A quick update carrying on from this morning's release: as mentioned towards the end of the post, there was a small problem with the lint command where it would raise an error if a page or post linked to any page related to the new series feature.
v2.40.1 fixes this. The linter now knows about the series feature and the URLs it creates.
It's hardly a novel feature, plenty of blog engines support this sort of thing; I felt it was high time I added it to BlogMore too. The idea is simple: while categories provide a method of having "sub-blogs" within a blog (they also provide their own feeds), and while tags let you group together posts that touch on related subjects, a series will let you stitch together a collection of posts as directly relating to each other.
Adding a post to a series is as simple as adding a series to the frontmatter of a post.
title:Five days with Copilotcategory:AItags:Python, AI, LLM, Copilot, GitHub, BlogMore, codingdate:2026-02-20 15:46:00 +0000series:Agentic Afterthoughts
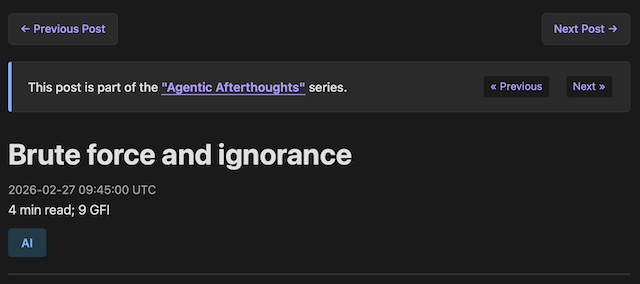
With this done, when a reader is viewing an individual post that is within a series, some new navigation appears at the top and bottom of the post that lets them know about the series, and also offers them easy navigation to the previous and next posts.
Also, if the reader were to click on the series title, it will take them to an archive page for that series, where the posts are presented in the usual pagination format, but where they're also presented in series order. To be clear: series order is always chronological order.
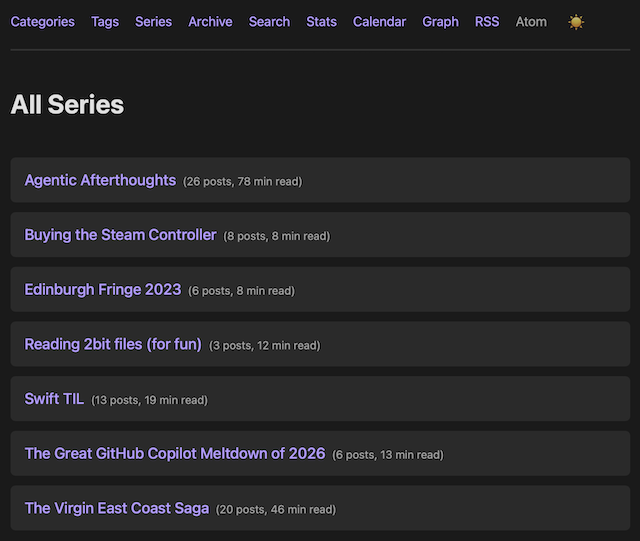
To help encourage further post discovery, if one or more series are available, a new Series link appears at the top of the blog. This links to an index of every series available.
Sorted in alphabetical order, the list also shows how many posts are in each series and, if reading time is turned on, the total reading time will be shown.
Worth noting is the fact that a post doesn't have to be restricted to just one series. If you need a post to be in two or more series, you can provide the series as a list:
title:My post that crosses the streamscategory:Testingtags:BlogMore, Series, Testdate:2022-02-22 22:22:22 +2200series:-Experiments with blogging-Eating my own dog food-Testing thing
The post will then show navigation for every one of those series, and the post will be in each series' archive page.
Having added this, I've also updated the output of the dump command so that series (the series list as provided in the frontmatter), safe_series (the series list in their URL-friendly slug forms) and series_pair (a list of series title and slug pairs) properties are available.
As of the time of writing this, I have noticed one issue. The linter isn't currently aware of the URLs that are created as part of the series facility. So if you have a page or post that links to the index, or links to a particular series, there will be errors:
blogmore lint
Linting site in content...
