As mentioned a couple of times in the last couple of days, aside from one particular issue I found and fixed, I'm in more of a "let's review some of the code and tidy things up" phase with the codebase. This process is at times me hand-making changes, and also in part me directing the agent to make a very specific improvement that I want.
Yesterday evening I did a little experiment of getting Gemini CLI to look for code that really needed some cleaning up, and then I had it write the issue text which I fed directly to Copilot/Claude and had it do the work. Finally, when that was done, I had Gemini review the work that Copilot had done (it was "happy" with the changes).
So, this morning, I thought I'd tackle another little thing I'd noticed in the code that rubbed me up the wrong way. Early on in the development lifecycle of BlogMore I added the optional minification of CSS and JS files (HTML too eventually, but that's not involved here). Because it's often been a convention I also prompted Copilot to ensure that if a file called whatever.css was minified, it be called whatever.min.css.
The resulting code did something that made sense, but which I wouldn't ever have done. The constants that held the filenames looked like this:
CSS_FILENAME = "style.css"
CSS_MINIFIED_FILENAME = "styles.min.css"
SEARCH_CSS_FILENAME = "search.css"
SEARCH_CSS_MINIFIED_FILENAME = "search.min.css"
STATS_CSS_FILENAME = "stats.css"
STATS_CSS_MINIFIED_FILENAME = "stats.min.css"
ARCHIVE_CSS_FILENAME = "archive.css"
ARCHIVE_CSS_MINIFIED_FILENAME = "archive.min.css"
CALENDAR_CSS_FILENAME = "calendar.css"
CALENDAR_CSS_MINIFIED_FILENAME = "calendar.min.css"
GRAPH_CSS_FILENAME = "graph.css"
GRAPH_CSS_MINIFIED_FILENAME = "graph.min.css"
TAG_CLOUD_CSS_FILENAME = "tag-cloud.css"
TAG_CLOUD_CSS_MINIFIED_FILENAME = "tag-cloud.min.css"
GRAPH_JS_FILENAME = "graph.js"
GRAPH_JS_MINIFIED_FILENAME = "graph.min.js"
CODE_CSS_FILENAME = "code.css"
CODE_CSS_MINIFIED_FILENAME = "code.min.css"
THEME_JS_FILENAME = "theme.js"
THEME_JS_MINIFIED_FILENAME = "theme.min.js"
SEARCH_JS_FILENAME = "search.js"
SEARCH_JS_MINIFIED_FILENAME = "search.min.js"
CODEBLOCKS_JS_FILENAME = "codeblocks.js"
CODEBLOCKS_JS_MINIFIED_FILENAME = "codeblocks.min.js"
Like... sure, 10/10 for not hard-coding these all throughout the codebase as magic strings1, but this feels a little redundant. Personally I think I'd have just mentioned the non-minified name and then I'd have a function that generates the minified name from it. While technically, it would add the smallest amount of runtime overhead to the code, I think the single-source-of-truth pay-off is worth it.
For a good while though I left this alone. I was having fun playing with other things in the application, and adding all sorts of other amusing toys. But now that I'm more into a "how can this code be improved and what issues does the code have" mode, it felt like time to tackle this.
Given that a change here would touch so much of the code, and given I wasn't massively keen on spending ages walking through all the code and making the changes related to this, I decided to prompt Copilot to get on with this. It felt like something it couldn't get that wrong.
While it didn't get it wrong, as such, it made some questionable choices along the way. It did do the main thing I would have done: make a function to turn a filename into a minified filename. The initial version looked like this:
def minified_filename(source: str) -> str:
"""Compute the minified output filename for a given source filename.
Transforms the file extension: ``.css`` becomes ``.min.css`` and
``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes
``theme.min.js`` and ``style.css`` becomes ``style.min.css``.
Args:
source: Source filename ending in ``.css`` or ``.js``.
Returns:
The corresponding minified filename.
Raises:
ValueError: If *source* does not end with ``.css`` or ``.js``.
"""
if source.endswith(".css"):
return source[: -len(".css")] + ".min.css"
if source.endswith(".js"):
return source[: -len(".js")] + ".min.js"
raise ValueError(f"Unsupported file extension for minification: {source!r}")
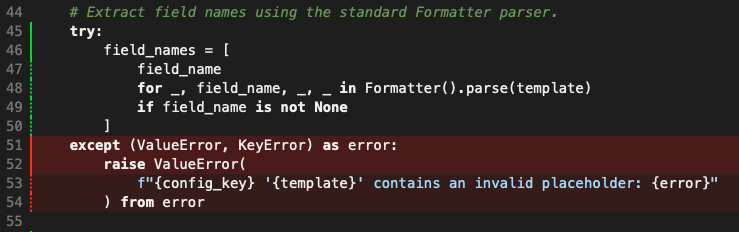
That string-slicing with len and so on is nails on a chalkboard to me. When something like removesuffix exists, why on earth would "you" elect to do this? Of course the answer is obvious, but still... ugh.
Now, I will have to give credit to the process though. So the above was the initial version of the code. Once the PR had been created by Copilot, and I'd pulled it down for review and testing, it kicked off a review of its own. Reviewing its own code, it pushed back on itself:
In
src/blogmore/generator.py, lines 90-93: The slice syntaxsource[: -len(\".css\")]is less readable than usingsource.removesuffix(\".css\"), which is available in Python 3.9+. Since this codebase targets Python 3.12+, consider usingremovesuffix()for clarity.
It then went on to do a further commit to tidy this up. I approve. Bonus point to Copilot here.
So now we have this:
def minified_filename(source: str) -> str:
"""Compute the minified output filename for a given source filename.
