I first learnt Python back in the mid-to-late 90s, used it in place of Perl once I was comfortable with it, and then we sort of drifted apart when I first met Ruby. It's only in the last couple of years that I've got back into it, and in a huge way, thanks to my (not-quite-so-) new job. Despite the quirks and oddness (as I perceive them), I actually quite like Python and it's one of those languages that just flows off my fingers. I'm sure you know the same thing, perhaps not with Python, but there will be languages that just flow for you, and those that take a bit more effort and concentration. Python... feels okay to me.
I also appreciate that there's been a long-standing style guide. I quite like PEP 8 as a read, and think there's a lot of good ideas in there; much of the content sits with how I'd approach things if I was tasked to come up with such a document. With this in mind, I'm a fairly heavy user of pylint and it in turn leans on PEP 8 (amongst other things) and I'm happy to accept most of its judgements. Not all of its judgements, but even when I disagree with it I try and keep track of how far I'm drifting.
But there is absolutely one hill I will happily die on when it comes to PEP 8: the concept of "extraneous whitespace" in lists and expressions. Just.... no! Oh gods no!
To borrow a line of code from the journey problem I dabbled with a while back, PEP 8 would have me write something like this:
def perform(commands: List[str],state: State) -> State:
Now, I'm sure plenty of people won't see a problem with this at all; but all I can see is an almost-claustrophobic parameter list. What's with the parameters being jammed up against the opening and closing parens? Why have the dinky little comma lost between two different things? Why have it look like a long stream of letters and punctuation? Why....
No.
Just no.
I can't.
Rightly or wrongly, I just need for the code to breathe a bit. When I type this:
def perform( commands: List[ str ], state: State ) -> State:
suddenly if feels like there's fresh air in the code, like it flows gently out of my head, off my fingers, through the keyboard and into the buffer.
In my head, and to my eyes, the code is.... relaxed.
Do I have a rational reason for this? Nope. Then again I don't see one for doing it the other way either; I can't think of one and I don't see one in the source document. So, that's a warning I always turn off with pylint and it's a style I carry through all my Python code; and I think that's the important point here: anyone reading and working with my code should see the same style all the way through. It might differ from PEP 8 on this point, but at least it's the same all the way.
And, really, that's okay: PEP 8 is there to be ignored. ;-)
PS: This is a small part of another blog post I was meaning to write, and might still do, about my (still ongoing) experience of getting lsp-mode up and running in Emacs and having it play nice with Python projects. I have that working, but it was a bit of a learning curve and epic battle over a couple of days, and one that had me first encounter pycodestyle. I may still tell the tale...
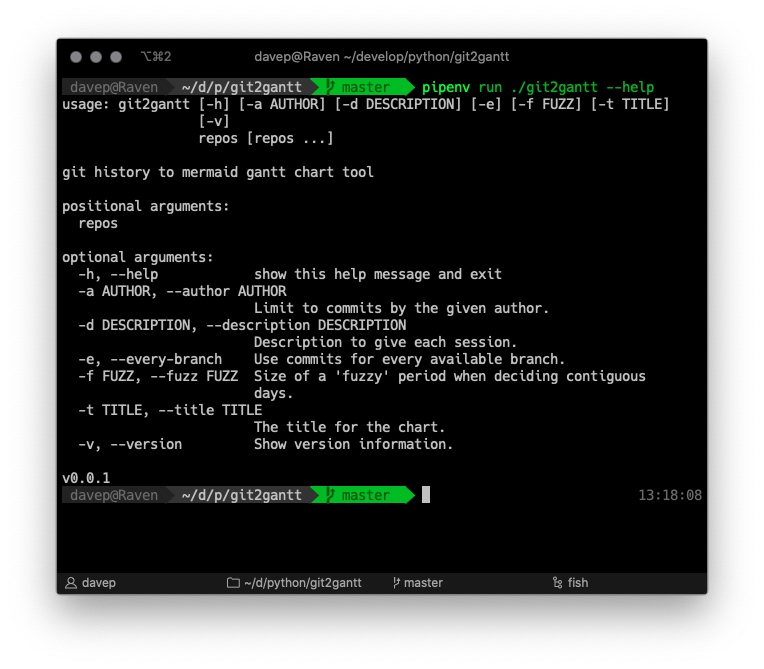 As you can see, it can be run over multiple repos at once, and there's also an option to have it consider every branch within each repository. Another handy option is the ability to limit the output to just one author -- perhaps you just want to document what you've done on a repo, not the contributions of other people.
As you can see, it can be run over multiple repos at once, and there's also an option to have it consider every branch within each repository. Another handy option is the ability to limit the output to just one author -- perhaps you just want to document what you've done on a repo, not the contributions of other people.