ERROR: posts/2026/06/2026-06-06-blogmore-v2-40-0.md: Link points to non-existent internal path: /series/ (resolved to /series/)
ERROR: posts/2026/06/2026-06-06-blogmore-v2-40-0.md: Link points to non-existent internal path: /series/ (resolved to /series/)
ERROR: posts/2026/06/2026-06-06-blogmore-v2-40-0.md: Link points to non-existent internal path: /series/the-virgin-east-coast-saga/ (resolved to /series/the-virgin-east-coast-saga/)
Linting complete: 377 post(s), 4 page(s), 3 error(s), 0 warning(s) [0.45s].
This should be a straightforward fix which I'll make in a follow-up release.
BlogMorev2.39.0 has a couple of changes, one more or less cosmetic, the other a new feature that I probably should have added right near the start of the project.
First, the cosmetic: in pages and posts, when you use headings (#, ##, etc.), a ¶ is added to the end of each heading, along with some show-on-mouse-hover styling, to make it easy to grab the anchor of a particular section of a page1. A problem I'd noticed with this recently is that the ¶ shows up in the search text, and also in the content of all the feeds. While not a problem as such, it felt untidy.
So, with this release that particular ¶ character is stripped from the search index and from the feeds.
The second change is a facility that should be useful if you have legacy URLs that you really must have land on an actual page or post: redirection support.
This facility is provided by a new redirect_from frontmatter property. From now on, a page or a post can declare which URLs should be redirected to it. So, if you have a post that, given your current post location setup, would land at /2006/06/06/hello-world/, but in some other incarnation of your blog lived at /posts/2006-06-06-hello-world.html, you can now set this in the frontmatter:
redirect_from:/posts/2006-06-06-hello-world.html
and the old URL will be redirected to the new one. This is achieved by simply creating a very minimal HTML file at the old location, which contains a redirection. The content of the file will end up looking something like this:
<!DOCTYPE html><html><head><metacharset="utf-8"><title>Redirecting...</title><linkrel="canonical"href="https://example.com/2006/06/06/hello-world/"><metahttp-equiv="refresh"content="0; url=/2006/06/06/hello-world/"></head><body><p>Redirecting to <ahref="/2006/06/06/hello-world/">/2006/06/06/hello-world/</a>...</p></body></html>
If a blog has migrated between locations and/or generation tools over the years, and there are a number of different legacy URLs out there still pointing to a post you really want to keep readable to all, you can also redirect from multiple URLs:
While all of this would have been possible anyway, by creating the appropriate file, with the appropriate content, in the extras directory, this approach helps automate the process and also means that the redirection information lives with the page or post being redirected to.
BlogMore has been bumped to v2.38.0. This release includes a small cosmetic change to the stats page, and also adds a fairly big cosmetic feature with some comprehensive control.
First, the change to the stats page: here I've changed the formatting of numbers a little so that numbers that are in the thousands or higher get better formatting. So rather than a count of something being 1234 it'll now display as 1,234. Hardly a groundbreaking change, but something I'd omitted some time ago and yesterday evening it came to mind. This should make the stats page just a little easier on the eye.
The second change is a reasonably big one, with some extra configuration file and frontmatter additions.
BlogMore has long supported auto-generation of a table of contents in the body of a post by including a [TOC] shortcut. Generally I'm not a fan of using this approach, but I can see the utility. Yesterday evening I added a new approach to showing a table of contents that means you don't need to have the list of links within the post.
Starting with this version, if a page or post has one or more headings in it, a table of contents will appear in the "dead space" on the right-hand side of the page, like this:
This follows the same kind of style as is used for the year and month index in the archives page. However, whereas in the archives the index just disappears (by design) if you're on a smaller screen, this new table of contents will switch to being inline in the page or post, in a form that is collapsed:
If the user clicks on it, it expands:
Given that this is a fairly big cosmetic change that could affect many pages and posts on a blog, I've built in as much control as makes sense. This new ToC approach is on by default, but can be turned off. First off, there is a show_toc configuration file setting which controls if the feature should be on or off, by default, site-wide. It is set to true by default.
Because there might be times where you want to control this at the page or post level, there is also a show_toc frontmatter property too. This always overrides the global setting in the configuration file.
