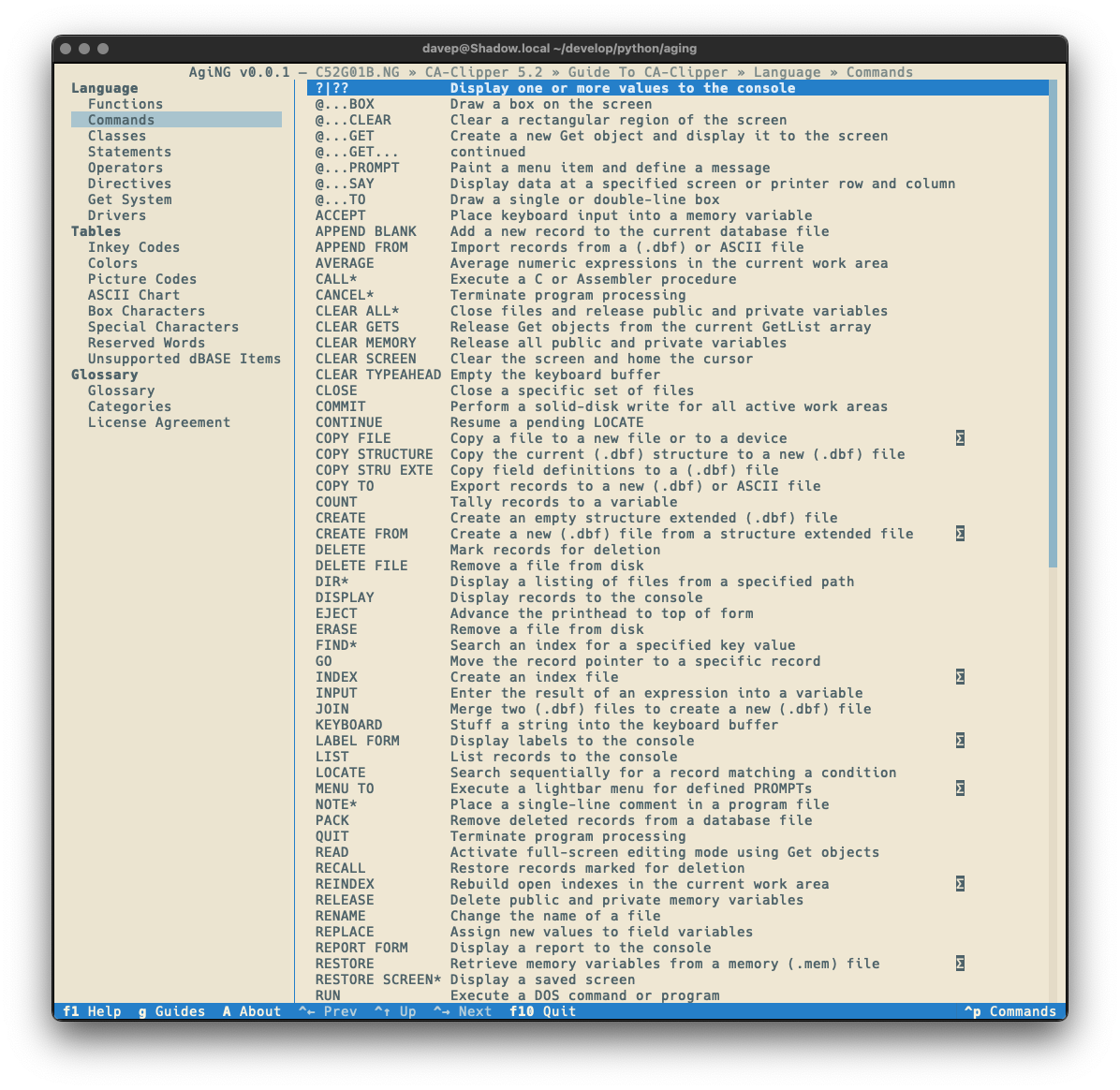
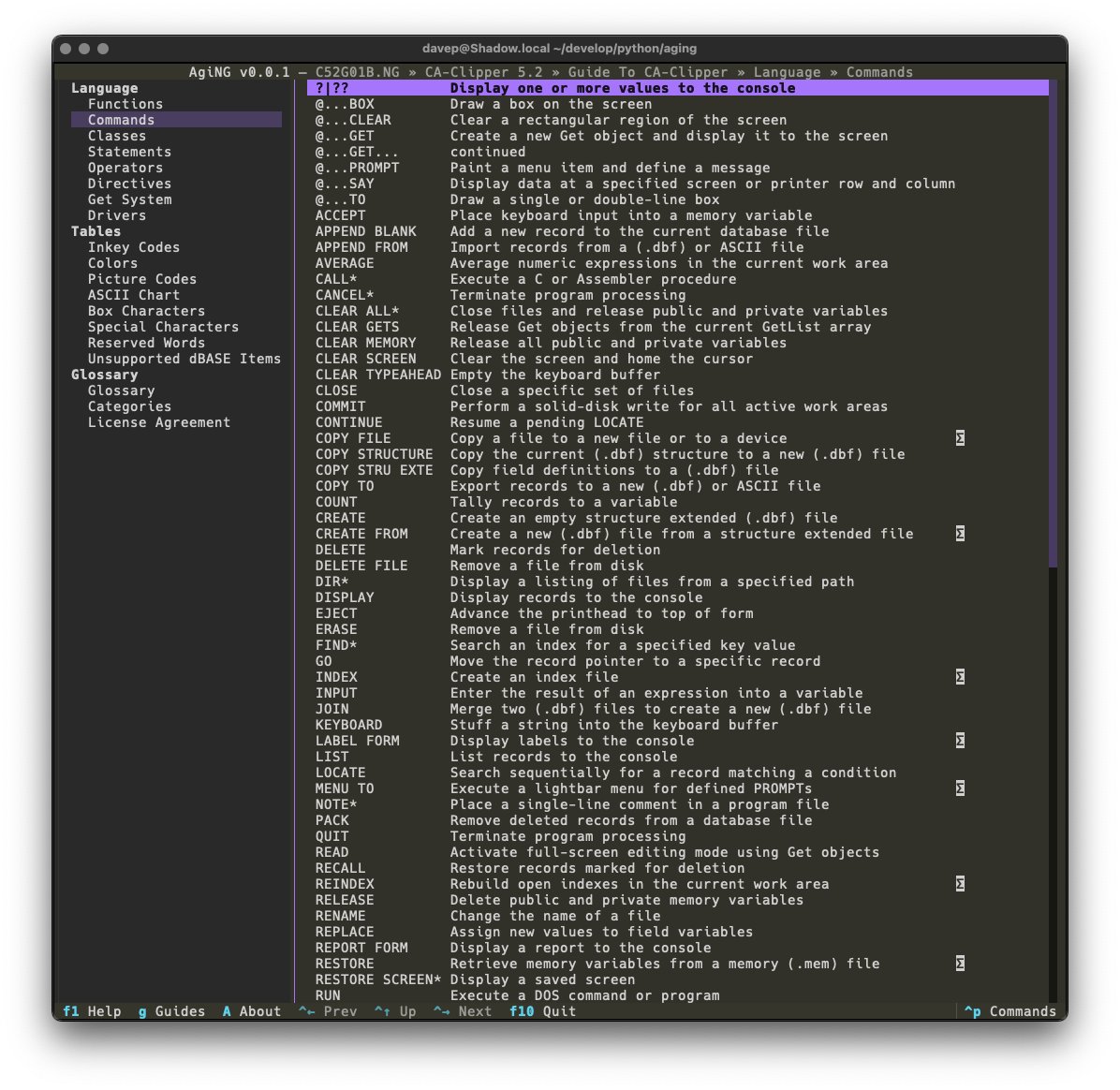
I've just released AgiNG v0.3.0. The main focus of this release was to get some searching added to the application. Similar to what I added to WEG back in the day, I wanted three types of searching:
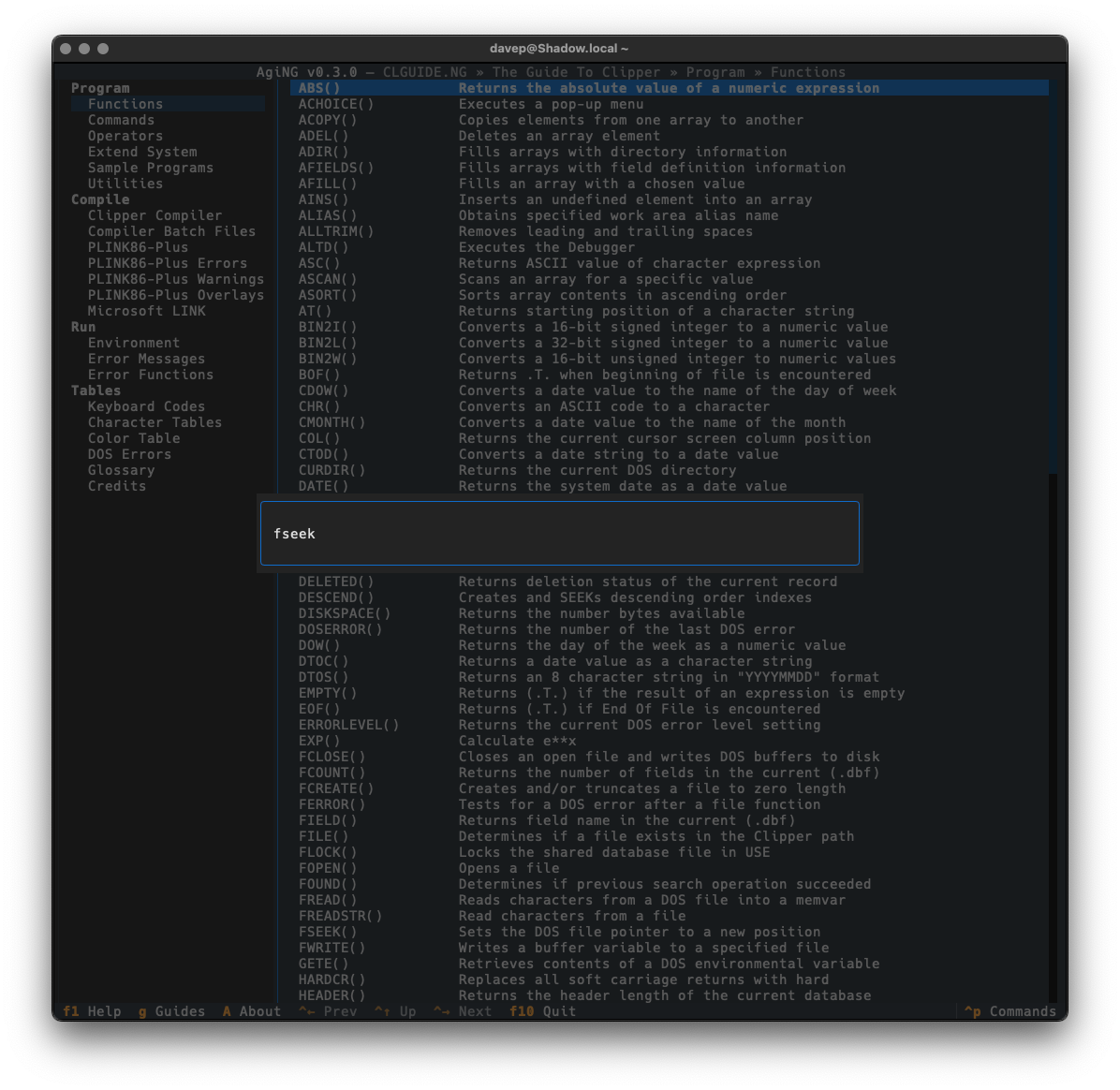
Current entry search.
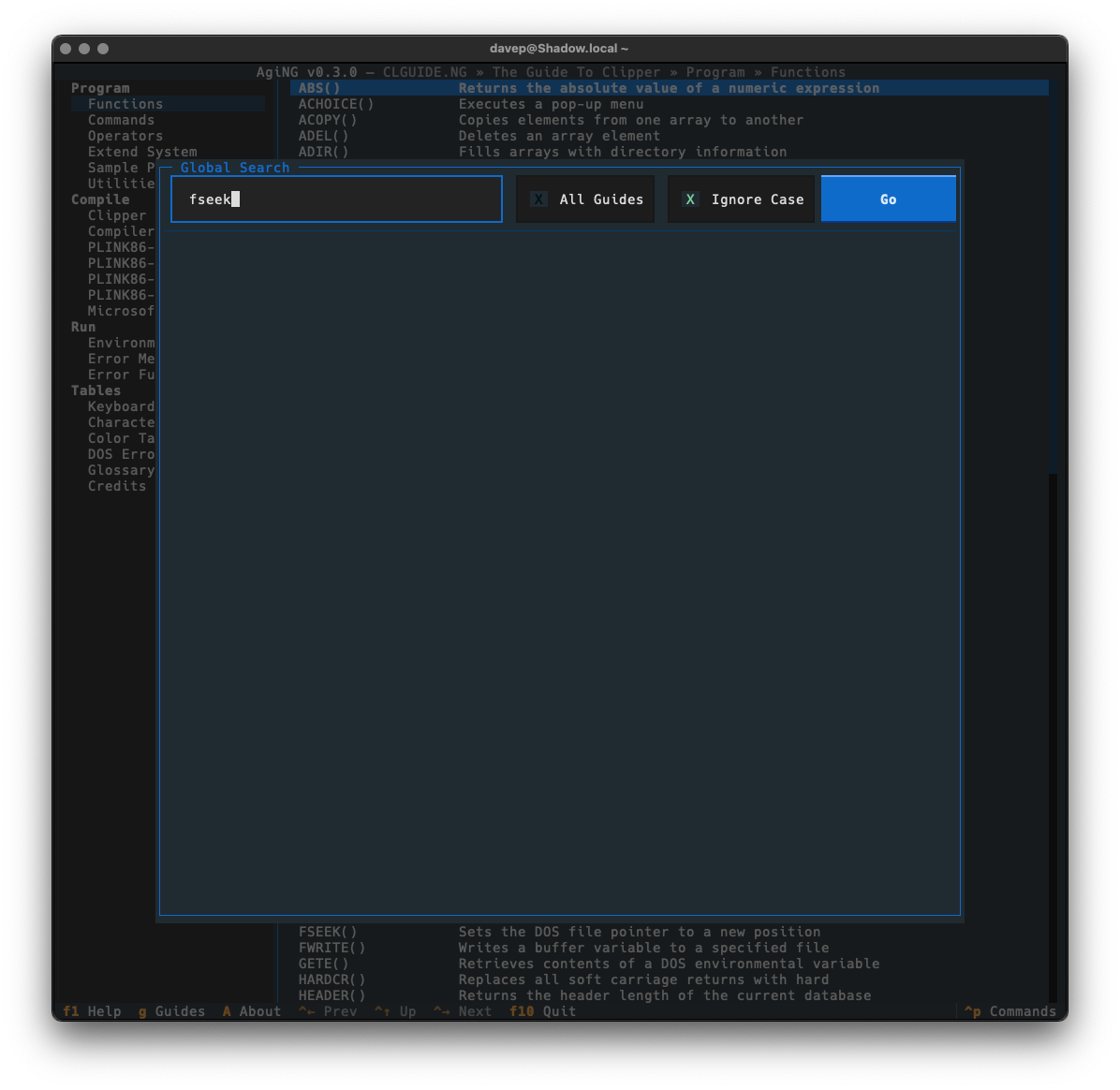
Current guide-wide search.
