Following on from this morning's initial experiment, I think I'm settling on a winner. Rather than be annoying and have you scroll to the bottom to find out: it's Gemini CLI. Here's how I found the process played out, and why I'm settling for one over the other.
Gemini CLI¶
Initially this was an absolute mess. After letting it initially work on the problem, the resulting code didn't even really run. The first go, and the three follow-up prompt/result cycles that followed, all resulted in code that had runtime errors. I'm pretty sure it didn't even bother to try and do any adequate testing. This is odd given I've generally seen it do an okay job when it comes to writing and running tests.
Once I had the code in a stable state, with all type checking, linting and testing passing, it still didn't work. No matter how I tried to use the new facility it just didn't make a difference. No images were optimised. In the end I dived into the code, with the help of its attempt at debugging (it added print calls to try and get to the bottom of things -- how very human!), diagnosed what I thought was the issue (it was looking in the wrong location for the files to optimise), told it my hypothesis and let it check if I was right. It concluded I was and fixed the problem.
Since then I've had a working implementation of the initial plan.
Once that was in place it's been a pretty smooth journey. I've asked it questions about the implementation, had my concerns set to rest, had some concerns addressed and fixed, improved some things here and there, added new features, etc.
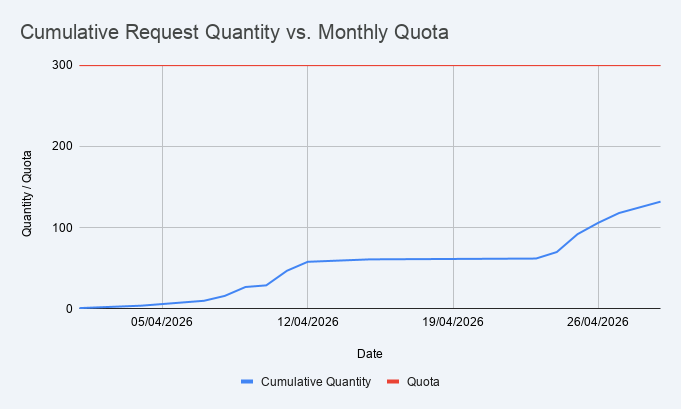
All of this has left me with 18% of my daily quota used up. While I think this is the highest I've ever got while using Gemini CLI, it still feels like I got a lot of things done for not a lot of quota use.
GitHub Copilot¶
Initially I thought this had managed to one-shot the problem. Once it had finished its initial work the code ran without incident and produced all the optimised files. Or so I thought. Doing a little more testing, though, it became clear it was only optimising a subset of the images and it didn't seem to be producing the actual HTML to use the images.
On top of this it didn't even follow the full plan that was laid out in the issue it was assigned. For example: once I'd got it doing the main part of the work, it became apparent that it had pretty much ignored the whole idea of using a cache to speed this process up. I had to remind it to do this.
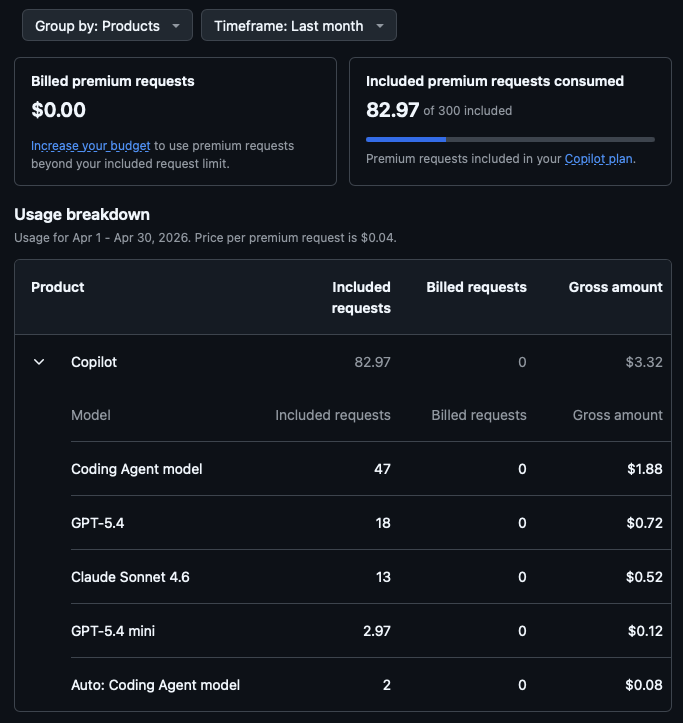
At one point I switched from the in-PR web interaction with Copilot, and used the local CLI instead. When I ran that up it warned me that I was already 50% of the way through some sort of rate limit and this wouldn't reset for another 3 hours. I think I was about 40 minutes into letting it try and do the work at this point.
After a bit more testing and follow-up prompts, I got to a point where I had something that looked like it was working; albeit in a slightly different way from how Gemini CLI did it (the Copilot approach was writing the optimised images out to the extras directory, mixing them in with my own images; Gemini opted for having a separate directory for optimised images within the static hierarchy).
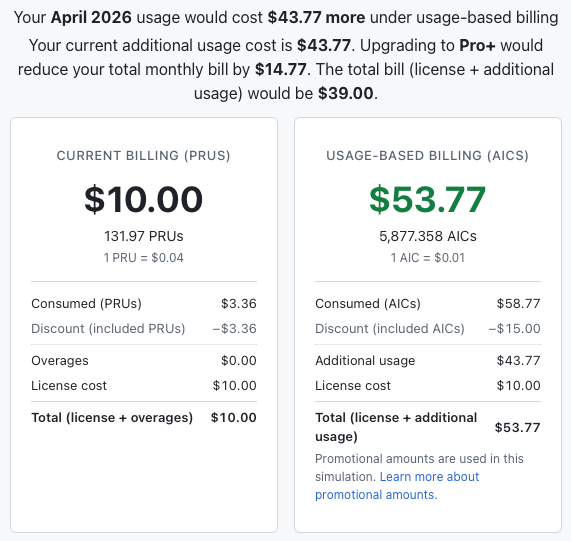
At this point I will admit to not having carefully reviewed the code of either agent; that's a job still to do. But while Gemini got off to a very rocky start, with a bit of guidance it seemed to arrive at an implementation I'm happy with, and one that seems to be working as intended. While it didn't anticipate all the edge cases, when I asked about them it easily found and implemented solutions for them. Moreover, the fact that I could do all of this and confidently know the "cost" made a huge difference. Copilot seems to generally approach this like a quota or rate limit should be a lovely surprise that will destroy your flow; Gemini has it there and in front of you, all the time.
As for the general idea that I'm working on: I think I'm going to implement it. Weirdly I'm slightly nervous about building the blog such that it won't be using the images I created, but I also recognise that that's a little irrational. Meanwhile I'm very curious about the impact this might have on the PageSpeed measurement of the blog. While it's far from horrific, image size optimisation and size declaration seem to be fairly high on the things that are impacting the performance score (currently sat at 89 for the front page of the blog, as I type this).
The other thing that gives me pause for thought about merging this in, and then subsequently using it, is that I've just finished migrating all images to webp, and so saving a lot of space in the built version of the blog. Generating all the responsive sizes of the images eats that up again. With this feature off, the built version of the blog stands at about 84MB; with it on, this rises to 133MB. That extra 49MB more than eats up the 24MB saving I made earlier.
On the other hand: storage is a thing for GitHub to worry about, what I'm worrying about here, and aiming to improve, is the reader's experience.
I'm going to sit on this for a short while and play around with it, at least until I get impatient and say "what the hell" and run with it.