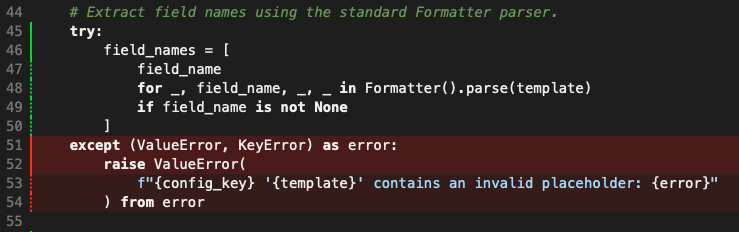
It's a small thing, but here's round 2 of me vs Claude. This time I'm directing the agent to clean up the code that does word counts, getting it to use the Markdown to plain text code that exists in BlogMore, rather than the regex-based Markdown-stripper it was using. The approach it landed on made sense to me, adding another text extractor class, but one that ignores fenced codeblocks1. So, in addition to this code (I've removed all docstrings and comments for the sake of including here):
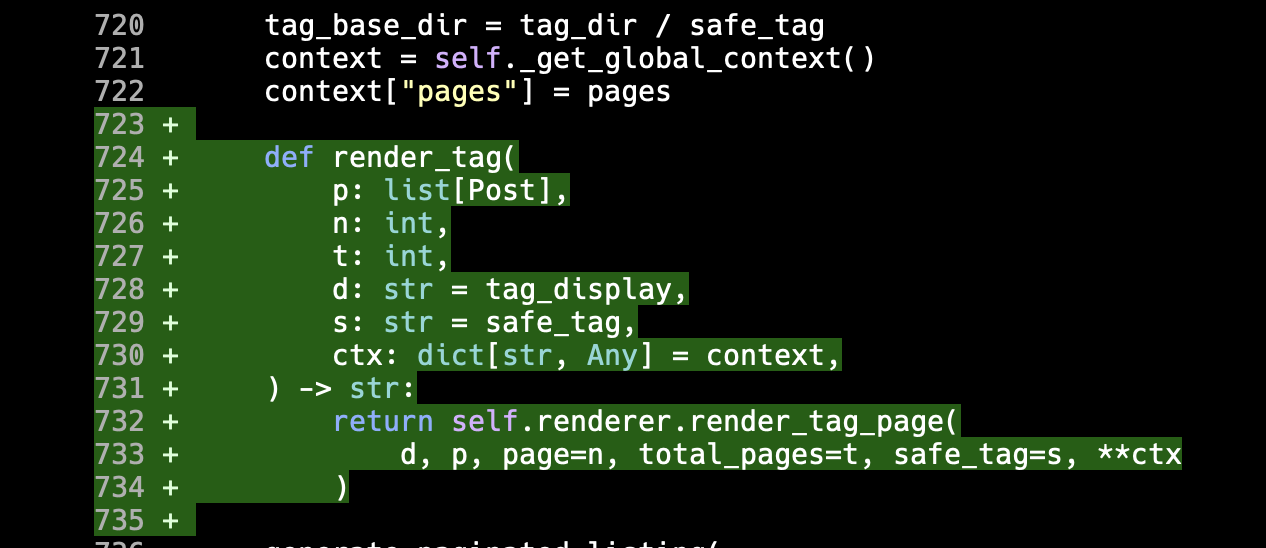
The function that converts Markdown to plain text then decides which extractor to use, based on if the caller asked for codeblocks to be included or not.
All pretty reasonable.
Only... that text property on both those classes is identical. The __init__ method is the same save for one extra line. Even handle_data is more or less the same except for that guarding if.
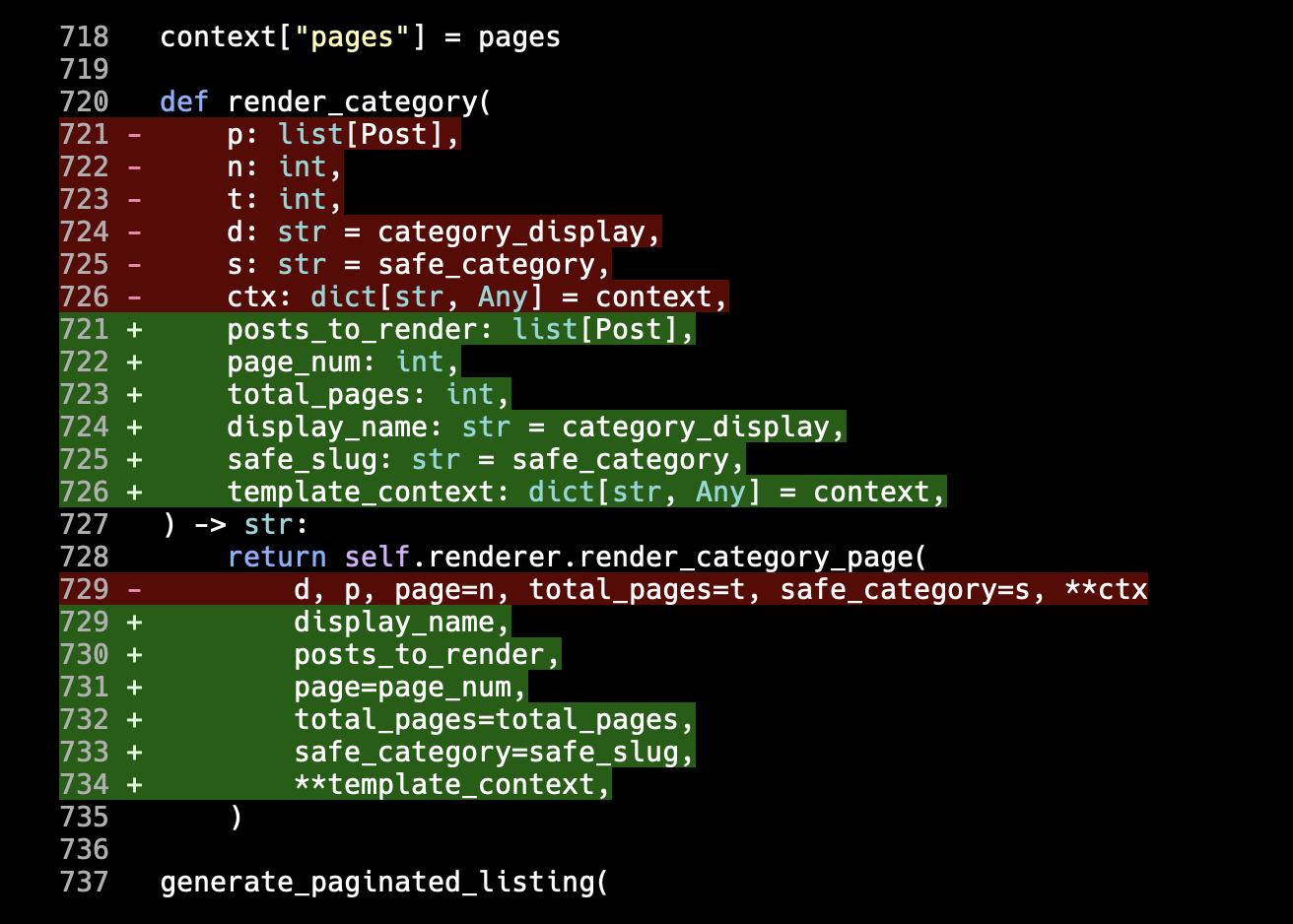
I can't. I can't let that stand. It's almost copy/paste. For me, this is the ideal time to use just a little bit of inheritance. Here's my take (with classes renamed too, the leading _ didn't feel necessary for one thing):
I was tempted to prompt Copilot/Claude about this and see what clean-up it would do, if it would arrive at similar code. But really it didn't seem like a good use of a premium request (perhaps I should have given Gemini a shot).
I see this kind of thing in the code quite a bit, and it speaks to what I've said before about what I'm seeing: the code it writes is... fine. It's okay. It does the job. The code runs. It's just not... to my taste, I guess.
This is important for working out word counts and so read times. It doesn't make sense that embedded code counts towards those. ↩
Given the concerns I wrote about yesterday, in regard to the core generation code in BlogMore, I've been thinking some more about how I would probably have the code look. First thing this morning, over breakfast and coffee, I concluded that I'd probably have gone with something that was a single orchestration function/method, into which would be composed some modular support code. Back when I started the process of breaking up the generator I seem to recall that Gemini sort of went along those lines, but the code it created seemed pretty messy and the main site generation class was still a lot bigger than I would have liked. This is why, at the time, I went with Copilot/Claude's mixin-based approach; it felt a bit more hacky but the code felt tidier.
I wanted a similar separation of concerns as the mixin approach was aiming for.
I wanted to move away from mixins.
I wanted to favour something closer to composition.
I wanted to favour simple functions over classes where possible.