On top of this, I can imagine that someone1 might also want to have the right-side floating ToC, but never have the inline ToC showing on smaller displays. With this in mind I've also added a show_toc_inlineconfiguration option and frontmatter property. These just control if the inline version of the ToC will ever be shown. To be clear: if the ToC is disabled (either site-wide or via a specific page or post's frontmatter), this inline-specific setting is ignored -- the ToC will never show. But if show_toc is true then show_toc_inline controls if the inline ToC ever appears on smaller displays.
I fear I might have made it sound more complicated than it is. Apologies if that's the case. I'm confident that someone needing this level of control will make sense of it easily enough.
Also, just to be clear: the [TOC] shortcut is totally unaffected by any of this. If you have [TOC] in your post, that version of the table of contents will always be generated. I didn't think it made sense to override that explicit markup choice.
I've just released BlogMorev2.37.0. This is a small update that fixes a bug and also improves the way that warnings and errors are emitted.
The bugfix comes from yesterday's post where I noticed that the stats page was misreporting the number of tags on the blog. The cause of the problem was that, within reason, a single tag can be represented in a number of different ways. In the tags frontmatter you could write any of Python Coding, Python coding, python coding, Python-Coding, etc and they would all be seen as the tag python-coding. This gives some useful flexibility and also ensures that the actual tag is URL-safe.
The problem was that the stats page was counting the list of unique tags, as they were typed into posts, rather than the unique list of "made safe" tags. So that is now fixed, along with categories too.
The other main change in this release is that warnings and errors that might get printed during post parsing and other operations are now printed to stderr. Until now everything was simply printed to stdout, which was fine until I introduced the links
dump and main dumpcommands. With the addition of those commands, you're far more likely to want to redirect the output to a file. So if there's some sort of warning when parsing a post, that would get dropped into the middle of the JSON output (if using dump), resulting in a JSON file that can't be parsed.
Another quick update to BlogMore: this time doing a little bit of tidying up in support of my use of it over on my photoblog.
The new items I've added to the stats page are working out really well, but over on the photoblog they were lacking a bit in a couple of areas. Because no post on the photoblog has any body text -- it's just title, category, tags and image -- things like the word count and yearly focus didn't really have any content. The minimum and maximum word counts were zero, and every single year of the span of the blog had no focus whatsoever.
To clean this up I've made it so that the word count section just doesn't show at all if the minimum and maximum word counts are both zero. I've also changed how the corpus of words for the yearly focus works too. If a particular post has no body text, the text that is used falls back to using the title of the post and the tags. With that change, the yearly focus list for the photoblog goes from being completely empty, to looking quite informative.
One other change in v2.36.0 is a small fix to headings as they appear in user-supplied pages. While it was possible to grab an anchor for a heading so you could link to it, the ¶ character that should appear on hover, to help make this obvious, wasn't appearing on those pages. That's now fixed.
Well, I wasn't expecting to release a new version of BlogMore quite so soon, given I made a release earlier today. But an issue came in that the Bluesky icon wasn't showing in the socials section on someone's blog, despite the fact that the docs suggested it should work.
It's interesting to note that Copilot/Claude (which is what did this work originally) produced one thing in the code, and then made an unsupportable claim in the documentation. Furthermore, it didn't construct the tests to at least match the documentation's claims. None of this is a surprise, of course, but it is a good illustration of the fact that agent-based coding is just fancy auto-complete with no real ability to maintain a coherent view of the whole project.
Anyway, v2.35.0 is now available and I too can have a Bluesky link in my socials. Oddly, I hadn't thought to add it before now.
The first change is a small fix to the url_path property, which wasn't being populated; now it is.
The second change adds two new properties to the output which relate to links that can be found inside posts: internal_links and external_links. As the names suggest, the first gives you a list of all the internal links that can be found in a given post, with the values given being the same format as the id used for every post in the dump. For example:
There is, of course, some overlap with the link dumping command, but given that the information is available it seemed to make sense to provide it here; it also means that it's available in a more structured form.
Also providing this sort of information in the JSON output means there's a lot of flexibility when it comes to analysing all the posts in my blog. For example, I can now easily satisfy my curiosity if I want to know exactly which posts in my blog have no links whatsoever.