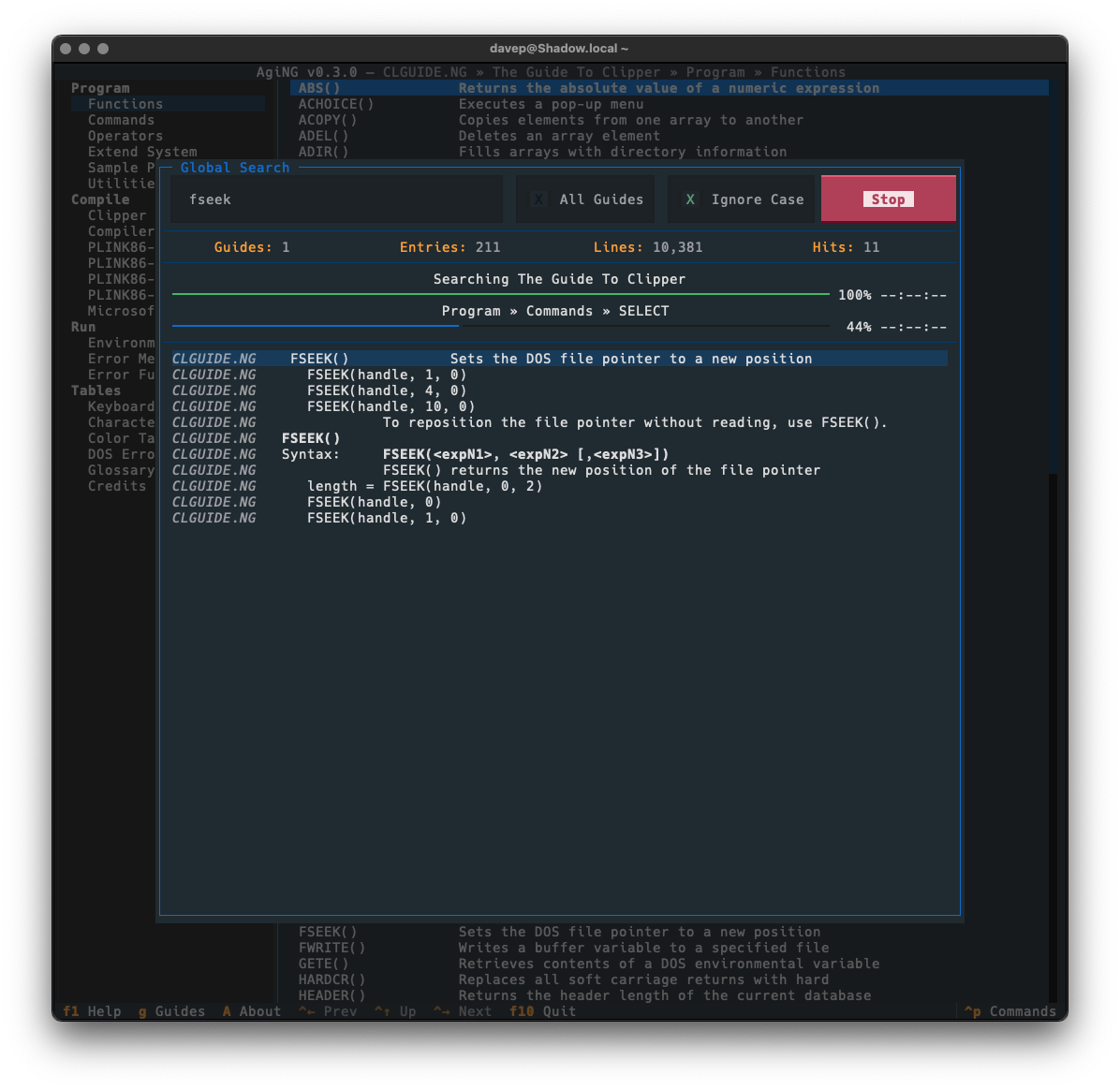
All registered guides-wide search.
The current entry search is done with a simple modal input, and for now the searching is always case-insensitive (I was going to add a switch for this but it sort of felt unnecessary and I liked how clean the input is).
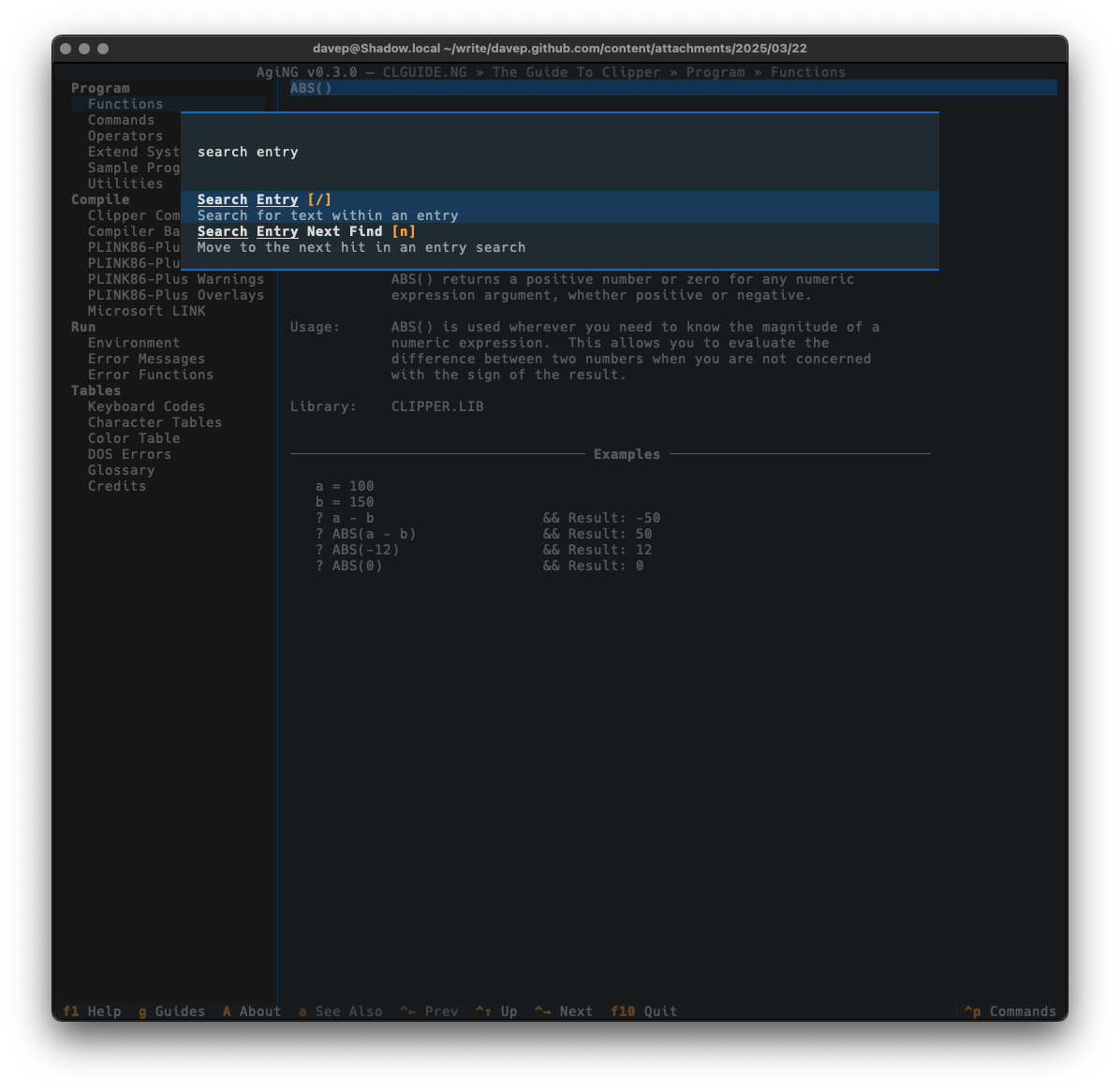
The search is started by pressing /, and if a hit is found n will take you through all subsequent matches.
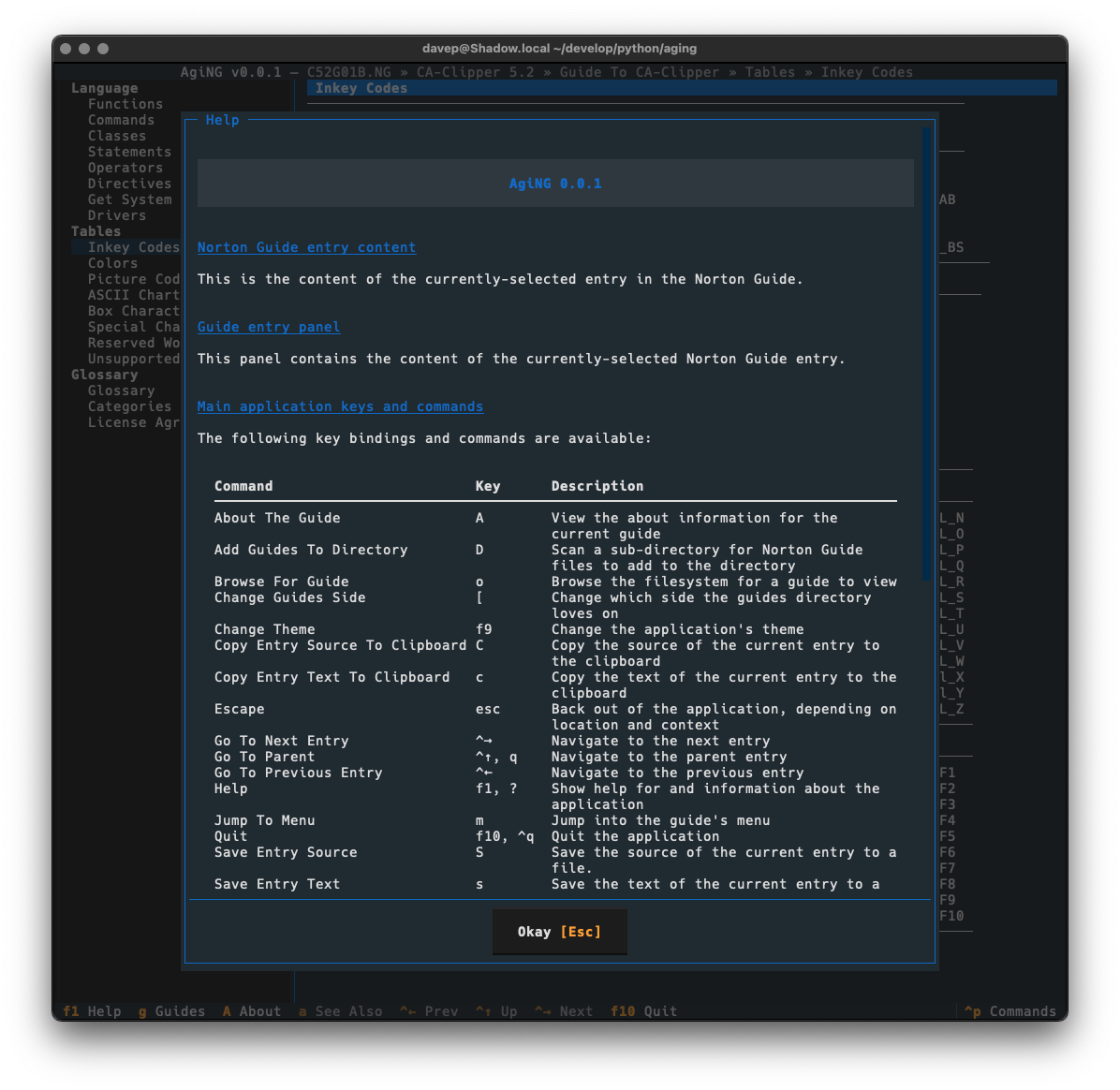
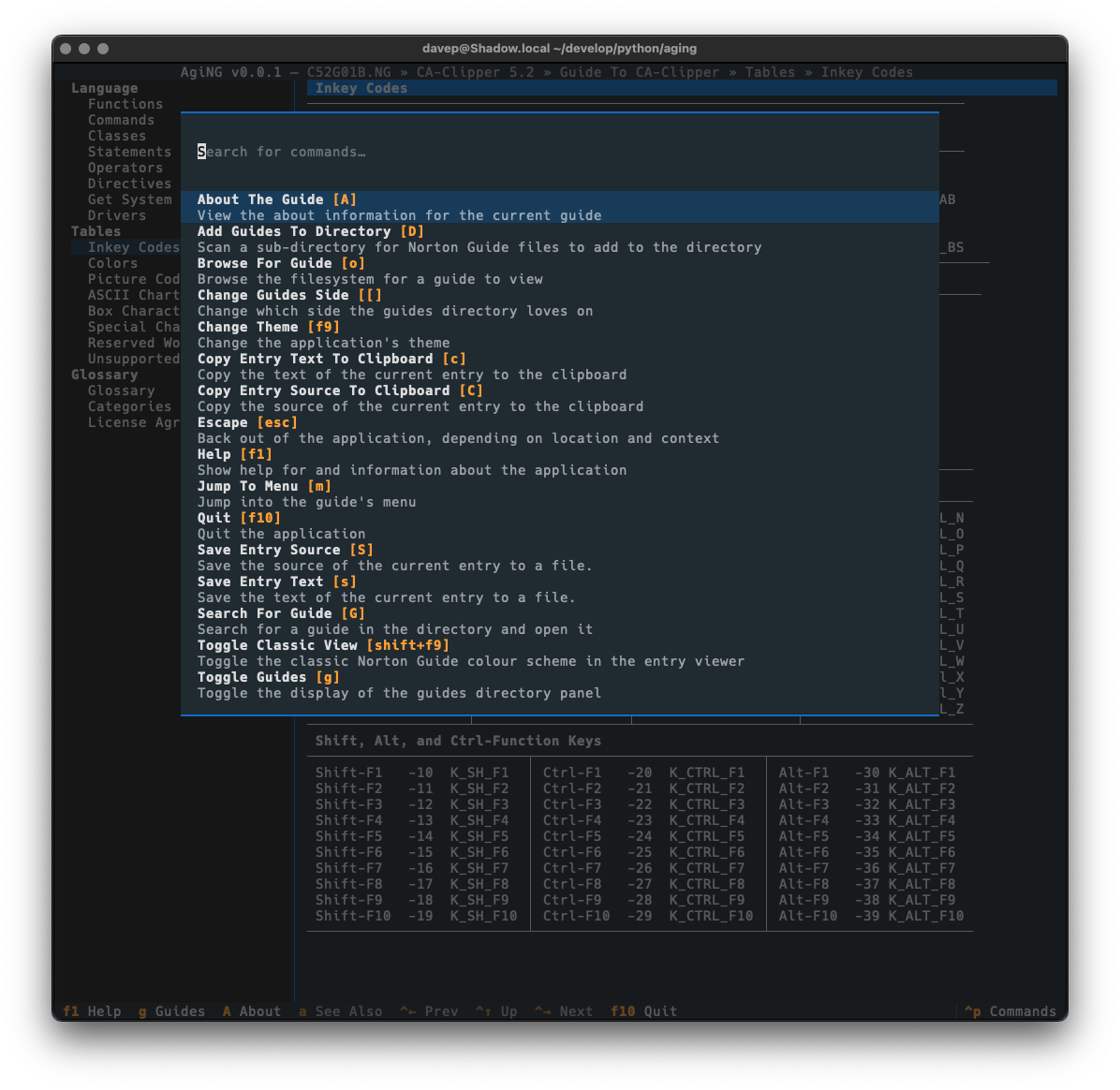
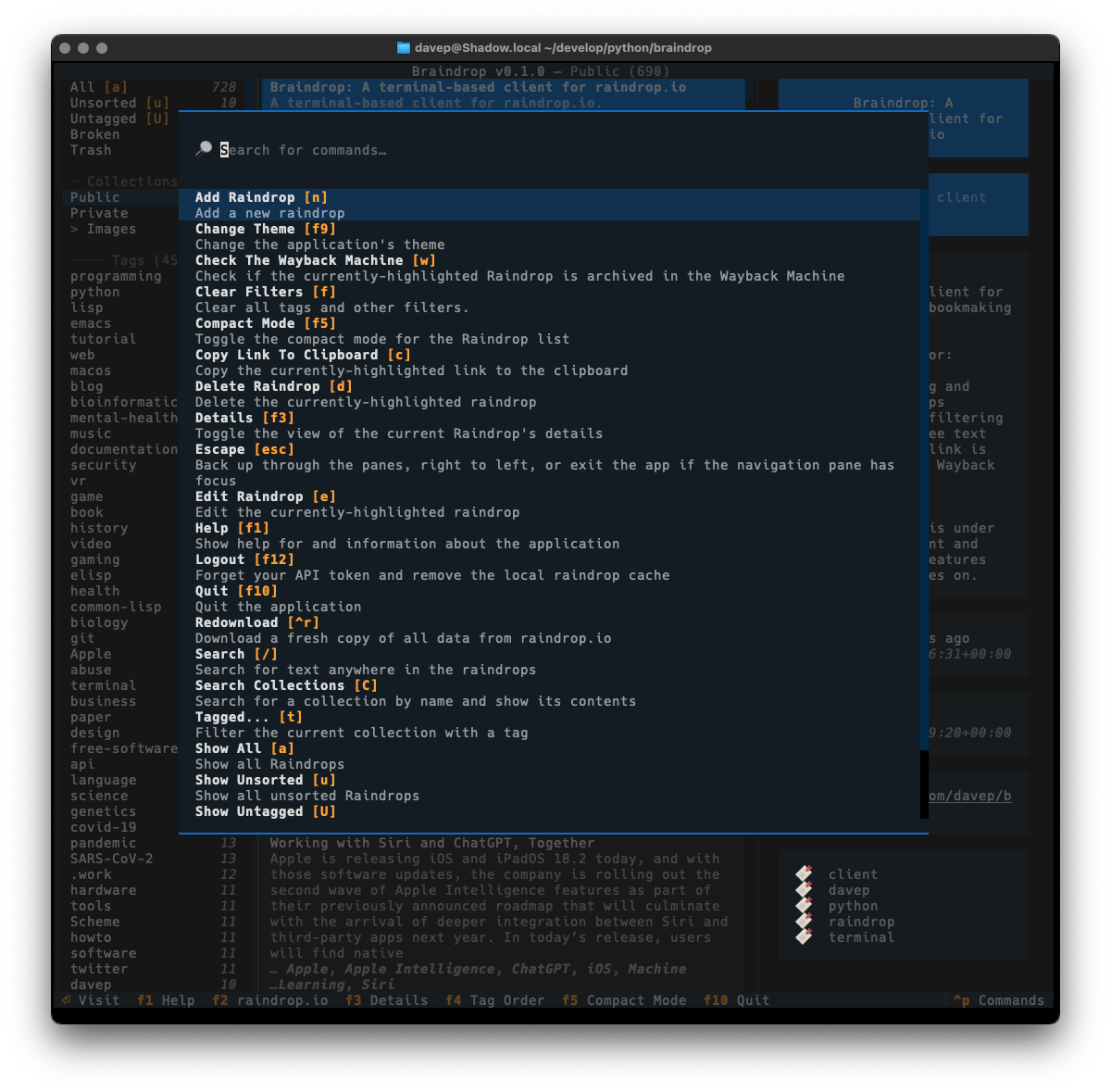
As always, if you're not sure of the keys, you'll find them in the help screen or via the command palette:
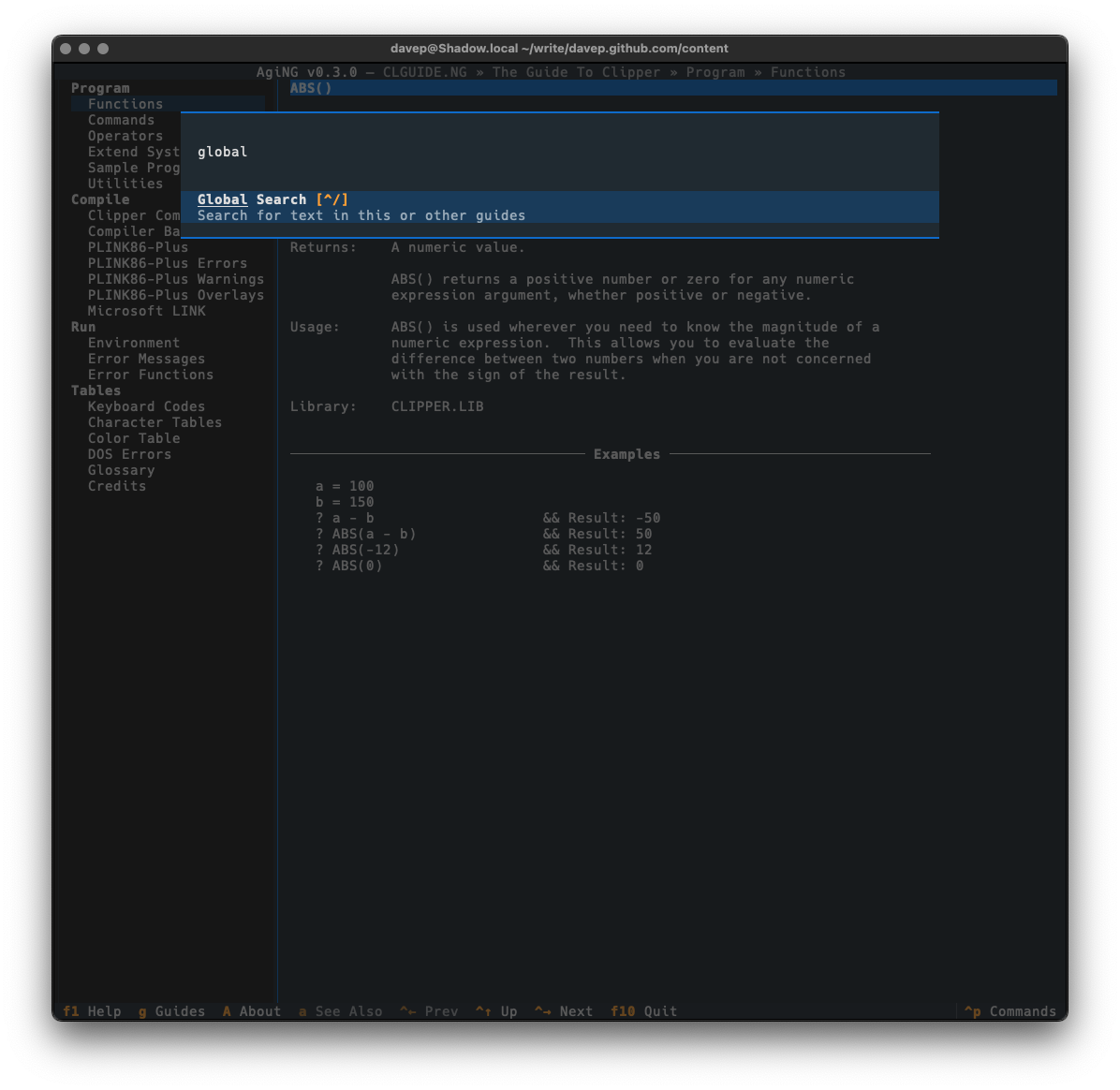
Guide-wide and all-guide searching is done in the same dialog. To search guide-wide you enter what you want to find and untick "All Guides".
With that, the search will stick to the current guide.
As will be obvious, searching all guides that have been registered with AgiNG is as simple as ticking "All Guides". Then when you search it'll take a walk through every entry of every guide you've added to the guide directory in the application.
Global searching is accessed with Ctrl+/ or via the command palette.
With this added, I think that's most of the major functionality I wanted for AgiNG. I imagine there's a few more tweaks I'll think of (for example: I think adding regex search to the global search screen could be handy), but I don't think there's any more big features it needs.
AgiNG can be installed with pip or (ideally) pipxfrom PyPI. It can also be installed with Homebrew by tapping davep/homebrew and then installing aging:
It seems I really do still have this need to create new terminal-based projects at the moment. There's been Braindrop, then Peplum, then after that came Hike. While I'm still tweaking and adding to them, and also using them to refine a wee library I'm building up that forms the core of my latest apps, I felt I still had this one app that I needed to finally build.
I'd never written a Python library or application for it though.
So when I first saw Textual mentioned in passing on Twitter a few years back, way back in the 0.1 days, I thought that could be the thing that would push me over the edge. In anticipation of that, back in 2021, I initially developed ngdb.py. This is a library that provides the core Norton Guide reading code for Python applications and could form the basis for other tools.
As a test for this I then wrote ng2web (which works, but I think still needs a bit of tidying up -- something I'm aiming to do in the next few weeks).
Meanwhile, the journey with Textual itself kicked off, happened, and came to an end; and yet somehow I'd never got round to building the thing I'd initially looked at Textual for: a terminal-based Norton Guide reader that looked nice and modern (by terminal standards). When I initially joined Textualize the owner had actually said they wanted me to build this as test of the framework, to essentially start out by employing me to create some Free Software that would help dogfood the library, but that seemed to get forgotten.
Fast forward to the start of this month and I finally felt it was time to tackle this. The result is AgiNG1.
As of v0.1.0 it has most of the features you'd expect from a usable Norton Guide reader, including:
