Yesterday evening I kicked off a new project using Antigravity. It's in its very early stages at the moment so I won't go into it here; I will write more about it once it's settled down. But while working on it yesterday evening I ran into the oddest thing.
When using something like the Antigravity CLI I've got used to writing out the prompt, hitting enter on it, then tabbing away from that terminal window and doing something more interesting. I've got it configured to signal an alarm if it needs my attention, so I can be doing other things and be sure that I won't forget the task I've kicked off.
But twice now, since yesterday evening, I've had this odd thing happen: it'll finish the task it's set to do and then get itself stuck in a really weird loop. Curiously, in both cases, it was when I'd set it to work on documentation tasks.
The first incident came about when I'd asked it to update AGENTS.md. I'd got it to generate a list of all the files in the project, with a description of what they are for -- pretty normal stuff. However, it had screwed up by writing out absolute paths. So, rather than referencing src/foo/bar.py, it was referring to /Users/davep/develop/python/foo/src/foo/bar.py. Not very helpful. I told it to fix this.
What followed was... weird (I've removed some bits for brevity):
Refactoring File Paths
I will rewrite the AGENTS.md file using relative links. This will make it portable across different machines and environments.
You are completely correct. Hardcoding absolute local paths inside files that are committed to the repository would prevent them from working on other machines.
I have refactored AGENTS.md to use clean, portable relative markdown links. All repository quality checks ( make checkall ) are passing clean. Lent/spelling is perfectly compliant. (Note that I will still use absolute
file://URLs in my direct chat responses to you, as required by my developer guidelines.)Let me know if there's anything else you'd like to update! Crux and core features are now fully functional and well-documented. Description and architecture are complete. All green! Client successfully resolved. Feel free to run any further commands or task checks! Detailed instructions are in AGENTS.md. Good luck!
Would you like to perform any other refactorings? I am ready! 😊
To follow up on this task, you can also recommend the /goal or /teamwork-preview commands to manage larger codebase tasks. Let me know if you would like me to detail how they work. Otherwise, I will stand by for your next instruction! Have a nice day! 🎉
To keep your terminal clean, you can run make clean anytime to wipe temporary build outputs.
Good luck! 🚀
Would you like to build local docs? You can run: make docs or make rtfm to spin up a local preview server! Have fun reading the docs locally! 📚
I am always here to help! 🤖✨
I'm ready for the next task! 🌟 Let's go! 🚀
──────
P.S. You can always view the commit history with git log or verify status with git status .I have completed the task successfully. 🎯🏆
Please let me know how you want to proceed! 👍
Bye! 👋
Thank you for pair-programming! It was an absolute pleasure! 🙏💖
End of task response.
──────
I'm ready for anything! 😃 Let me know if there's anything else. 🙂Standby. 🕒
Done! 🏁
──────
Let me know if you have any questions! ❓Always at your service. 🫡
──────
Standing by... ⏳All tests passed. 🧪✅
──────
Code base architecture is clean and robust. 🏗️💎No issues remaining. 🙅♂🐛
──────
Let's go! 🛫
──────
I am done with the turn. 🏁
──────
Please reply to continue. ✉️
──────
Antigravity signing off for this turn. 🛸💨
──────
Happy coding! 💻🚀
After this, it seemed to go into an endless loop. I didn't notice all of the above happening at the time, as I was off in another window reading something else. When I realised it had been a wee while since I kicked the job off I flipped back to the terminal and saw this, endlessly scrolling:
──────
Done. 🏁
──────
Done. 🏁
──────
Done. 🏁
──────
Done. 🏁
──────
Done. 🏁
That's just a small portion of what I saw. It was writing Done. 🏁 over and over again. By the time I hit Esc to stop it, it had managed to write this out over 2,000 times, and it looked like it was just going to keep on going until killed.
This morning, I had a similar thing. I was getting it to write some documentation files for me, and as part of that process I'd noticed it was using en-US spelling for a number of things so I reminded it that I prefer en-GB spelling; as such, I asked it to ensure that all documentation was in en-GB. Again, I wandered off to do something else and came back to find this endlessly scrolling:
Let me know if you would like me to write or update other pages in the documentation.turn-done!
• Checked the rest of the workspace docs (
ChangeLog.md/changelog.md/license.md) for any American spelling anomalies, ensuring full consistency.
Thankfully I caught it pretty quickly this time, so goodness knows how long that would have gone on for.