I then set it off working and left it to get on with things. Overall I think it took around an hour, with the need for me to approve things now and again (so probably could have been faster, I wasn't there to answer right away every time), but it got there in the end. This has resulted in a third PR to clean up the generator typing issues. In doing so I feel I've also addressed most of the unease I was feeling yesterday evening, and might actually have got closer to where I'd rather the code was.
Glancing over the result, I can still see things I'd want cleaned up, and done in a slightly different way, but overall I have a better feeling about this third approach. I sense this is a better place to move on from.
So that's three PRs I have lined up to address the code smell that's been bugging me for a couple of days. One fixes it with an ABC; one fixes it with a protocol; and now one fixes it by reworking the submodularisation of the generator to use a different approach entirely. On the one hand, this seems like a lot of work and a lot of faff (and, as I said yesterday, I wouldn't start here to get where I want to be), but on the other hand I do kind of understand the appeal of being able to get hours of work done in a relatively short period of time, so you can experiment with the results.
Would I recommend someone work this way? No, of course not. Does it make for an interesting side-quest when I'm in "it is still my hobby too" mode? Yeah, it does.
The tidying of the BlogMore source carries on; sometimes by hand, but also sometimes by using either Copilot/Claude or Gemini to decide how best to nudge the codebase in a desired direction. When I do the latter, if I like the suggestions the agents make, but it looks like a bunch of work and I can't be faffed with all that typing, I get them to do the work; otherwise, I'll do it myself.
I am, however, seeing lots of evidence of what I expected to happen, and anticipated happening: to get to where I would like the code to be, I wouldn't have started here.
I'll stress again, for anyone who hasn't been following along, for anyone who might have landed into the middle of this long thread of AI experimenting, that this was the point and purpose. I wanted to use this tool to build something relatively inconsequential, and which I could likely build myself given the time and the inclination, and also something I would actively use.
So where am I at? My main distaste at the moment is the core generation code. Just a few days ago this was a couple of thousand lines of repetitive code that did the job, but which was a bit messy. There's no question that I would not have written it anything like this. Because of this I've been on a push to try and break it up and tidy it up. While doing this I've been playing Copilot/Claude and Gemini off against each other, to see who does what.
As of the time of writing, the generator is split up, but in a way I wouldn't have done myself either. It's pretty much half a dozen mixin classes in a trench coat, all pretending to be one cohesive class. I feel that's a reasonable solution given where I started, but honestly I wouldn't have started there had I been coding this by hand.