I've released v2.33.0 of BlogMore, which extends the stats page some more, and also adds a tool so a user can do all sorts of fun things with the raw data of their posts.
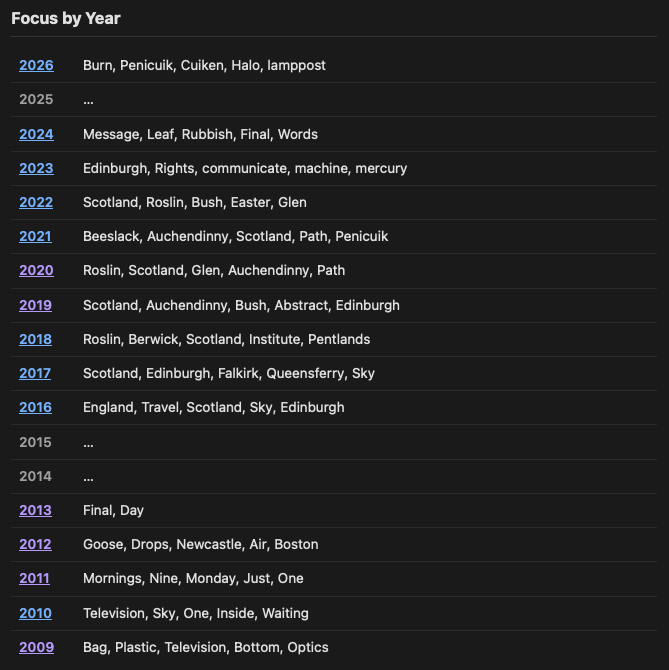
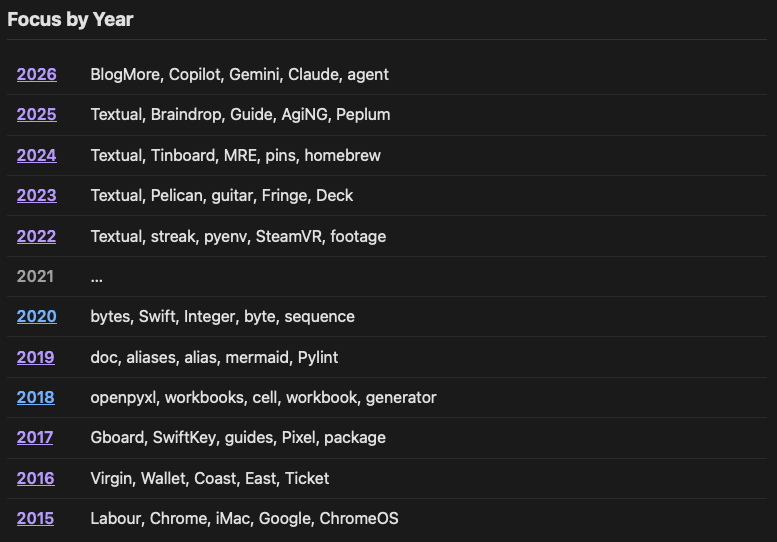
The addition to the stats page is a list of years along with the top five words that characterise the focused subject for those years. This is done using TF-IDF. While the results for my blog don't come as a surprise, I am pleased to see that it does turn out pretty much how I would have expected:
This feels like another fun way to learn something about the post history for your own blog.
Which got me thinking: there's probably any number of other niche and bizarre things that could be done with the content of a blog to gain some insight as to its history, and I really shouldn't just keep adding more and more things to the stats page. But what if I wanted a way to run some code over all the posts? Wouldn't it be useful if I could get all of the parsed post data in JSON format so I can play with it?
With that idea in mind, I added the dump command. When run, it will print to stdout a full dump of all of your posts, as JSON, so you can then write your own nifty tool to read it back in and do any number of interesting checks, tests, reformats or manipulations. For example, if I wanted to use jq to pull out the metadata for this particular post I could:
I can see this being pretty useful to blogmore.el at some point, if I want to add some better querying tools or similar (not that I'd want to run a dump every time, it does require that a full parse and render has to happen).
Hopefully this will be useful to someone else. I know I'll be toying with it to find out other things about my posting history.