Transforms the file extension: ``.css`` becomes ``.min.css`` and
``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes
``theme.min.js`` and ``style.css`` becomes ``style.min.css``.
Args:
source: Source filename ending in ``.css`` or ``.js``.
Returns:
The corresponding minified filename.
Raises:
ValueError: If *source* does not end with ``.css`` or ``.js``.
"""
if source.endswith(".css"):
return source.removesuffix(".css") + ".min.css"
if source.endswith(".js"):
return source.removesuffix(".js") + ".min.js"
raise ValueError(f"Unsupported file extension for minification: {source!r}")
At this point the code is less worse. I don't think it's great, but it's less worse. Honestly, I think I'd be more inclined to do something with PurePath.suffixes and PurePath.suffix, leaning into the fact that we're dealing with filenames here, and so making it less about pure string slicing.
I also have other issues with the code, which I might still fix by hand:
- The fact that it makes a point of only handling
.cssand.jsfiles, and throws an error otherwise, is an odd choice. I mean, in context, that's what it's here to serve, but it seems oddly-specific and an attention to detail that wasn't really necessary. - The hard-coding of
.mina couple of times grates a little. - The hard-coding of both
.cssand.jsa couple of times, with the doubled-upiffeels unnecessary.
It's a small function. It works in context. It does the job. But it also could be more elegant in the way it does it.
I'd also like to go on a small aside for a moment, because there's something else in the above that bothers me: yesterday evening I spent some time directing Copilot to tidy up all the docstrings in the code. While any agent I've thrown at it does seem to have taken note of the AGENTS.md file, and the instructions on how to write the docstrings (Google style please), it seems to have decided it was aiming more at Sphinx when it came to the content. That's fine, I hadn't been explicit.
So last night I made it clear that I wanted something more like I use in all my Python code, that aims to work with mkdocstrings. It should use the inline code and cross-reference styles that are more common when using that tool. I even made a point of telling Copilot to update AGENTS.md to make it clear that this is the preference:
- All inline code and cross-references in docstrings **must** use mkdocstrings-compatible Markdown style:
- Inline code: use single backticks (\`like_this\`).
- Cross-references: use mkdocstrings reference-style Markdown links (e.g., [`ClassName`][module.ClassName] or [module.ClassName][]).
- Do **not** use Sphinx roles (e.g., :class:`ClassName`) or double-backtick code (``ClassName``).
Now go back and look at the docstring for minified_filename. So much for agents making a point of following the instructions from AGENTS.md.
Anyway, back to the main flow here: given that I was thinking that I might rewrite minified_filename by hand so that it works "just so", I made a point of checking that it had written tests for this; something I couldn't take for granted.
Again, to the credit of the agent, it had written some tests:
class TestMinifiedFilename:
"""Test the minified_filename utility function."""
def test_css_extension_becomes_min_css(self) -> None:
"""Test that a .css extension is replaced with .min.css."""
assert minified_filename("style.css") == "style.min.css"
def test_js_extension_becomes_min_js(self) -> None:
"""Test that a .js extension is replaced with .min.js."""
assert minified_filename("theme.js") == "theme.min.js"
def test_hyphenated_css_filename(self) -> None:
"""Test that a hyphenated CSS filename is handled correctly."""
assert minified_filename("tag-cloud.css") == "tag-cloud.min.css"
def test_hyphenated_js_filename(self) -> None:
"""Test that a hyphenated JS filename is handled correctly."""
assert minified_filename("search.js") == "search.min.js"
def test_unsupported_extension_raises(self) -> None:
"""Test that an unsupported extension raises ValueError."""
with pytest.raises(ValueError, match="Unsupported file extension"):
minified_filename("style.txt")
It's a start, but I think it could be done better. There's the test of the intended outcomes, and the test of the ValueError for passing something that isn't a .js or a .css file. Meanwhile, that business of testing "hyphenated" seems oddly specific for no good reason. But it's even worse: the test for a "hyphenated" JS file doesn't use a hyphenated file name.
Hilarious.
That's not all. What about the more obvious things like testing what happens if you pass a filename that has no extension, or a filename that already has two extensions, or a filename that already ends in .min.js, or a filename that has .min.css somewhere in its path that isn't at the end of the name, or an empty string, or...
Also why aren't most of these tests done using pytest.mark.parametrize?
As I said a few days ago: the code is mostly fine. It gets the job done. I've seen worse. I reviewed worse. I've inherited worse. I think the thing that concerns me the most is that there has to be a lot of code like this being uncritically accepted after generation2, which in turn is surely going to be feeding back into future training. So while I can't deny that something has improved in the last six or so months, when it comes to agent-generated code, might it be that we are at peak quality right now? Might it be that from this point on we start to decline as "eh, it's... fine" code starts to overwhelm the most popular forge we have?
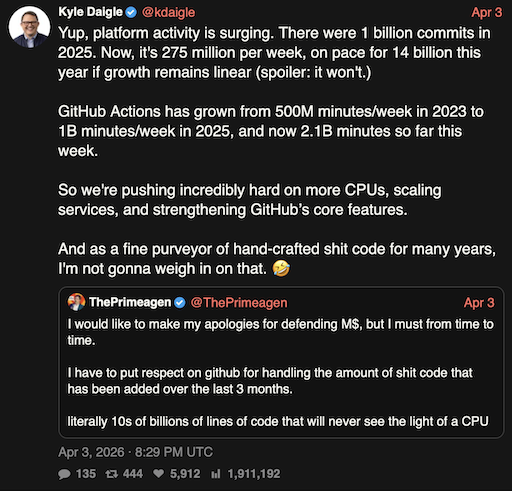
I suppose the main benefit still is that this approach is nice and cheap. Right?