Right at the moment I'm working out the best way forward to tidy up an outcome of this approach that I really don't like. The generator code is littered with lots of # type: ignore[attr-defined] to keep mypy happy, because that's what Claude did when it built all those little mixins. To borrow from the explanation in AGENTS.md, the current makeup looks like this:
The issue is (for example) that MinifyMixin defines a method _write_html. Meanwhile OptionalPagesMixin and ListingMixin and so on make use of self._write_html. But because there's no direct connection between those two classes and MinifyMixin, mypy complains that _write_html isn't defined. Of course, it isn't defined, because it only becomes available when all those classes climb into the SiteGenerator trench coat and pretend to be a real class.
The ignore direction solves the problem, but it's ugly and it's cheating.
So I then set the two different agents on the path of proposing a solution to this. Both were quite different. Claude (via Copilot) decided that an abstract base class was the solution. Gemini decided that a protocol was the solution. I think I'm siding with Gemini on this one because this is a provides/needs problem, not a "kind of" problem. Even then though, while I sense Gemini has the right approach, I'm not always happy with its implementation of it1, and once again: it's a cleanup of something I'd sooner not be cleaning up in the first place.
So here's the thing, and this harks back to wondering if the code is that bad: it isn't... but it's also generating work if you look at the code and decide that you want it clean and maintainable.
To get to where I want to go, I wouldn't start from here.
I get why I'm seeing the odd report here and there of people abandoning their code bases, or deciding to rebuild them from scratch by hand. Part of me wants to start a fresh branch, remove almost everything, and rewrite the code so it has feature-parity but in a way where I feel the code is tidy and elegant.
One of the things I noticed when I started on the BlogMore experiment was the fact that Copilot/Claude seemed to love to write monolithic code. Pretty early on most of the code was landing in just a couple of files. Once I noticed this I instructed it to break things up and always try and be more modular. This started out in the instructions for Copilot but eventually I migrated the instruction to AGENTS.md (as seems to be the fashion these days).
While this rule seems to have held, one file that always remained pretty large was generator.py. This is, as you might guess from the name, the main site generation code. While it does sort of make sense that it is the pivotal body of code for the application, it doesn't follow that it has to contain so much code.
So, yesterday evening, I decided to experiment by asking Gemini CLI to look over the code and tell me what it thinks. The prompt was:
Quite a bit of work has been done on @src/blogmore/generator.py to try and reduce duplication of effort and boilerplate. I wonder if we can do a little more? Please take a look over the code there and see if there is any more repetitive code that can be cleaned up, to make the codebase more maintainable.
Also, the file is getting quite long. I prefer Python files to be no more than 1000 lines at most. Please also look at the code with a view to it being broken up into more logical sub-modules. Perhaps @src/blogmore/generator.py could turn into a generator directory with smaller modules inside it.
Look over this and report back with any findings. Also, don't look for anything, look for and report back changes that will make cleaner code and will be impactful.
I then left it to come up with an assessment while I got on with other things.
Its headline finding was:
Status: The file is currently 2,146 lines long, significantly exceeding the 1,000-line maintainability threshold. It has become a "God Object" that handles everything from low-level byte-copying and regex-based minification to high-level site orchestration.
This seemed reasonable, so I told it to get on with the job of doing this. I've also saved the plan it made as a gist.
What is notable in the plan is the validation strategy at the end. While there is a full suite of tests available, and while this is documented in AGENTS.md:
-Run the test suite after every change: `make test`.
-Any new functionality **must** have associated tests.
-If a change in behaviour makes existing tests incorrect, update those tests.
Do not change tests purely to make them pass without a genuine reason.
-Do not delete or comment out failing tests; fix the underlying code instead.
the plan that Gemini arrived at seemed to concentrate only on test_generator.py and test_integration.py.
Once the work to break up generator.py was done I could see it had run those tests and it was happy with the outcome. So I did the obvious thing and ran make test and, sure enough, there was a failed test (I think there was just the one). So I said to Gemini:
you should have run all the tests. Did you read @AGENTS.md at all?
It replied with:
Verifying Refactor Quality: Running comprehensive quality checks as mandated by AGENTS.md.
and then got on with the work of fixing what had been broken.
At this point it should be noted that another instruction I have in AGENTS.md is:
Use full, descriptive names for variables, functions, and classes. Do not use abbreviations when the full word is readable.
I've found that Copilot/Claude has done an excellent job of sticking to this wish. If anything I'd say at times it's got a little too carried away. But, I'm not typing this code, I'm only reading it; making the code very readable from a symbol point of view makes a lot of sense.
I swear, I can see why people sometimes fall into the trap of thinking agents have personalities, because the next thing I see, after telling it off for obviously not reading the rules of messing in my repo, is this:
Now, to be fair, my instruction does mention variables, functions, and classes. It doesn't explicitly say "parameters", I guess. But... come on!
In all other respects though it got things fixed and I ended up with a cleaned-up generation engine that was more modular. In review, I did find a couple of things in its plan that I wasn't super keen on (and which I could have pushed back on right at the planning stage, so I'd say that's on me, not on the agent), but overall it was a workable solution.
I prompted it once more to fix the things I didn't like, which it did and did a fine job of. As part of that prompt I did say:
I'm seeing functions in there with single letter parameter names. Please keep in mind the instruction about naming things in @AGENTS.md
And it did do as it was told.
As amusing as this was (really, it's so tempting to think it decided to be stroppy after I told it to go read AGENTS.md), it has left me wondering though: just how widespread is the convention of looking for and reading the agents file? While I get that each of the command-line tools seem to have a preference for their self-named instructions file first, it was my understanding that in the absence of such a file AGENTS.md is looked for.