An ability to add guide files to an in-application directory.
The ability open and navigate a guide.
Full see-also support, etc.
Full translation of characters as were under MS-DOS into the terminal.
The ability to copy entry text or source to the clipboard.
The ability to copy save entry text or source to a file.
Access to a guide's credits.
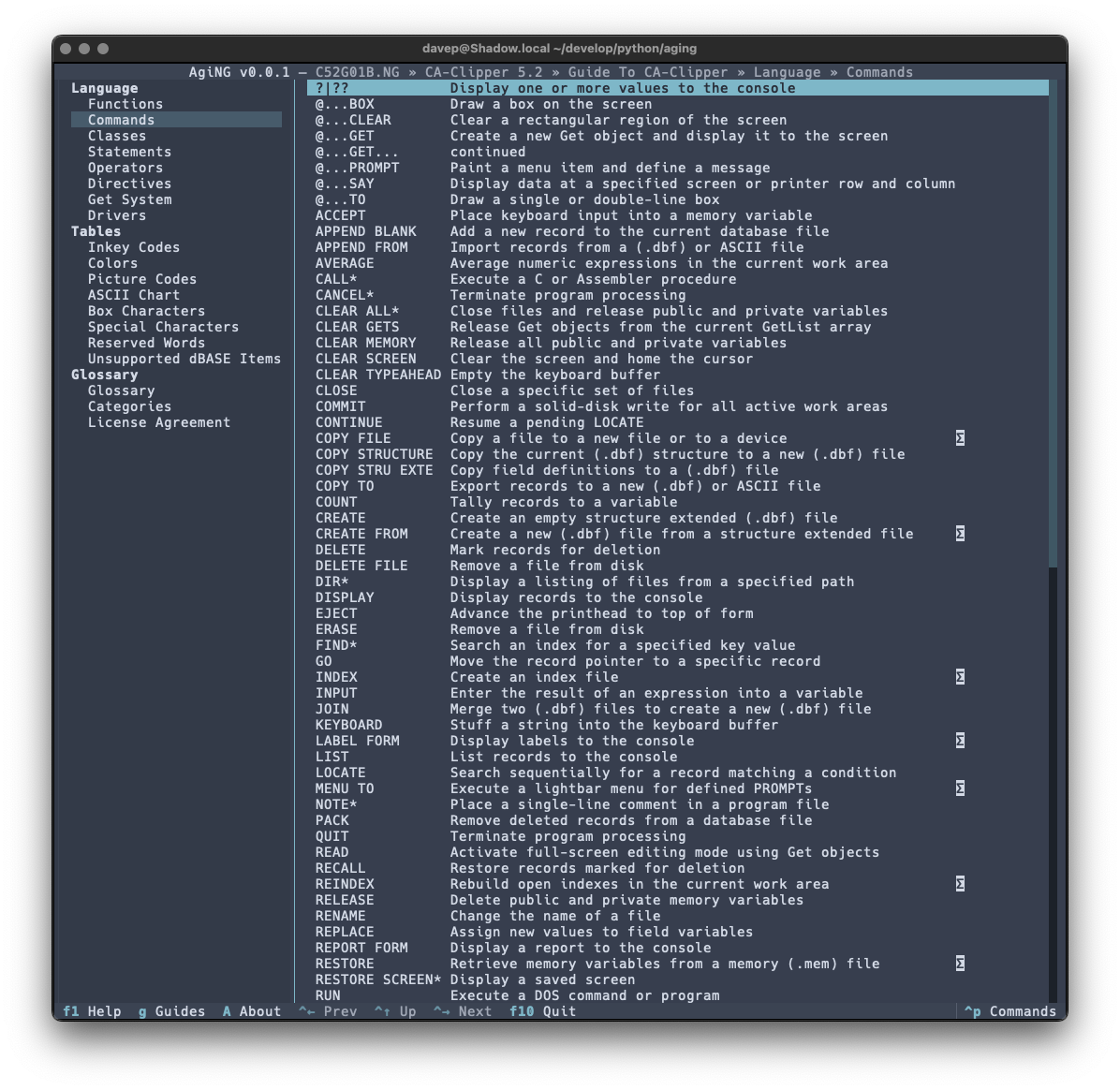
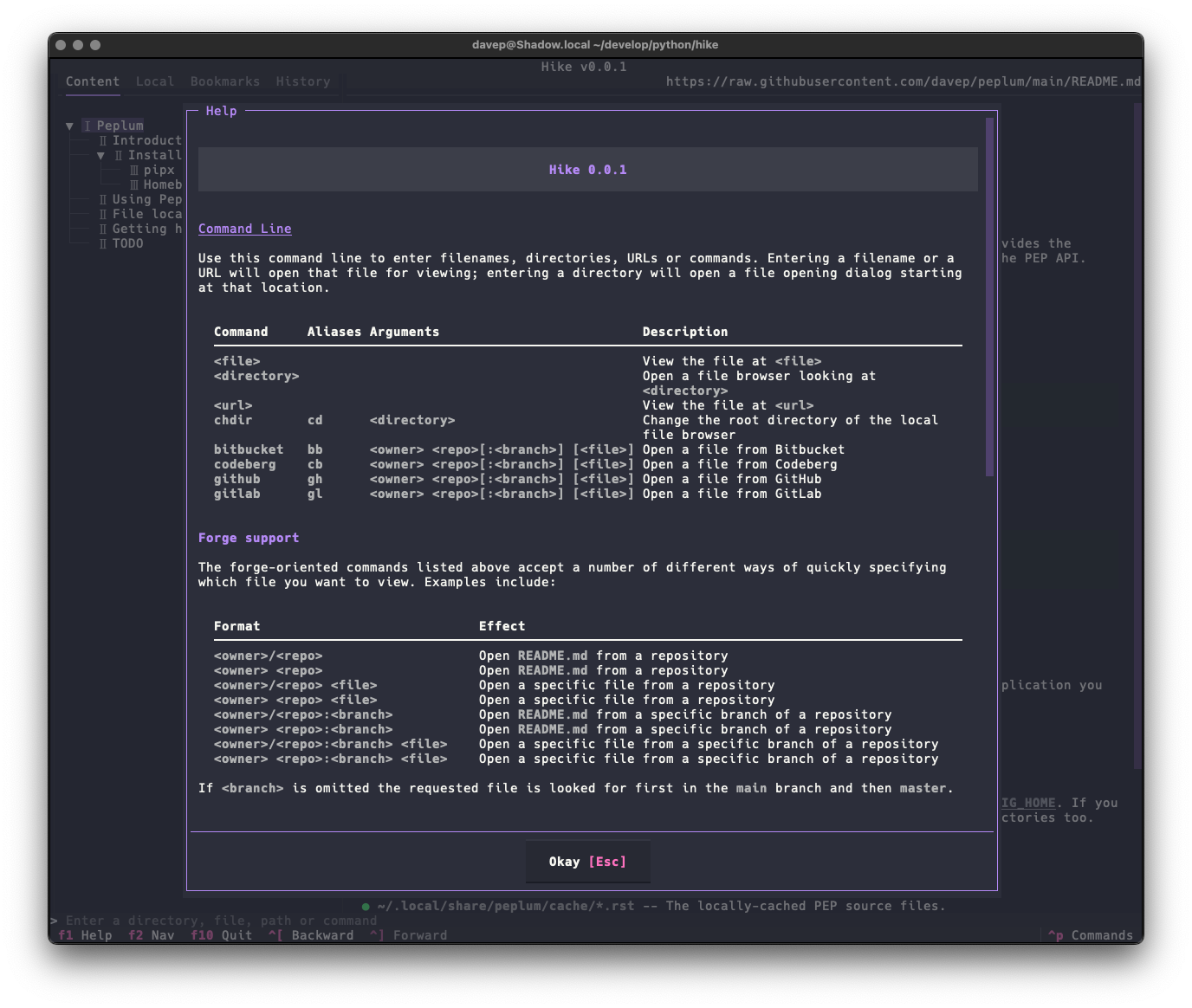
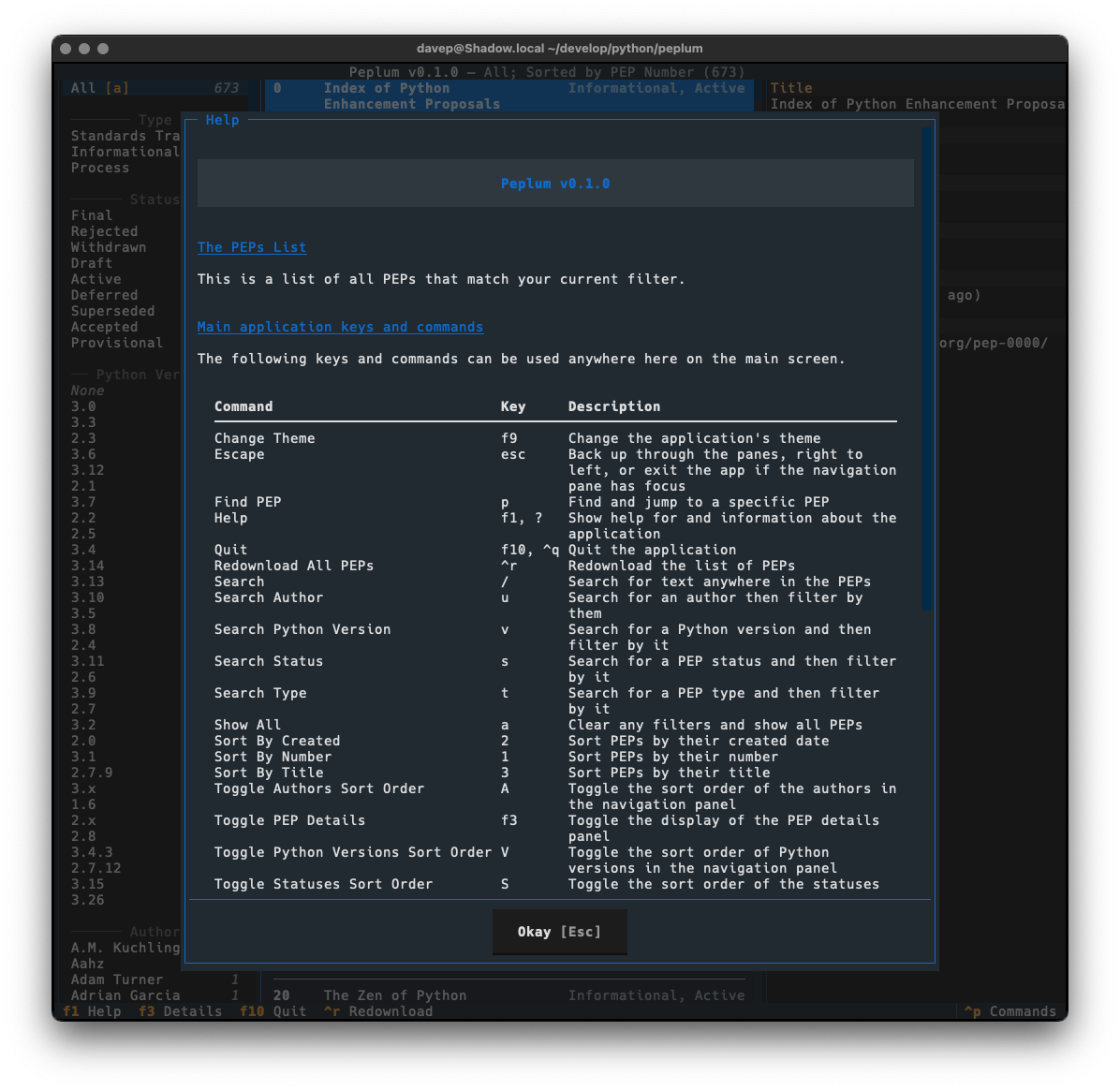
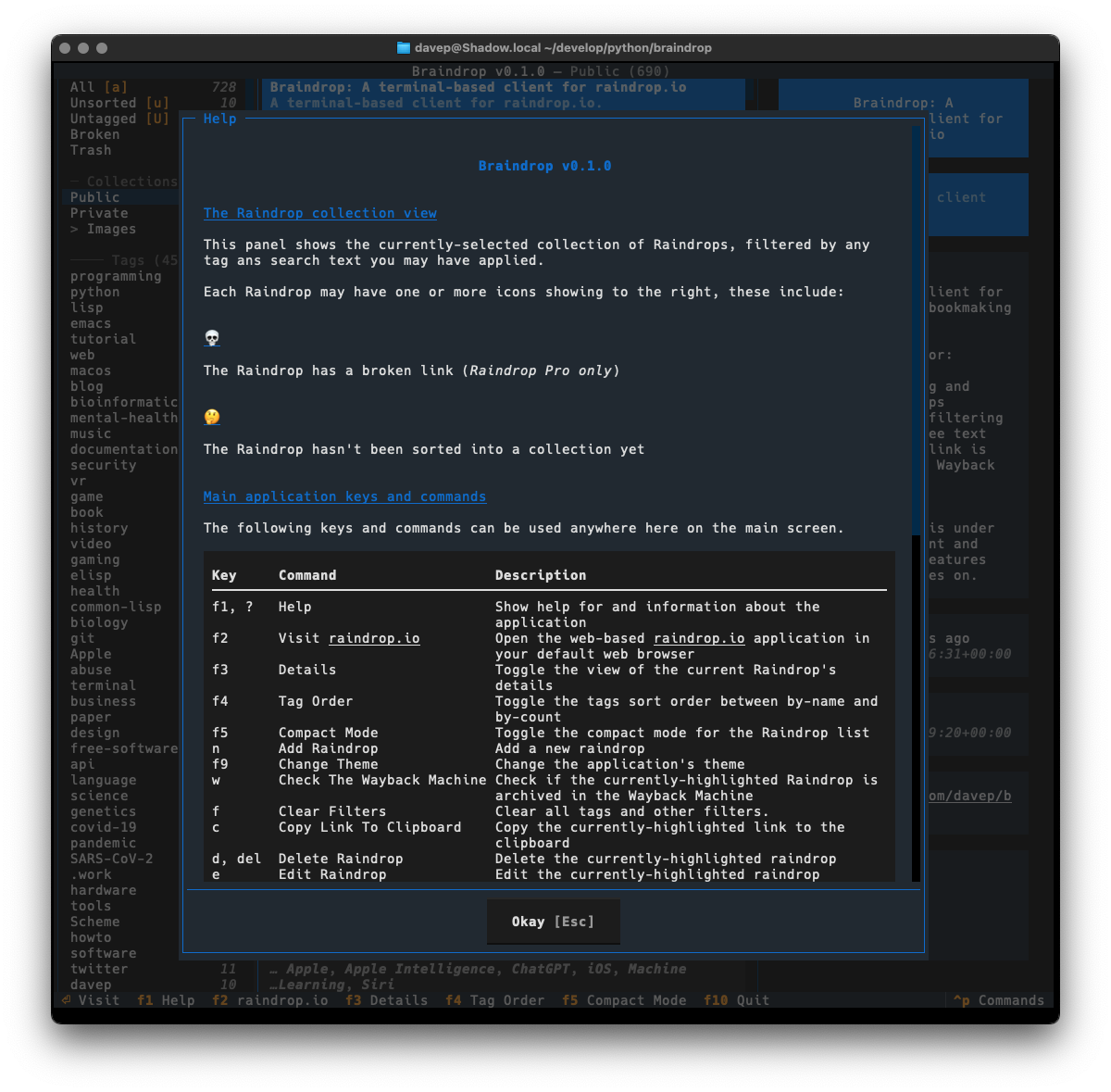
I still need to write some proper documentation for the application, but meanwhile all commands and key shortcuts can be discovered either via the help screen:
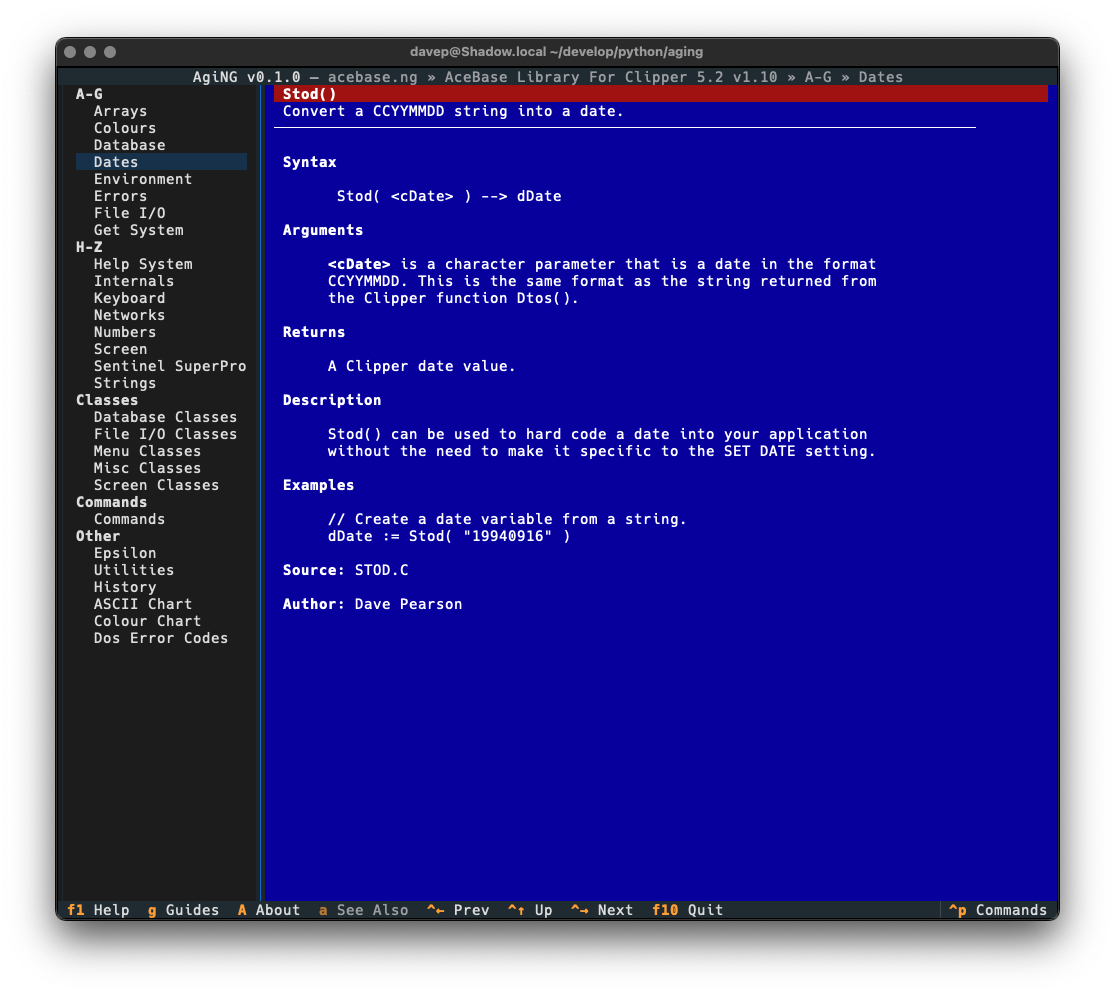
One wee feature I want to call out, that I felt was important to add, was a "classic view" facility. The thing with Norton Guide files is they were mostly created in the very late 1980s and early-to-mid 1990s. People would often get creative with the colouring within them, but in many cases the colouring assumed the default Norton Guide application. Its colours were white text on a blue background. So sometimes other colouring was done assuming that background.
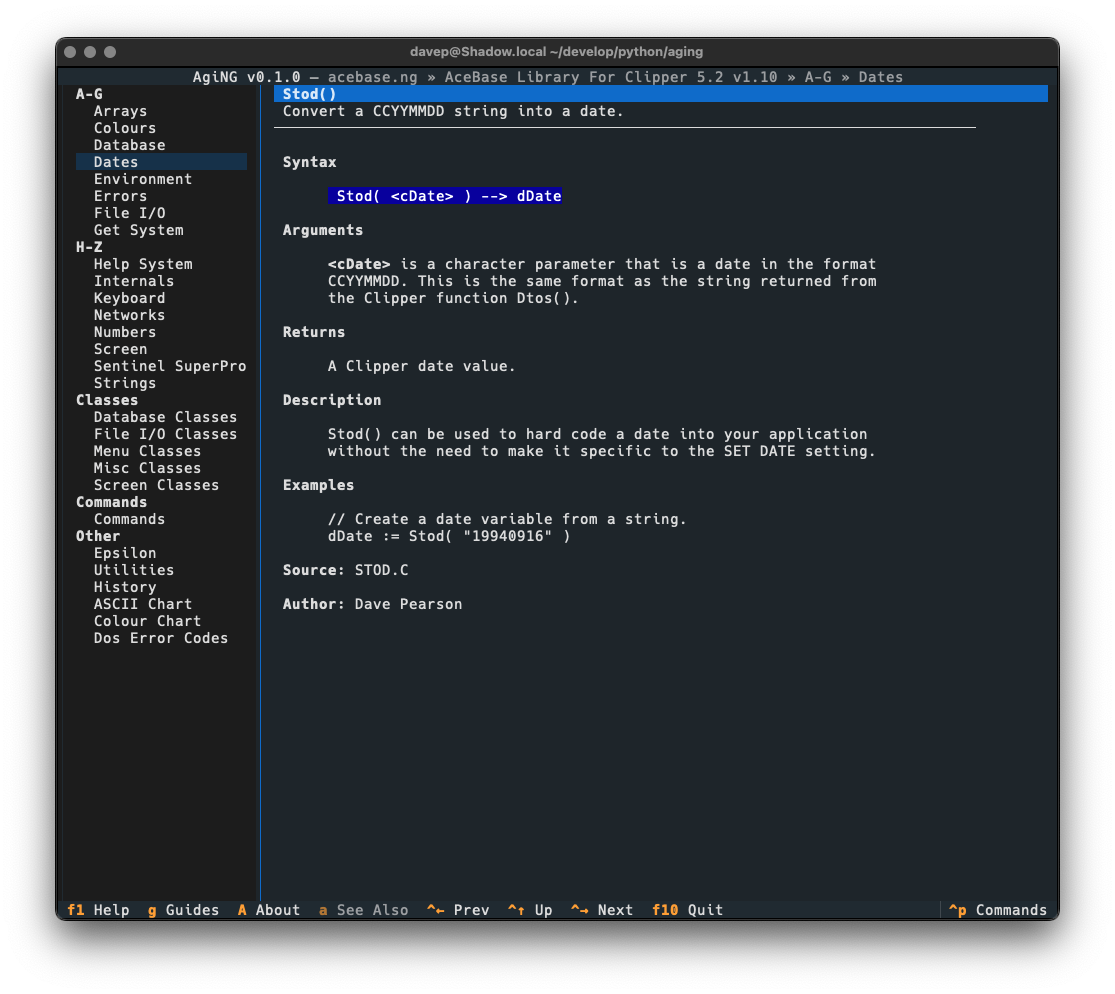
You can see an example of this here, with an entry in a guide being viewed using the default textual-dark theme:
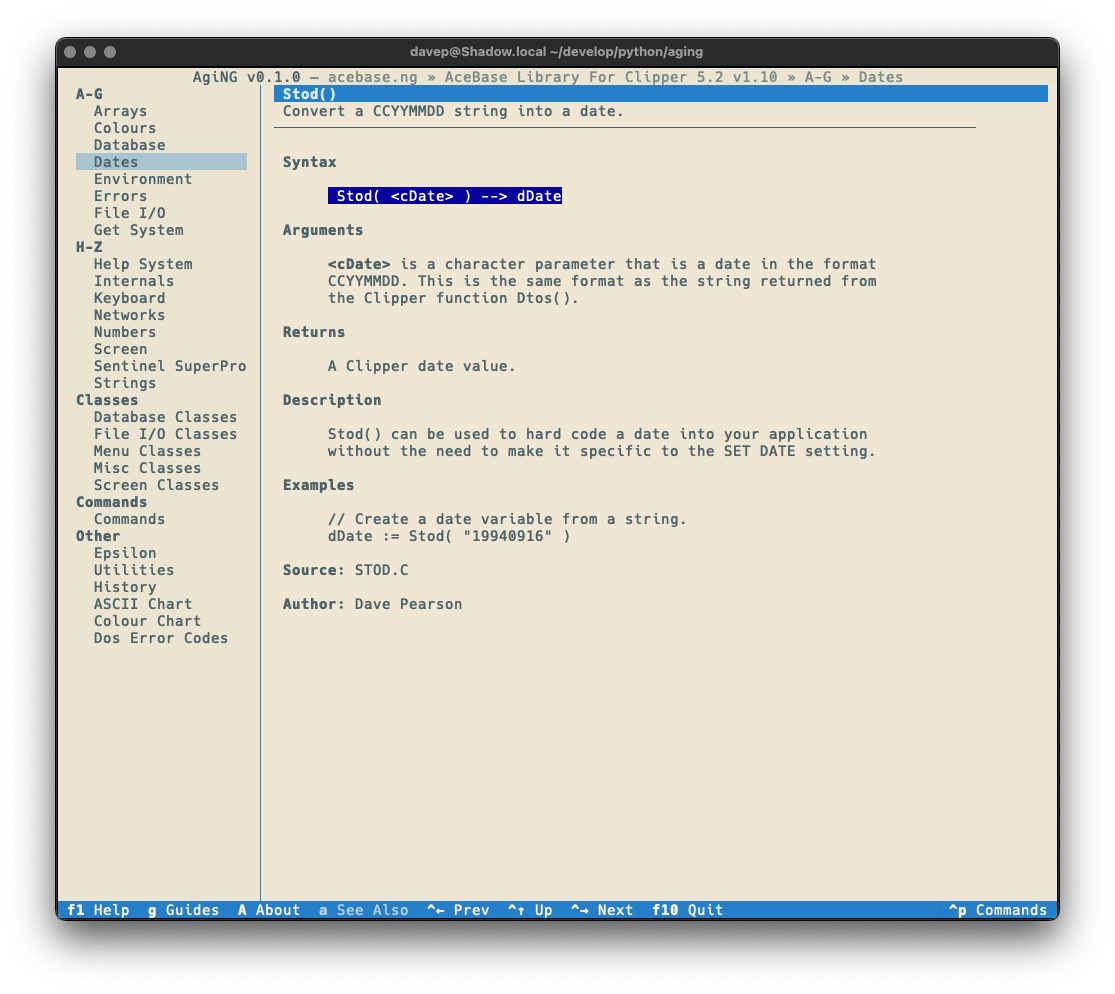
Notice the colouring in the syntax section. This is more obvious if the application is switched to one of the light themes:
With a nod to this issue in mind, I added the "classic view" for entries (which is a sticky setting -- turn it on and it stays on until you turn it off):
A little hard on the eyes, I think, but also filled with nostalgia!