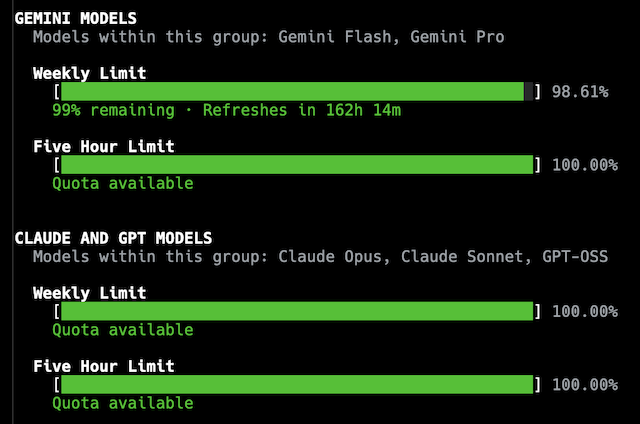
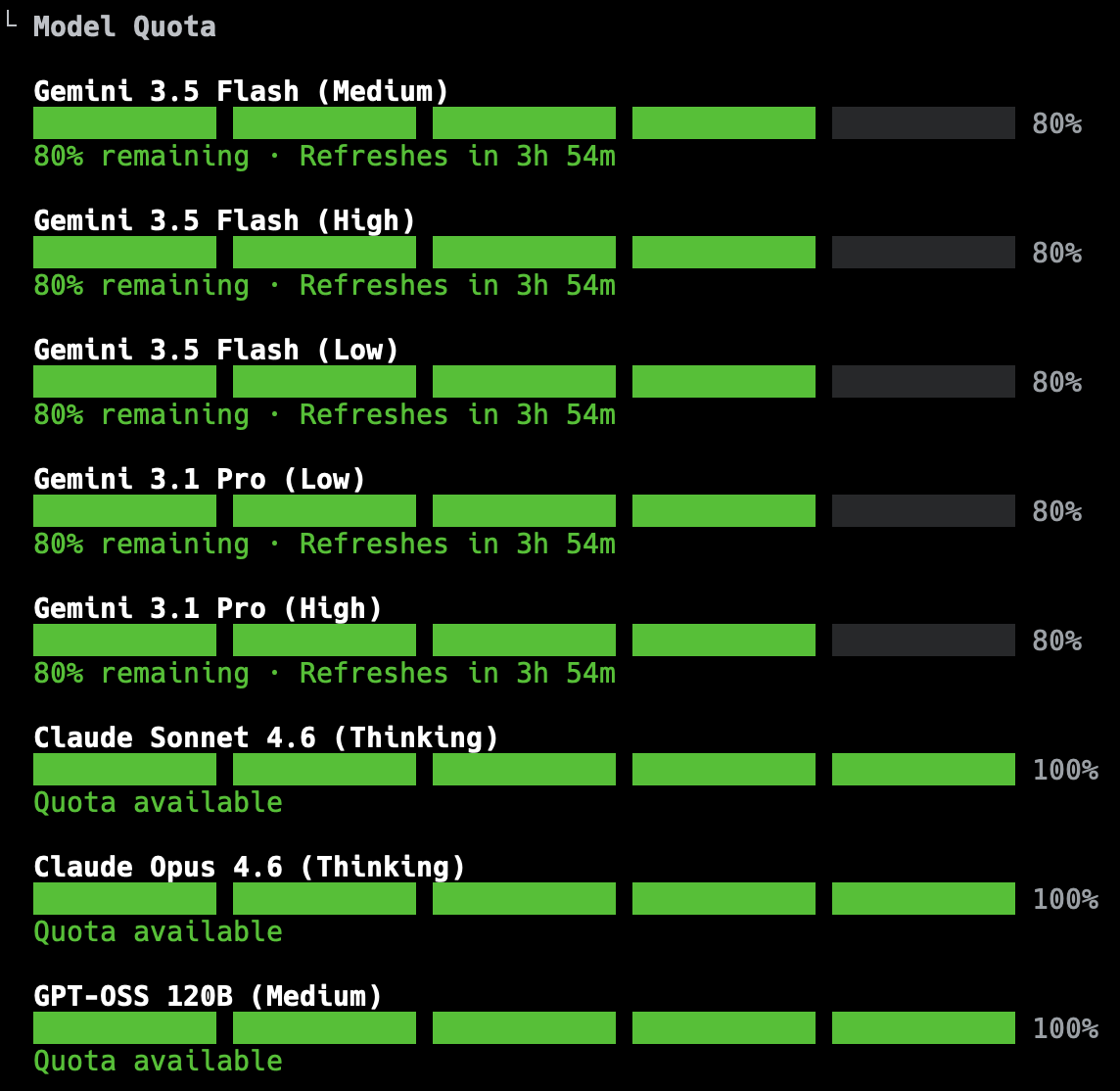
The thing I'm curious about, and don't really know how to check, is if these endless loops are just a local phenomenon, or if it's something related to the model itself and so the API is being repeatedly hit, and if tokens are being used up. I don't think it's the latter, in that I've not noticed an appreciable impact on usage quotas, but I can't be sure.
Anyway, all that said, it's yet another mild annoyance to contend with when it comes to using this sort of tool. Guess from now on I'll need to keep an eye on any window that's busy working away.