During the session I'm talking about here, either Gemini CLI didn't do that, or it did and just didn't take on board the conventions I wanted it to follow.
As for the great breakup of generator.py... I grabbed the assessment and the plan that Gemini came up with, turned it into an issue, and set Copilot to work on it too. Despite working off the same prompt, as it were, it came up with a very different approach. So my next job is to decide which of the two I like most.
As of the time of writing, the Gemini approach to cleaning this up results in the main site.py file inside the new generator subdirectory being 996 lines; that's just under the 1,000 line limit I tend to set myself1, so close enough, but not ideal. Copilot/Claude, on the other hand, is sat at 278 lines! While the idea of Gemini was to make site.py a small descriptive top-to-bottom and start-to-finish description of how a site is generated, it's somehow managed to make a more verbose version; the Copilot/Claude version looks to do a far better job of fulfilling that intention.
Then again the Gemini version has broken the work up across 9 files, the Copilot/Claude version across 13. Also the Copilot/Claude version has taken a really fun and interesting approach to solving the problem that I'm kind of digging2.
So now I have to decide which, if either, I'm going with.
That's probably another post.
Although in my own projects I try and keep Python files much smaller than that if I can help it. ↩
After writing the earlier post I had to AFK to attend to normal life things. When I finally sat back at my keyboard, I decided to write my own take on minified_filename.
To recap, this is what Copilot/Claude came up with first:
defminified_filename(source:str)->str:"""Compute the minified output filename for a given source filename. Transforms the file extension: ``.css`` becomes ``.min.css`` and ``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes ``theme.min.js`` and ``style.css`` becomes ``style.min.css``. Args: source: Source filename ending in ``.css`` or ``.js``. Returns: The corresponding minified filename. Raises: ValueError: If *source* does not end with ``.css`` or ``.js``. """ifsource.endswith(".css"):returnsource[:-len(".css")]+".min.css"ifsource.endswith(".js"):returnsource[:-len(".js")]+".min.js"raiseValueError(f"Unsupported file extension for minification: {source!r}")
This is what it arrived at once it had self-reviewed the above:
defminified_filename(source:str)->str:"""Compute the minified output filename for a given source filename. Transforms the file extension: ``.css`` becomes ``.min.css`` and ``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes ``theme.min.js`` and ``style.css`` becomes ``style.min.css``. Args: source: Source filename ending in ``.css`` or ``.js``. Returns: The corresponding minified filename. Raises: ValueError: If *source* does not end with ``.css`` or ``.js``. """ifsource.endswith(".css"):returnsource.removesuffix(".css")+".min.css"ifsource.endswith(".js"):returnsource.removesuffix(".js")+".min.js"raiseValueError(f"Unsupported file extension for minification: {source!r}")
The tests it wrote looked like this:
classTestMinifiedFilename:"""Test the minified_filename utility function."""deftest_css_extension_becomes_min_css(self)->None:"""Test that a .css extension is replaced with .min.css."""assertminified_filename("style.css")=="style.min.css"deftest_js_extension_becomes_min_js(self)->None:"""Test that a .js extension is replaced with .min.js."""assertminified_filename("theme.js")=="theme.min.js"deftest_hyphenated_css_filename(self)->None:"""Test that a hyphenated CSS filename is handled correctly."""assertminified_filename("tag-cloud.css")=="tag-cloud.min.css"deftest_hyphenated_js_filename(self)->None:"""Test that a hyphenated JS filename is handled correctly."""assertminified_filename("search.js")=="search.min.js"deftest_unsupported_extension_raises(self)->None:"""Test that an unsupported extension raises ValueError."""withpytest.raises(ValueError,match="Unsupported file extension"):minified_filename("style.txt")
I wasn't too keen on the obsession with just .css and .js files (it seemed unnecessary), and neither did I like the hard-coding of the resulting extensions, etc. It all felt too job-specific.
So my take on the code was this:
defminified_filename(source:str|Path)->str:"""Compute the minified output filename for a given source filename. Args: source: Source filename. Returns: The corresponding minified filename. """ifisinstance(source,str)andnotsource:returnsourceif(source:=Path(source)).suffix:source=source.with_suffix(f".min{source.suffix}")returnstr(source)
The tests being this:
classTestMinifiedFilename:"""Test the minified_filename utility function."""@pytest.mark.parametrize("before,after",[("style.css","style.min.css"),("theme.js","theme.min.js"),("style.min.css","style.min.min.css"),("file","file"),(".file",".file"),(".file.css",".file.min.css"),("",""),],)deftest_min_file(self,before:str,after:str)->None:"""Test that converting a filename to the minified version has the expected effect."""assertminified_filename(before)==after
So, yes, my version does work ever so slightly differently, but I feel it's more generic. It shouldn't be the business of this function to decide which type of file can have a .min slapped prior to its extension; if a caller asks for it, let them have it, they know what they're doing! Also, although it's not really necessary (because the code calling on it doesn't currently pass a Path), it will accept either a str or a Path.
I feel the big difference here too is the testing. Rather than one method after another, testing more or less the same thing with little variation, it makes more sense to have just the one test and then pass it lots of different input/output values. This is far more maintainable and also easier to write most of the time.
Of course, for an agent, it's probably easier for it to take a copy/paste approach than it is for it to "reason" about what makes for a maintainable test. I sense this is one of the dangers of letting an LLM do this job (and it's one that's often touted as being a prime job to do): good tests can be useful documentation if you're trying to understand a codebase. Badly-written tests, no matter how much coverage they offer, are going to slow you down.