Talking of themes, all the usual application themes are available, here's a wee selection:
AgiNG is licensed GPL-3.0 and available via GitHub and also via PyPI. If you have an environment that has pipx installed you should be able to get up and going with:
pipxinstallaging
It can also be installed with Homebrew by tapping davep/homebrew and then installing aging:
brewtapdavep/homebrew
brewinstallaging
Expect to see more updates in the near future; as with other recent projects this is very much something I'm going to be dabbling with and improving as time goes on.
If you're wondering about the name, it's nothing more than a word that happens to have NG in it, and also a mild pun about this being an ageing hypertext help system; with the spelling acknowledging Peter Norton's nationality. ↩
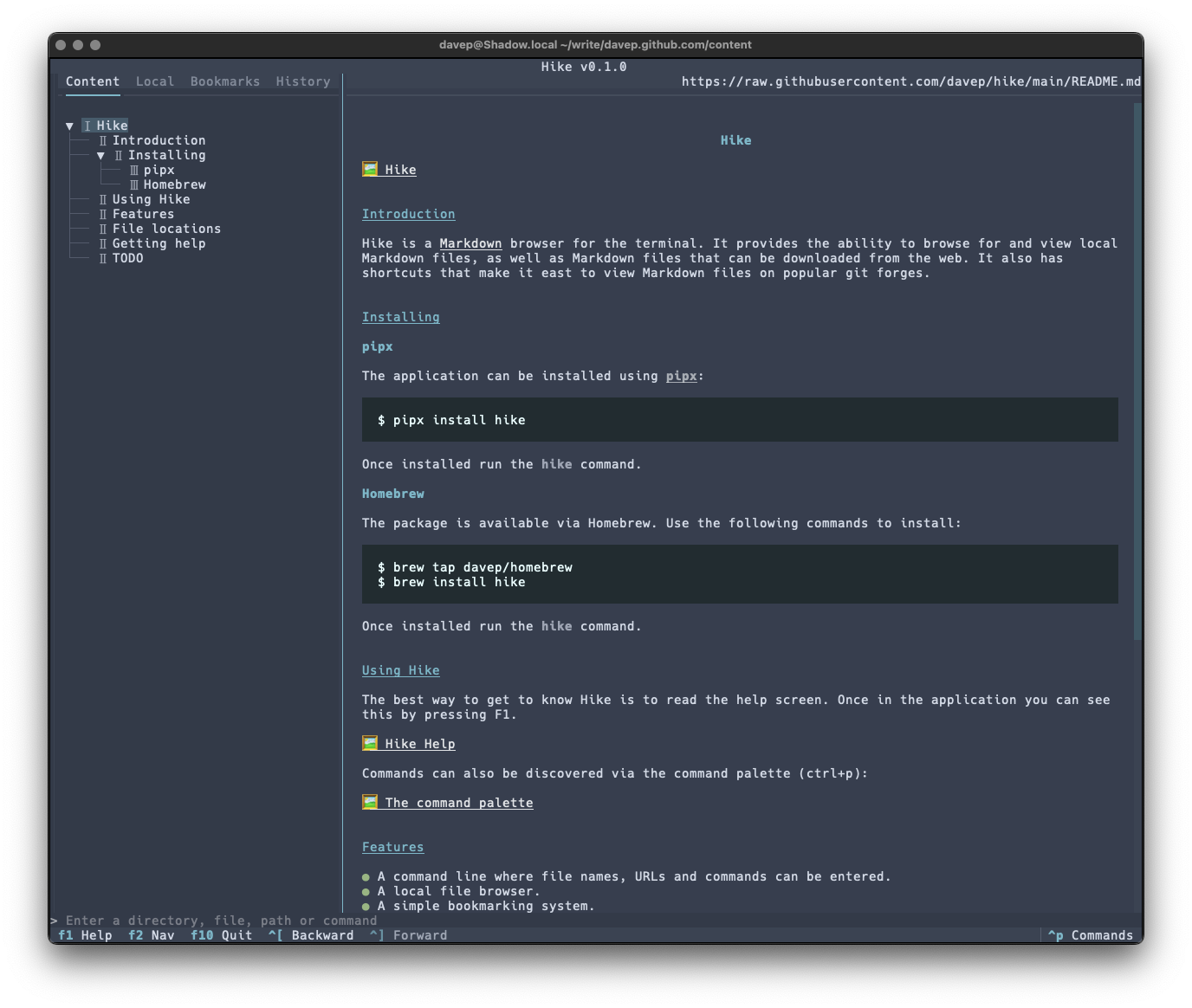
The run of writing new terminal-based tools that I want still keeps going. First there was Braindrop, then there was Peplum, and now, released today, there's Hike.
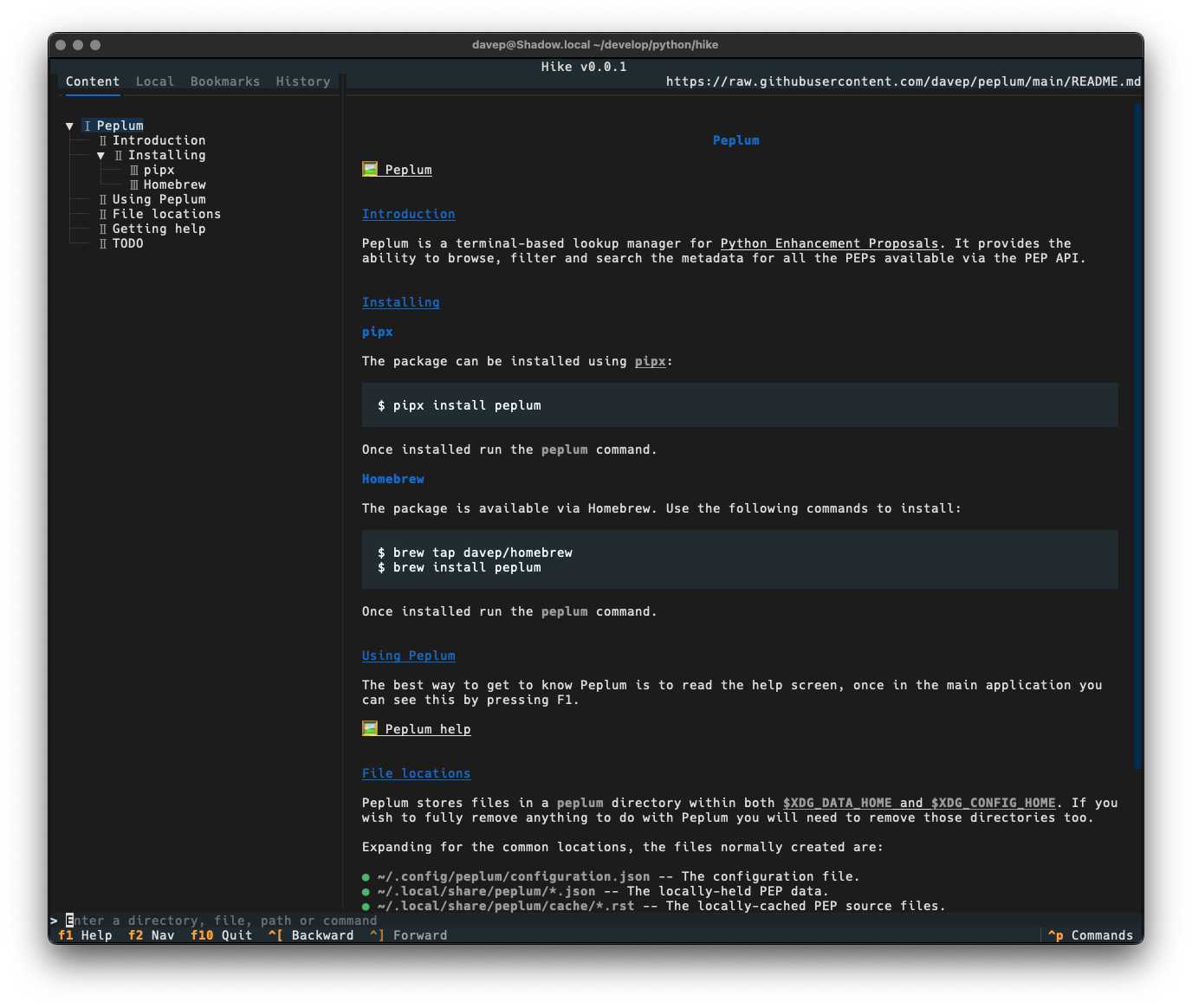
Hike is yet another terminal-based Markdown browser. While it's far from the first, and unlikely to be the last, it's mine and it looks and works exactly how I need. Perhaps it'll be your sort of thing too?
This initial release has a bunch of handy features, including things like:
A command line where file names, URLs and commands can be entered.
A persistent history for the command line.
A local file browser.
A simple bookmarking system.
A browsing history.
Commands for quickly loading and viewing files held on GitHub, GitLab, Codeberg and Bitbucket.