As mentioned a couple of times in the last couple of days, aside from one particular issue I found and fixed, I'm in more of a "let's review some of the code and tidy things up" phase with the codebase. This process is at times me hand-making changes, and also in part me directing the agent to make a very specific improvement that I want.
Yesterday evening I did a little experiment of getting Gemini CLI to look for code that really needed some cleaning up, and then I had it write the issue text which I fed directly to Copilot/Claude and had it do the work. Finally, when that was done, I had Gemini review the work that Copilot had done (it was "happy" with the changes).
So, this morning, I thought I'd tackle another little thing I'd noticed in the code that rubbed me up the wrong way. Early on in the development lifecycle of BlogMore I added the optional minification of CSS and JS files (HTML too eventually, but that's not involved here). Because it's often been a convention I also prompted Copilot to ensure that if a file called whatever.css was minified, it be called whatever.min.css.
The resulting code did something that made sense, but which I wouldn't ever have done. The constants that held the filenames looked like this:
Like... sure, 10/10 for not hard-coding these all throughout the codebase as magic strings1, but this feels a little redundant. Personally I think I'd have just mentioned the non-minified name and then I'd have a function that generates the minified name from it. While technically, it would add the smallest amount of runtime overhead to the code, I think the single-source-of-truth pay-off is worth it.
For a good while though I left this alone. I was having fun playing with other things in the application, and adding all sorts of other amusing toys. But now that I'm more into a "how can this code be improved and what issues does the code have" mode, it felt like time to tackle this.
Given that a change here would touch so much of the code, and given I wasn't massively keen on spending ages walking through all the code and making the changes related to this, I decided to prompt Copilot to get on with this. It felt like something it couldn't get that wrong.
While it didn't get it wrong, as such, it made some questionable choices along the way. It did do the main thing I would have done: make a function to turn a filename into a minified filename. The initial version looked like this:
defminified_filename(source:str)->str:"""Compute the minified output filename for a given source filename. Transforms the file extension: ``.css`` becomes ``.min.css`` and ``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes ``theme.min.js`` and ``style.css`` becomes ``style.min.css``. Args: source: Source filename ending in ``.css`` or ``.js``. Returns: The corresponding minified filename. Raises: ValueError: If *source* does not end with ``.css`` or ``.js``. """ifsource.endswith(".css"):returnsource[:-len(".css")]+".min.css"ifsource.endswith(".js"):returnsource[:-len(".js")]+".min.js"raiseValueError(f"Unsupported file extension for minification: {source!r}")
That string-slicing with len and so on is nails on a chalkboard to me. When something like removesuffix exists, why on earth would "you" elect to do this? Of course the answer is obvious, but still... ugh.
Now, I will have to give credit to the process though. So the above was the initial version of the code. Once the PR had been created by Copilot, and I'd pulled it down for review and testing, it kicked off a review of its own. Reviewing its own code, it pushed back on itself:
In src/blogmore/generator.py, lines 90-93: The slice syntax source[:
-len(\".css\")] is less readable than using source.removesuffix(\".css\"), which is available in Python 3.9+. Since this codebase targets Python 3.12+, consider using removesuffix() for clarity.
It then went on to do a further commit to tidy this up. I approve. Bonus point to Copilot here.
So now we have this:
defminified_filename(source:str)->str:"""Compute the minified output filename for a given source filename. Transforms the file extension: ``.css`` becomes ``.min.css`` and ``.js`` becomes ``.min.js``. For example, ``theme.js`` becomes ``theme.min.js`` and ``style.css`` becomes ``style.min.css``. Args: source: Source filename ending in ``.css`` or ``.js``. Returns: The corresponding minified filename. Raises: ValueError: If *source* does not end with ``.css`` or ``.js``. """ifsource.endswith(".css"):returnsource.removesuffix(".css")+".min.css"ifsource.endswith(".js"):returnsource.removesuffix(".js")+".min.js"raiseValueError(f"Unsupported file extension for minification: {source!r}")
At this point the code is less worse. I don't think it's great, but it's less worse. Honestly, I think I'd be more inclined to do something with PurePath.suffixes and PurePath.suffix, leaning into the fact that we're dealing with filenames here, and so making it less about pure string slicing.
I also have other issues with the code, which I might still fix by hand:
The fact that it makes a point of only handling .css and .js files, and throws an error otherwise, is an odd choice. I mean, in context, that's what it's here to serve, but it seems oddly-specific and an attention to detail that wasn't really necessary.
The hard-coding of .min a couple of times grates a little.
The hard-coding of both .css and .js a couple of times, with the doubled-up if feels unnecessary.
It's a small function. It works in context. It does the job. But it also could be more elegant in the way it does it.
I'd also like to go on a small aside for a moment, because there's something else in the above that bothers me: yesterday evening I spent some time directing Copilot to tidy up all the docstrings in the code. While any agent I've thrown at it does seem to have taken note of the AGENTS.md file, and the instructions on how to write the docstrings (Google style please), it seems to have decided it was aiming more at Sphinx when it came to the content. That's fine, I hadn't been explicit.
So last night I made it clear that I wanted something more like I use in all my Python code, that aims to work with mkdocstrings. It should use the inline code and cross-reference styles that are more common when using that tool. I even made a point of telling Copilot to update AGENTS.md to make it clear that this is the preference:
-All inline code and cross-references in docstrings **must** use mkdocstrings-compatible Markdown style:
-Inline code: use single backticks (\`like_this\`).
-Cross-references: use mkdocstrings reference-style Markdown links (e.g., [`ClassName`][module.ClassName] or [module.ClassName][]).
-Do **not** use Sphinx roles (e.g., :class:`ClassName`) or double-backtick code (``ClassName``).
Now go back and look at the docstring for minified_filename. So much for agents making a point of following the instructions from AGENTS.md.
Anyway, back to the main flow here: given that I was thinking that I might rewrite minified_filename by hand so that it works "just so", I made a point of checking that it had written tests for this; something I couldn't take for granted.
Again, to the credit of the agent, it had written some tests:
classTestMinifiedFilename:"""Test the minified_filename utility function."""deftest_css_extension_becomes_min_css(self)->None:"""Test that a .css extension is replaced with .min.css."""assertminified_filename("style.css")=="style.min.css"deftest_js_extension_becomes_min_js(self)->None:"""Test that a .js extension is replaced with .min.js."""assertminified_filename("theme.js")=="theme.min.js"deftest_hyphenated_css_filename(self)->None:"""Test that a hyphenated CSS filename is handled correctly."""assertminified_filename("tag-cloud.css")=="tag-cloud.min.css"deftest_hyphenated_js_filename(self)->None:"""Test that a hyphenated JS filename is handled correctly."""assertminified_filename("search.js")=="search.min.js"deftest_unsupported_extension_raises(self)->None:"""Test that an unsupported extension raises ValueError."""withpytest.raises(ValueError,match="Unsupported file extension"):minified_filename("style.txt")
It's a start, but I think it could be done better. There's the test of the intended outcomes, and the test of the ValueError for passing something that isn't a .js or a .css file. Meanwhile, that business of testing "hyphenated" seems oddly specific for no good reason. But it's even worse: the test for a "hyphenated" JS file doesn't use a hyphenated file name.
Hilarious.
That's not all. What about the more obvious things like testing what happens if you pass a filename that has no extension, or a filename that already has two extensions, or a filename that already ends in .min.js, or a filename that has .min.css somewhere in its path that isn't at the end of the name, or an empty string, or...
As I said a few days ago: the code is mostly fine. It gets the job done. I've seen worse. I reviewed worse. I've inherited worse. I think the thing that concerns me the most is that there has to be a lot of code like this being uncritically accepted after generation2, which in turn is surely going to be feeding back into future training. So while I can't deny that something has improved in the last six or so months, when it comes to agent-generated code, might it be that we are at peak quality right now? Might it be that from this point on we start to decline as "eh, it's... fine" code starts to overwhelm the most popular forge we have?
I suppose the main benefit still is that this approach is nice and cheap. Right?
Actually, I think it did hard-code the filenames throughout the codebase, initially, until I asked it not to. Perhaps I'm misremembering, but agents do seem to love magic strings and numbers for some reason (I think we know the reason). ↩
At least I have, as of the time of writing, 1,380 tests to check that I've not broken anything when I do hand-clean the code. But, hmm, there's a question: can I actually trust those tests? It's not like I wrote them.
This was, of course, slightly tongue-in-cheek, because I did anticipate that the coverage might not be as useful as you'd hope an agent would deliver, and especially not at the level you'd personally aim for. On the other hand, I did expect it to have covered some of the fundamentals.
Being serious about wanting to hand-tidy some of the code as a way to start to get myself into the codebase1, I set out to look at validate_path_template in content_path.py. My plan for how to tidy the code had overlap with how both Claude and Gemini had approached it, but also with a slightly different take. Nothing too radical, with the main difference being that I didn't want a baked-in default for which variables were required (to recap: both the agents saw the need to make this configurable rather than hard-coded into the body of the function, but both still kept a "backward-compatible" default that had a "mixing of concerns" code smell about it).
A function such as validate_path_template, which has a core use, is intended to be of fairly general utility, and which has a very obvious set of outputs given certain inputs, and which has zero side effects and no dependencies, seems like a really obvious candidate for a good set of unit tests. This in turn should have meant that I could modify the code with confidence, and experiment with confidence, knowing that said tests would let me know when I've screwed up.
I went looking for those tests so I could run them and them alone as I did this work.
Keep in mind, at this point, there are 1,380 tests that Copilot/Claude has written. That's a lot of tests. Of course there will be some direct tests of validate_path_template!
Spoiler: there weren't. No tests. At all. 1,380 tests inside the tests/ directory and not one that directly tested this utility function.
Now, sure, the function did have coverage. Before making any changes, the codebase itself had 94% coverage and content_path.py itself had 93% coverage. In fact, the only thing that wasn't covered was the code that raised an exception if a template looked broken.
This, for me anyway, is a good example of how and where coverage doesn't help me. Sure, other code that is being tested is calling this and if I change this code in ways that breaks that other code, I'll (probably) get to know about it. But if I want to properly understand the code (remember, I didn't write it, this is like getting to know someone else's2 code) it's really helpful to see a set of dedicated tests for that specific function.
There were none.
For a moment, I'm going to give Copilot/Claude an out. When I started BlogMore, right at the very start, just as I was messing about to see what would happen, I gave no thought to tests. It was only after a short while that I asked it to a) create a set of tests for the current behaviour and b) made it clear that all new code had to have tests. It is possible, just possible, that the content of content_path.py fell through that crack. I don't know for sure without going back and looking through the PR history. I'm not that curious right now.
What is interesting though is that, in setting both Copilot/Claude and Gemini on the same problem with the same prompt, and having them both identify the same area for improvement, neither seemed to arrive at the conclusion that adding dedicated tests was something worth doing.
So the point here -- which isn't a revelation at all, but I think has been nicely illustrated by what I've seen happen -- is that an agent might indeed create a lot of tests, and perhaps even achieve pretty good coverage too, but it's no guarantee that they're going to be useful tests when you want to get your hands dirty in the codebase.