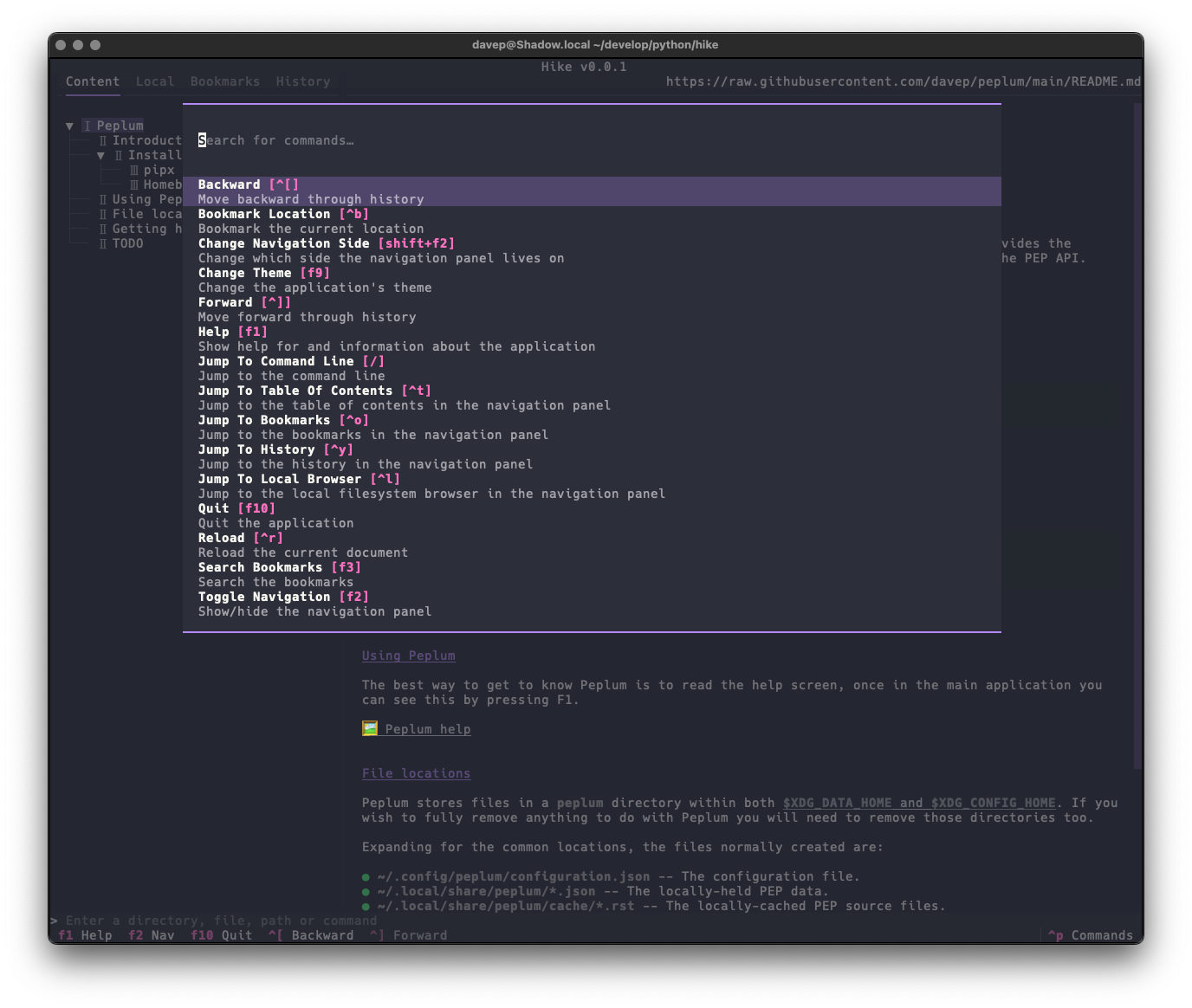
As there's a lot to discover in the application, I've tried to make the help screen as comprehensive as possible:
and there's also the command palette to help with discovering commands and the keys that are associated with them:
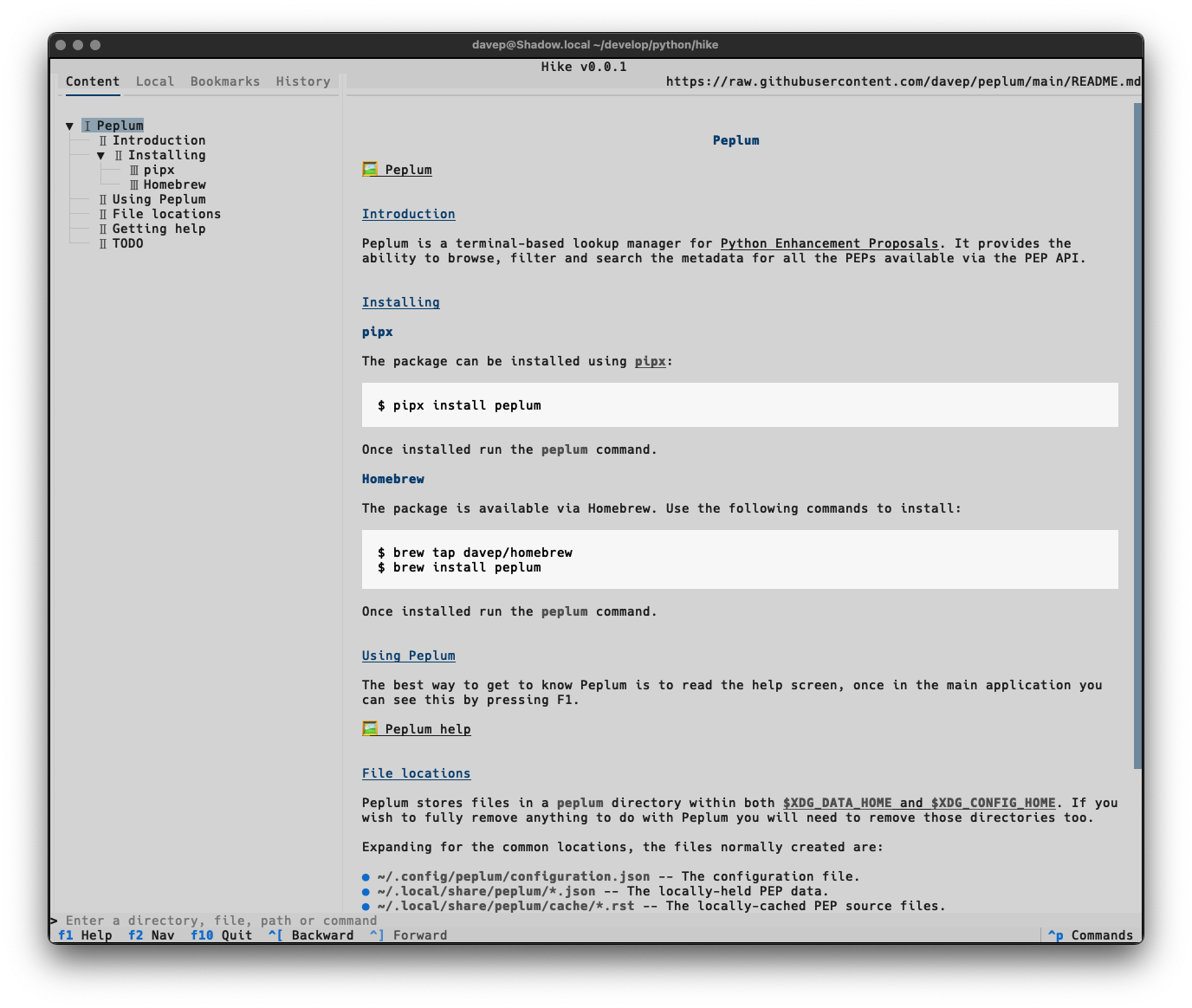
Once again, themes are supported so no matter your taste you should find something that's easy on your eyes:
Hike is licensed GPL-3.0 and available via GitHub and also via PyPI. If you have an environment that has pipx installed you should be able to get up and going with:
pipxinstallhike
It can also be installed with Homebrew by tapping davep/homebrew and then installing hike:
brewtapdavep/homebrew
brewinstallhike
Expect to see more updates in the near future; this is very much an ongoing tinker project.
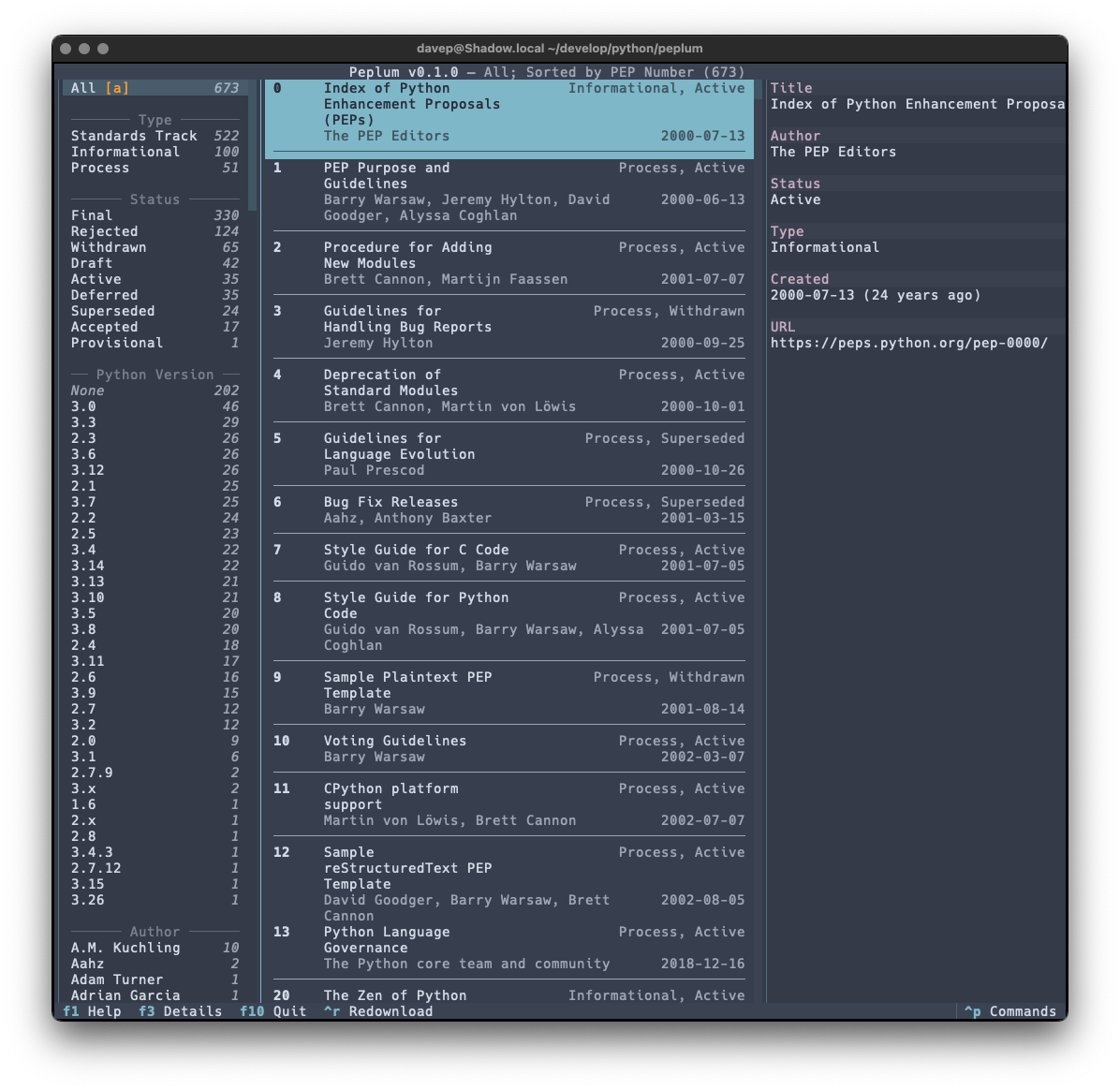
I seem to be back in the swing of writing handy (for me) little terminal-based applications again. Having not long since released Braindrop (which I'm still working on and tinkering with; it'll get more features in the near future, for sure), I had an idea for another tool I'd like to have: something for looking through, searching, and filtering Python PEPs.
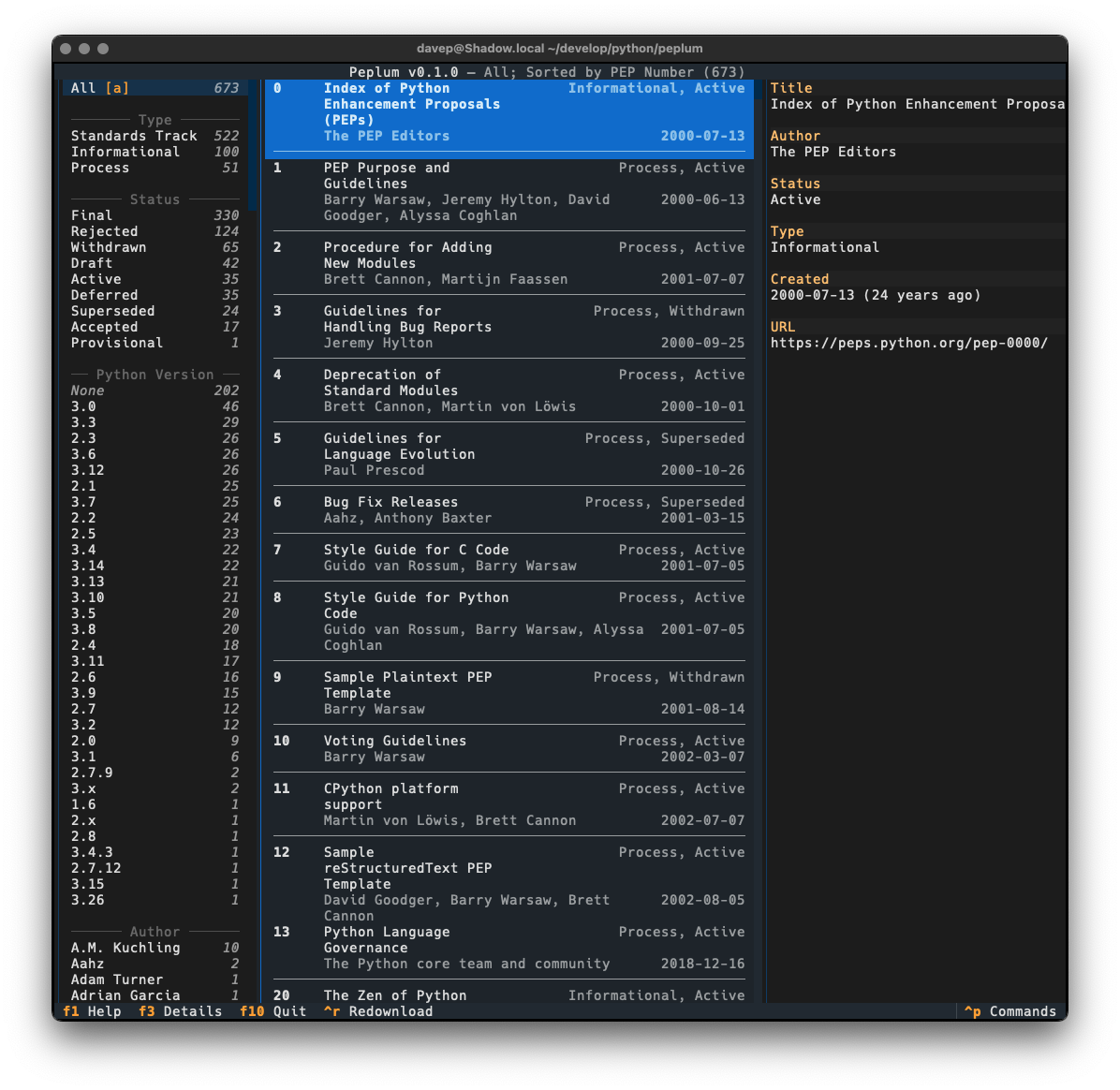
As with anyone who is interested in what's happening with Python itself, I subscribe to the RSS feed of the latest Python PEPs, but I also wanted something that would let me look back at older ones in a way that worked "just so" ("just so" being "what feels right for me", of course). Having finished the main work on Braindrop I realised that the general layout of its UI would work here, as would the filtering and searching approach I used.
In this first release I've simply concentrated on all things to do with grabbing the list of PEPs and presenting them in a useful way; adding various forms of filtering them; adding the ability to search the metadata; that sort of thing. I aim to keep developing this out over the next few weeks and months, adding things like the ability to make notes, to locally view the text of a PEP, perhaps even to mark PEPs as unread and read, etc.
As I mentioned earlier, much of the design was driven by what I did with Braindrop, so once again I've tried my very best to make it keyboard-friendly and as much as possible keyboard-first. This sometimes means having to work against how Textual works, but generally that isn't too tricky to do. I'm once again making heavy use of the command palette and also ensuring that all commands that have corresponding keyboard bindings are documented in the help screen.
There's enough common code between Peplum and Braindrop, when it comes to this aspect of building a Textual application, that I'm minded to spin it out into a little library of its own. I'm going to sit on this code for a wee while and see how it develops, but I can see me taking this approach with future applications and doing this will stop the need to copy and paste.
It might also be useful to others building with Textual.
Also as with Braindrop, themes are a thing, and the theme setting is sticky so you can set it the once and stick with that you like. Here's some examples:
That's a small selection of the themes, with more to explore.
What was even more fun was I sort of discovered a bug in the Python PEP API. Thanks to Hugo noticing my "huh, weird" post on Fosstodon, there's now an issue for it as well as a PR in the works. In retrospect I should have raised an issue myself; instead I fell into that "they obviously know what they're doing so it must be like this for a reason" trap.
Lesson relearned: it's always better to ask and get an answer, than to assume a thing is how it is for a reason you don't know; which I guess is a version of Linus' law really.