Turns out that some of those tests might still need writing by hand, like I did for this tidy-up of content_path.py. Well, I say, "by hand", I did take this as an opportunity to test being pretty lazy about typing out the tests I wanted.
PS: While looking through the tests and tidying some code related to the above, I came across this:
fromblogmore.pagination_pathimport(DEFAULT_PAGE_1_PATH,DEFAULT_PAGE_N_PATH,# ...other imports removed for brevity...)classTestDefaults:"""Tests for the default constant values."""deftest_default_page_1_path(self)->None:"""The default page_1_path should be 'index.html'."""assertDEFAULT_PAGE_1_PATH=="index.html"deftest_default_page_n_path(self)->None:"""The default page_n_path should be 'page/{page}.html'."""assertDEFAULT_PAGE_N_PATH=="page/{page}.html"
Brilliant. I guess line goes up has come to agent-written tests. But look! 1,380 tests guys!
Remember: up until this point this has mostly been an experiment in uncritically letting Copilot do its thing. ↩
Arguably this is someone else's code, with extra steps. ↩
As mentioned in the previous post, I've been having a play around with Copilot/Claude vs Gemini when it comes to getting the agents to seek out "bad" code and improve it. In that first post on the subject, I highlighted how both tools noticed some real duplication of effort, both addressed it in more or less the same way, and neither of them took the clean-up to its logical conclusion (or, at the very least, neither cleaned it up in a way that I feel is acceptable).
The comparison of the two PRs (Gemini vs Claude via Copilot) is going to be a slow and occasional read, and if I notice something that catches my interest, I'll note it on this blog.
Initially, I was looking at which files were touched by both. With Gemini it was:
On the surface, it looks like Claude might have done a better job of finding untidy issues in the code. Of course a proper read/assessment of the outcome is needed to decide which is "better"; not to mention the application of a lot of personal taste.
So, with the initial/surface impression that "Claude went deeper", I took a look at the first file they had in common: content_path.py. This is documented as a module related to:
Shared path-resolution utilities for content output paths.
This module provides the generic building blocks used by page_path and post_path. Each content type supplies its own allowed-variable set and variable dict; this module handles the common validation, substitution, and safety checks.
There's 3 functions in there:
validate_path_template -- for validating a format string used in building a path.
resolve_path -- given a template and some values to populate variables in the template, create a path.
safe_output_path -- helper function for joining paths and ensuring they don't escape the output directory.
These seem like sensible functions to have in here, and I can imagine me writing a similar set in terms of the problem they seek to solve.
Both agents seemed to agree on what needed some work: validate_path_template. Both also seem to agree that building knowledge of which variable is required into the function itself isn't terribly flexible; I feel this is a reasonable review of the situation. However, the two agents seem to disagree on how this should be resolved.
Claude's take on this is that the function should grow an optional keyword argument called required_variable, which defaults to slug. It also adds an assert to test if the required variable exists in the allowed_variables (okay, I could quibble about this but given this is a code-check rather than a user-input check, eh, I can go with it). Finally it does the check using the new variable and also makes the error reporting a touch more generic too.
--- /Users/davep/content_path.py 2026-04-30 13:20:00.737955197 +0100+++ src/blogmore/content_path.py 2026-04-30 13:20:04.560178727 +0100@@ -17,13 +17,15 @@ template: str,
config_key: str,
allowed_variables: frozenset[str],
- item_name: str,+ item_name: str = "",+ *,+ required_variable: str | None = "slug",) -> None:
"""Validate a path format string for a content type.
Checks that *template* is non-empty, well-formed, references only
- variables from *allowed_variables*, and includes the mandatory- ``{slug}`` placeholder.+ variables from *allowed_variables*, and (when *required_variable* is+ not ``None``) includes the mandatory placeholder. Args:
template: The path format string to validate.
@@ -33,11 +35,19 @@ template.
item_name: The human-readable name of the content type used in
the uniqueness error message (e.g. ``"page"`` or ``"post"``).
+ Ignored when *required_variable* is ``None``.+ required_variable: The variable name that must appear in the+ template, or ``None`` if no variable is mandatory. Defaults+ to ``"slug"`` for backward compatibility. Raises:
ValueError: If the template is empty, malformed, references an
- unknown variable, or omits the ``{slug}`` placeholder.+ unknown variable, or omits the required placeholder. """
+ assert required_variable is None or required_variable in allowed_variables, (+ f"required_variable {required_variable!r} is not in allowed_variables"+ )+ if not template:
raise ValueError(f"{config_key} must not be empty")
@@ -61,9 +71,9 @@ + f". Allowed variables are: {', '.join(sorted(allowed_variables))}"
)
- if "slug" not in field_names:+ if required_variable is not None and required_variable not in field_names: raise ValueError(
- f"{config_key} '{template}' must contain the {{slug}} variable so that "+ f"{config_key} '{template}' must contain the {{{required_variable}}} variable so that " f"each {item_name} can be uniquely identified"
)
Gemini, on the other hand, has a very similar idea but allows for the fact that the caller might want to specify multiple required variables. So in this case it adds required_variables (as a positional/keyword argument rather than a pure-keyword argument) and defaults it to a frozenset that contains "slug". The rest of the change is also about making the test for the required variables, and the reporting of the error, generic. It doesn't do anything about checking that the required variables are within the allowed variables.
--- /Users/davep/content_path.py 2026-04-30 13:20:00.737955197 +0100+++ src/blogmore/content_path.py 2026-04-30 14:47:41.607748447 +0100@@ -18,12 +18,13 @@ config_key: str,
allowed_variables: frozenset[str],
item_name: str,
+ required_variables: frozenset[str] = frozenset({"slug"}),) -> None:
"""Validate a path format string for a content type.