So that's v0.1.0 out in the wild. I'm pleased with how it's turned out and there's more to come. It's licensed GPL-3.0 and available via GitHub and also via PyPI. If you have an environment that has pipx installed you should be able to get up and going with:
pipxinstallpeplum
It can also be installed with Homebrew by tapping davep/homebrew and then installing peplum:
brewtapdavep/homebrew
brewinstallpeplum
I'm going to be making good use of this and working on it more; I hope it's useful to someone else. :-)
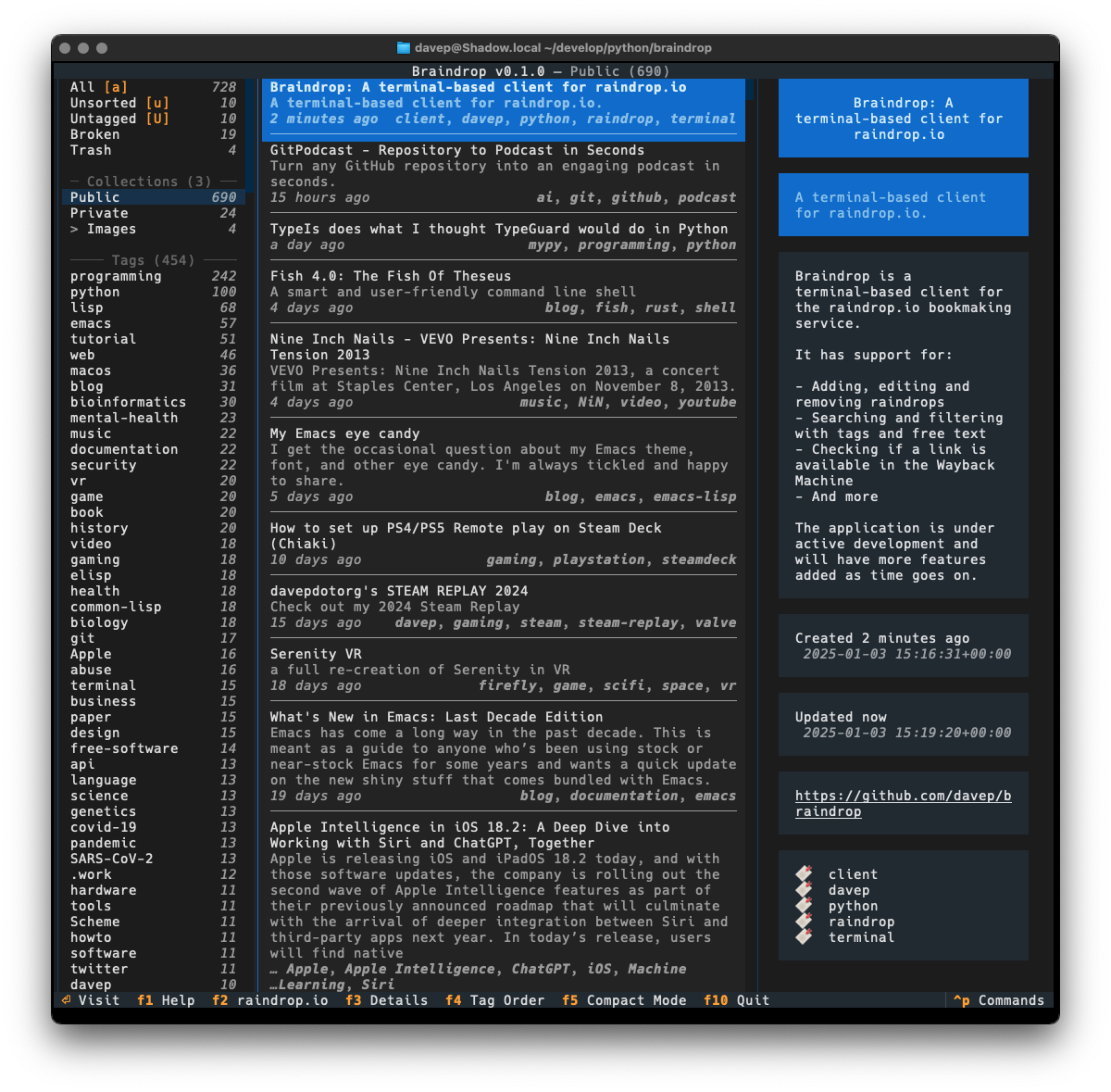
A touch over a year ago I did the initial work on an application called Tinboard, a terminal-based client for the Pinboard bookmarking service. I had a lot of fun building it and it was an application that I used on a near-daily basis. However, around August last year I realised it was time for me to move on from Pinboard and try something new; based on various recommendations I settled on Raindrop.
As mentioned in the other blog post, Raindrop offered more or less everything I had with Pinboard and so the move was fairly straightforward. The one thing that was missing though was an application similar to Tinboard.
So, late on last year, with my winter break approaching, I decided to start from scratch and build a "Tinboard for Raindrop", which I'm calling Braindrop.
This was going to be a bit of an adventure too. Since being laid off from Textualize earlier in 2024 I'd not been following its development quite as closely as I used to, and had also run into some issues and bugs with it since that time; moreover, as well as various bugs appearing, some breaking changes had also been made. As such this was going to be a process where I'd wrap my head around what's happened with the framework over the prior six months or so.
Given all this, over the past couple of weeks I've been spending a few hours a day doing some for-pleasure coding and v0.1.0 of Braindrop is the result.
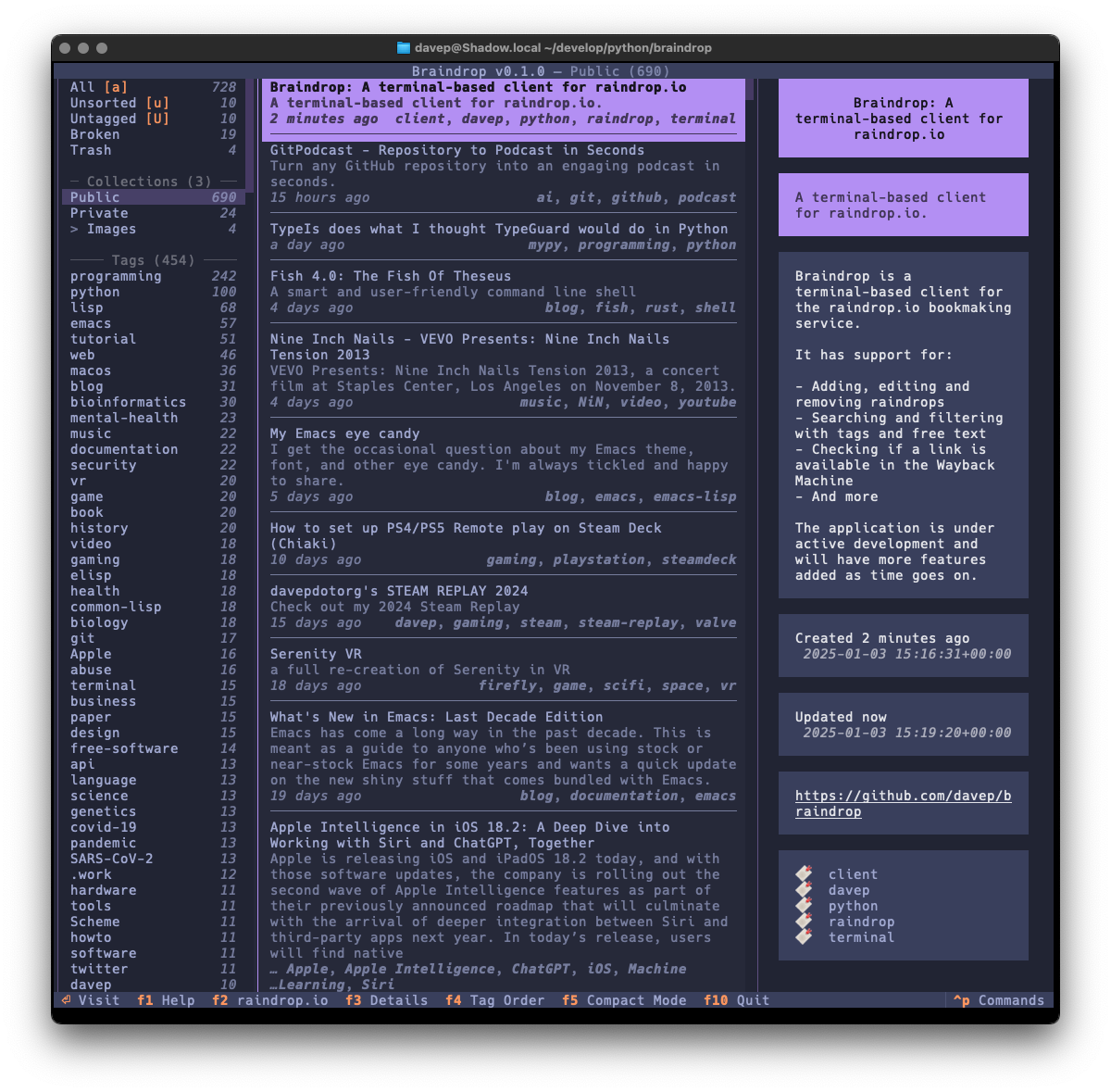
As much as possible I've tried to keep the look and feel similar to that of Tinboard, while also doing my best to avoid some of the "ah, I wish I hadn't done it this way" design decisions I'd made. As of the time of writing I'm very pleased with the result.
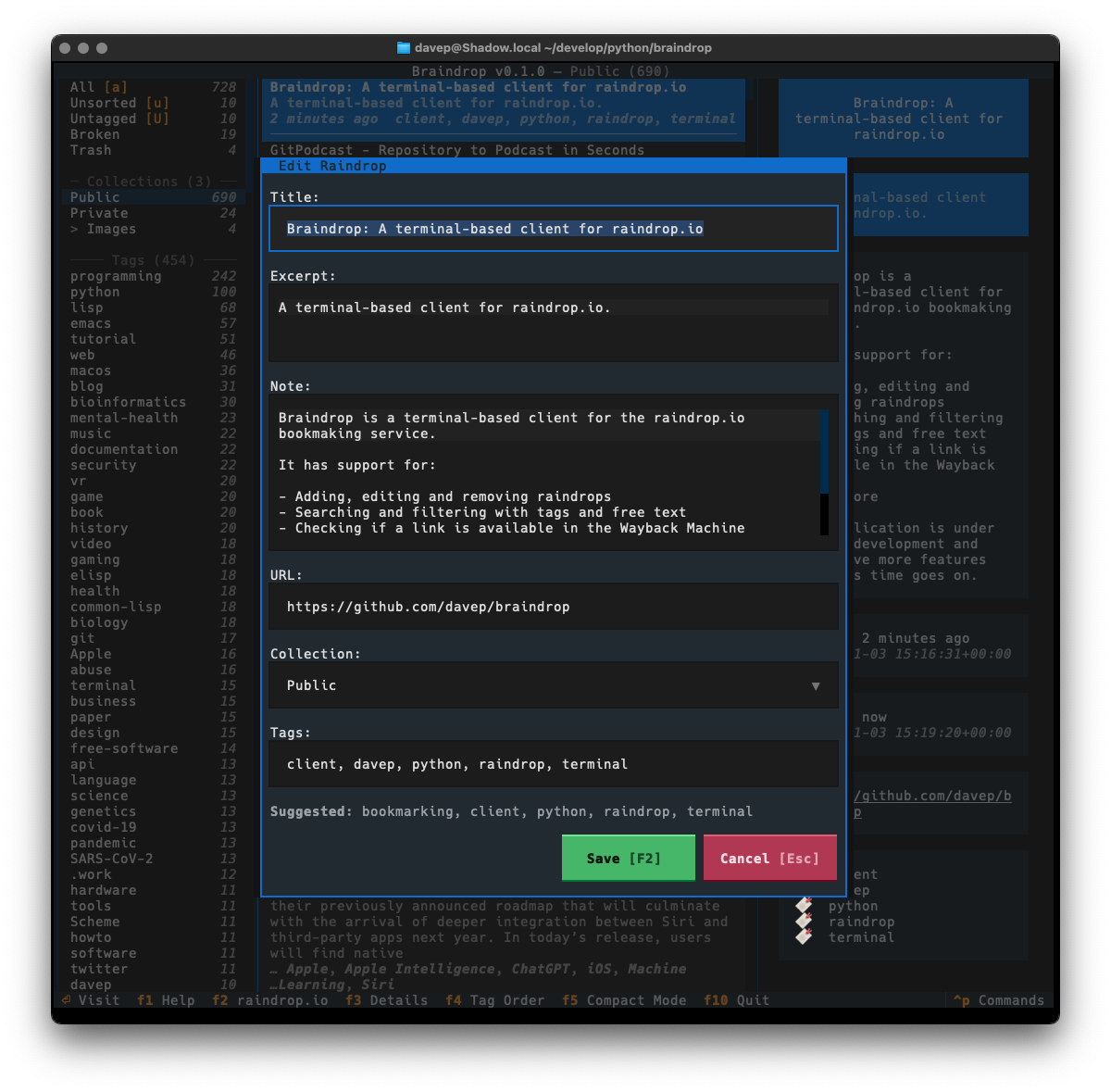
One thing I did want to do is ensure that the application was as keyboard-friendly as possible, while also still allowing use of the mouse. Textual can sometimes get that wrong and I ran into an example of this while trying to ensure that there's good in-application help. Somewhat recently Textual added a built-in help system which, sadly, can't easily be used by and navigated by someone using the keyboard. So instead I've recreated the help system I built into Tinboard, while adopting the documentation standard that Textual had settled on (which, coincidentally, was kind of similar to what I did in Tinboard to start with).
As with Tinboard, I've also made sure to make full use of the command palette, with every action that makes sense having a keyboard hotkey as well as a command in the palette. I also took things a little further and made sure that the hotkeys are shown in the command palette for easier discovery.
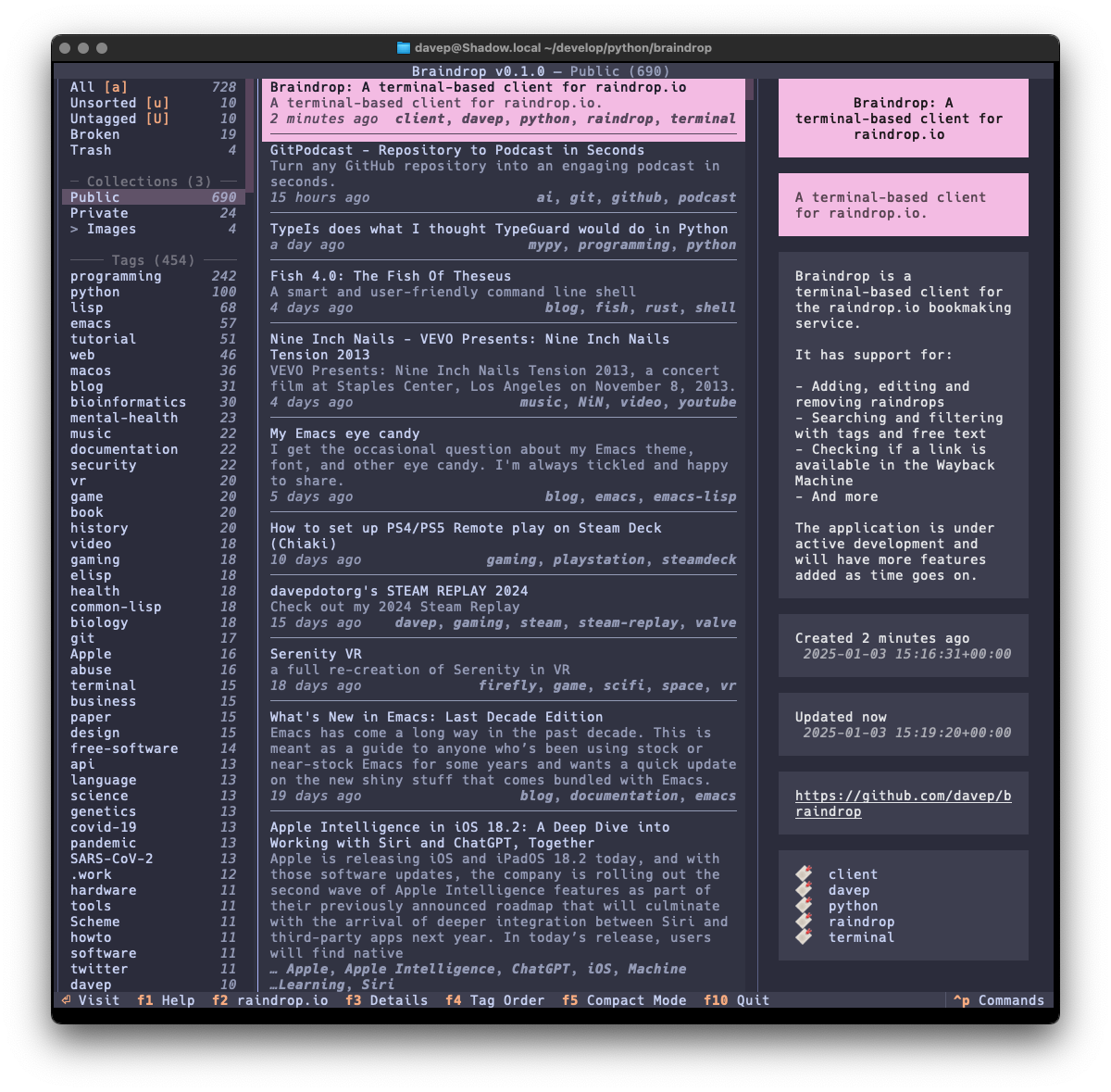
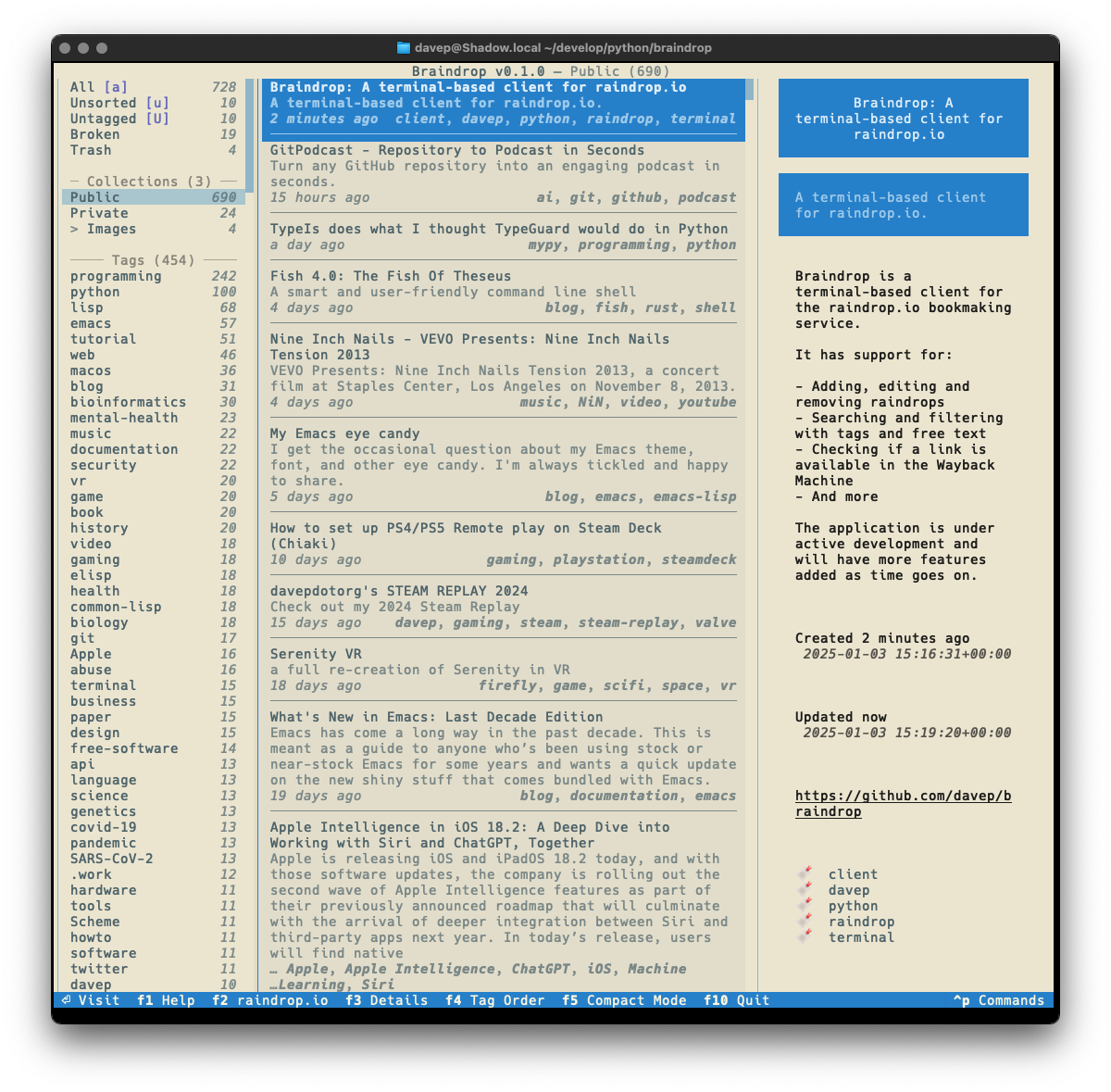
I've also made sure that Textual's new theme system is available for easy use; so out goes dark/light mode toggling and in comes a collection of different themes. Here's a wee selection as an example:
That's a small selection of the themes, with more to explore.
There's a few more things I want to do before I consider the application v1.0-ready, but it's already in use by me and working well. As I decide what else I want to add to it I'm building up a list of TODO items.
Given that my day job these days is quite varied, isn't quite so coding-intensive, and isn't always related to all things Python, it's actually been fun to sit down and hack up a pure Python application from scratch again. It's also helped me discover a couple or so fresh bugs in Textual (which I've reported, of course) and given me the opportunity to PR some trivial fixes as I've noticed typos and stuff as I go.
Anyway; that's v0.1.0 out in the wild. I'm pleased with how it's turned out and there's more to come. It's licensed GPL-3.0 and available via GitHub and also via PyPI. If you have an environment that has pipx installed you should be able to get up and going with:
pipxinstallbraindrop
It can also be installed with Homebrew by tapping davep/homebrew and then installing braindrop:
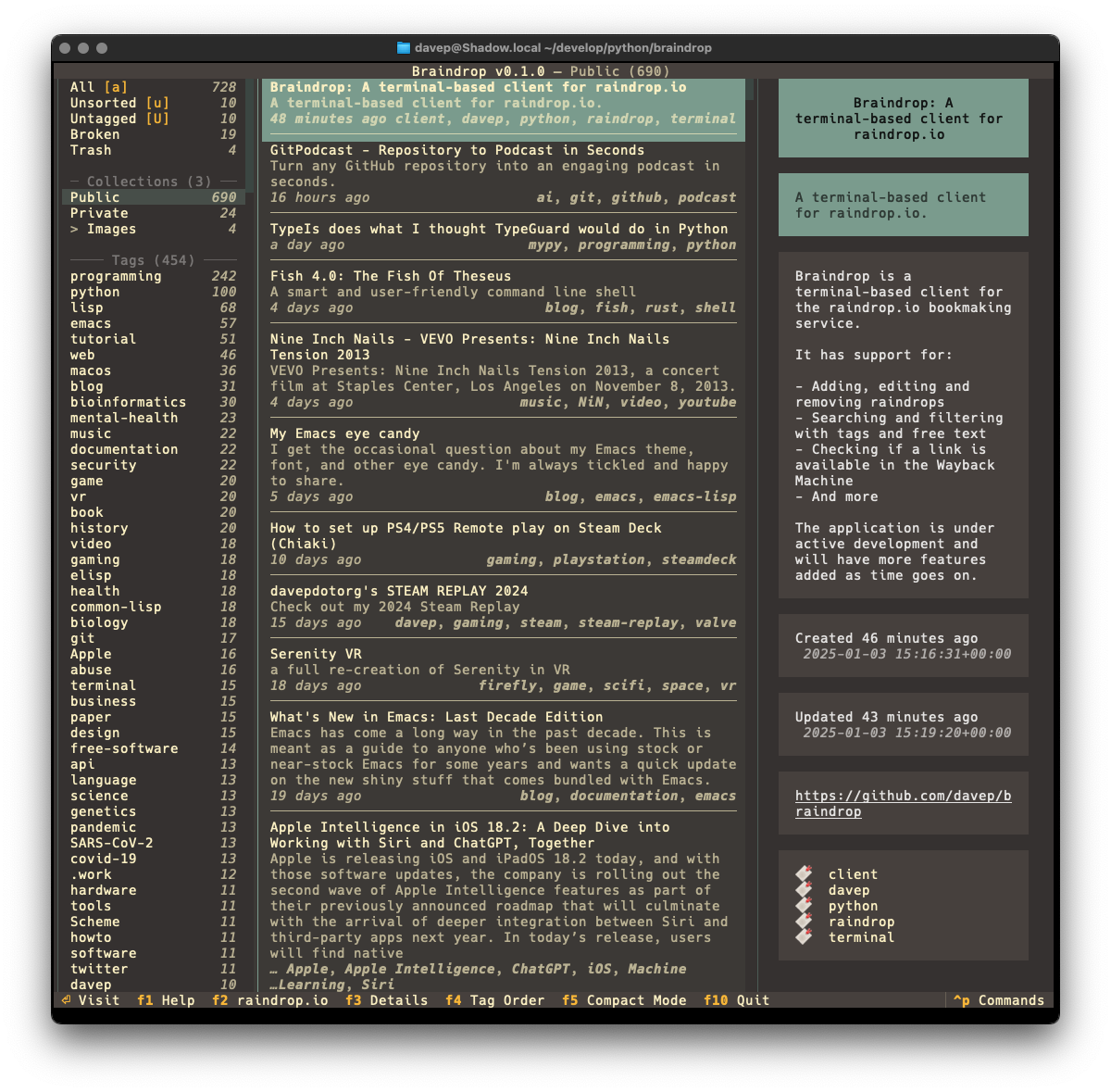
I've just released Tinboard v0.14.0. This release adds a feature that a user requested, where you can set the default values for the privacy and read-later status of a new bookmark:
So, any time you create a new bookmark, the edit dialog will use those values by default. It's a feature that makes perfect sense but I didn't think to add it early on because... well, I set the defaults to my preference.
Tinboard can be installed with pip or (ideally) pipxfrom PyPI. It can also be installed with Homebrew by tapping davep/homebrew and then installing tinboard:
Tinboard has turned into a tool I use pretty much every day; it's probably my most-used Textual/Python-developed application at this point. This is causing me to think more and more about how I can add things to it that are related to the core purpose, but are also outside of the main "interface with Pinboard" thing.
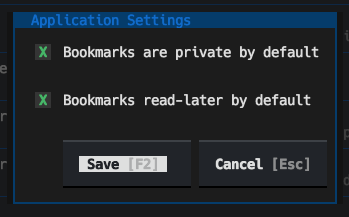
A thing with keeping bookmarks for a long time is that some of them go stale, go away. Some will just plain 404, others the whole site will disappear. If I find myself going back to a bookmark and seeing this is the case, I'll hit the Wayback Machine and see if there's an archive there.
So I got to thinking: what if I add the ability to perform this check into Tinboard itself? So I did just that.
Now, in the application, if you press w with a bookmark highlighted, it will check with the Wayback Machine to see if the bookmark is in the archive. If it isn't you see this:
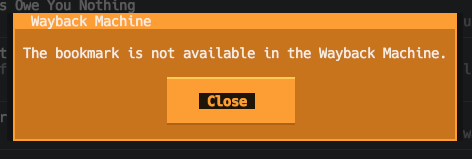
On the other hand, if it is in the archive, you'll see something like this:
I sense this is going to be the first step in a couple of features related to this. I'm thinking that I may go on to add a "swap the URL for this bookmark with the Wayback Machine archive URL" feature, which will be handy for those bookmarks that have one away, and it would also be useful to look at the options for a "please archive a copy of this bookmark" feature.
But, for now, v0.12.0 is available and has this handy (for me anyway) first step.
Tinboard can be installed with pip or (ideally) pipxfrom PyPI. It can also be installed with Homebrew by tapping davep/homebrew and then installing tinboard:
The initial version was pretty much a quick hack; during that dogfooding period I did my best to try and develop a new project every couple of days. Since then I've let PISpy descend into bit rot.
This morning I put the finishing touches to these changes and released v0.6.0.
PISpy can be installed with pip or (ideally) pipxfrom PyPI. It can also be installed with Homebrew by tapping davep/homebrew and then installing pispy:
In doing so I extended the application so that it's possible to run tinboard add and quickly enter a new bookmark and then carry on in the terminal, without needing to "go fullscreen". I'll admit it's of limited use, but it seemed like a good shakedown of the feature and in working on it I was able to discover a couple of bugs (#4385, #4403).
The effect of this is this:
Tinboard can be installed with pip or (ideally) pipxfrom PyPI. It can also be installed with Homebrew by tapping davep/homebrew and then installing tinboard:
I just realised that it's been a while since I last posted an update about tinboard. This is probably my most-used Textual-based application, and one I'm constantly tinkering with, and just this morning I published v0.10.0.
Often the changes are small tweaks or fixes to how it works, sometimes they're simply updates to the version of Textual used, making use of some new feature or other; I've yet to add another "major" feature so far. They will come, but so far the ideas I have for the application haven't actually felt that necessary. Although I say so myself it does what I need it to do and it does it really well.
So, as a quick catch-up of what's changed since v0.4.0 (which was the last version I posted about):
v0.5.0 was released 2024-01-04; this included all the tags of a bookmark when doing full-text searching.
v0.6.0 was released 2024-01-10; it fixed a small bug where the tag suggestion facility got confused by trailing spaces in the input field.
v0.7.0 was released 2024-02-02; this updated the minimum Textual version to v0.48.2 and removed all the custom changes to the Textual TextArea widget, making use of the updates to TextArea that version of Textual made available.
v0.8.0 was released 2024-02-18; this fixed a crash on startup caused by a newer release of Textual (the fault was in tinboard; the update to Textual helped reveal the problem).
v0.9.0 was released 2024-02-29; it simply added support for using Esc at the top level of the application to quit (I like to camp on Esc to GTFO).
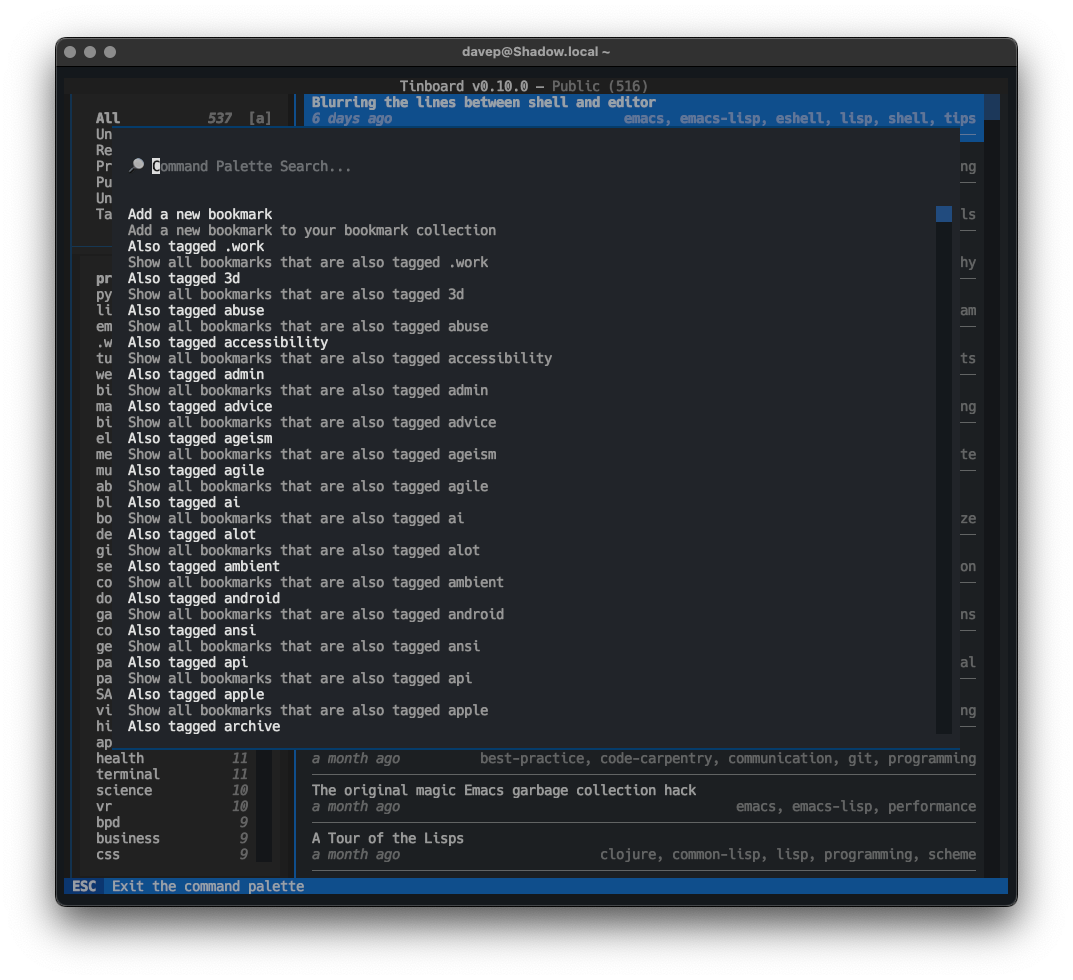
Then, just now, I released v0.10.0. This release makes full use of some work I recently did to enhance Textual's CommandPalette widget, which added a "discover" system. The change in tinboard is that all of the command palette providers now have discover methods too. The result of this change is that when you open the command palette in tinboard (ctrl+p) you can see every possible command right away.