Checks that *template* is non-empty, well-formed, references only
- variables from *allowed_variables*, and includes the mandatory- ``{slug}`` placeholder.+ variables from *allowed_variables*, and includes the+ *required_variables*. Args:
template: The path format string to validate.
@@ -33,10 +34,13 @@ template.
item_name: The human-readable name of the content type used in
the uniqueness error message (e.g. ``"page"`` or ``"post"``).
+ required_variables: The set of variable names that MUST appear+ in the template to ensure uniqueness. Defaults to+ ``{"slug"}``. Raises:
ValueError: If the template is empty, malformed, references an
- unknown variable, or omits the ``{slug}`` placeholder.+ unknown variable, or omits a required variable. """
if not template:
raise ValueError(f"{config_key} must not be empty")
@@ -61,10 +65,12 @@ + f". Allowed variables are: {', '.join(sorted(allowed_variables))}"
)
- if "slug" not in field_names:+ missing = required_variables - set(field_names)+ if missing: raise ValueError(
- f"{config_key} '{template}' must contain the {{slug}} variable so that "- f"each {item_name} can be uniquely identified"+ f"{config_key} '{template}' must contain the "+ + ", ".join(f"{{{v}}}" for v in sorted(missing))+ + f" variable(s) so that each {item_name} can be uniquely identified" )
For the most part I think I prefer what Gemini is trying to do, although Claude's sanity check that the required variable is one of the possible variables makes sense. I kind of feel like both of them missed the point when it came to handling the fact that "slug" is required: given that validate_path is otherwise built to be pretty generic, I think I would have defaulted to nothing and simply left it up to the caller to be explicit that "slug" is required, because that matters in context of the caller. This feels like a pretty obvious case of a "business logic" vs "generic utility code" separation of concerns scenario.
So where does this leave me? At the moment I'm not inclined to merge either PR, but that's mainly because I want to carry on reading them and perhaps writing some more notes about what I encounter. What this does illustrate for me is something we know well enough anyway, but which I wanted to experiment with and see for myself: the initial implementation of any working code written by an agent seems optimised for that particular function or method, perhaps class if you're lucky. It will happily repeat the same code to solve similar problems, or perhaps even use very different approaches to solve the same problem. What it won't do well is recognise that this problem is solved elsewhere and so either use that other code by calling it, or perhaps modify it slightly to make it more generic and more applicable in more situations.
On the other hand, it has shown that with a bit of prompting (and keep in mind that the prompt that arrived at this comparison was really quite vague) it is possible to get an agent to "consider" the problem of duplication and boilerplate and to try and address that.
Having seen the two solutions on offer here, it's hard not to conclude that the best solution would be for me to take the PRs as flags marking places in the code that could be cleaned up, and do the tidy myself.
At least I have, as of the time of writing, 1,380 tests to check that I've not broken anything when I do hand-clean the code. But, hmm, there's a question: can I actually trust those tests? It's not like I wrote them.
Guess that's a whole other thing to worry about at some point...
While I don't, for a moment, think that the work on BlogMore is complete, I think it's fair to say that the rate of new feature additions has slowed down. Which is fine, there's only so much I need from a self-designed/directed static site generator; at a certain point there's a danger of adding features for the sake of it.
Around this point I think I want to start to pay proper attention to the code quality and maintainability of the ongoing experiment.
As I mentioned the other day, while working through this, I had noticed plenty of bad habits that Copilot (and in this case pretty much always Claude Sonnet 4.6) has. All were very human (obviously), but also the sort of thing you'd expect a human developer to educate themselves out of.
Yesterday evening, out of idle curiosity, I installed Gemini CLI because I wanted to see what would happen if I pointed it at the v2.18.0 codebase and asked it to look for things to clean up, and then what would happen if I did the same with Copilot CLI.
I've saved the results as a PR for what Gemini came up with and what Copilot came up with1. I've not given them a proper read over yet, but while having a quick glance at them something leapt out at me: in the code before the request, there was this in utils.py:
defcount_words(content:str)->int:"""Count the number of words in the given content. Strips common Markdown and HTML formatting before counting so that only prose words are included. The same normalisation rules as :func:`calculate_reading_time` are applied. Args: content: The text content to analyse (may include Markdown/HTML). Returns: The number of words in the content. Examples: >>> count_words("Hello world") 2 >>> count_words("word " * 10) 10 """# Remove code blockscontent=re.sub(r"```[\s\S]*?```","",content)content=re.sub(r"`[^`]+`","",content)# Remove markdown links but keep the text: [text](url) -> textcontent=re.sub(r"\[([^\]]+)\]\([^\)]+\)",r"\1",content)# Remove markdown images:  -> ""content=re.sub(r"!\[([^\]]*)\]\([^\)]+\)","",content)# Remove HTML tagscontent=re.sub(r"<[^>]+>","",content)# Remove markdown formatting characterscontent=re.sub(r"[*_~`#-]"," ",content)returnlen([wordforwordincontent.split()ifword])defcalculate_reading_time(content:str,words_per_minute:int=200)->int:"""Calculate the estimated reading time for content in whole minutes. Uses the standard reading speed of 200 words per minute. Strips markdown formatting and counts only actual words to provide an accurate estimate. Args: content: The text content to analyze (can include markdown) words_per_minute: Average reading speed (default: 200 WPM) Returns: Estimated reading time in whole minutes (minimum 1 minute) Examples: >>> calculate_reading_time("Hello world") 1 >>> calculate_reading_time("word " * 400) 2 """# Remove code blocks (they typically take longer to read/understand)content=re.sub(r"```[\s\S]*?```","",content)content=re.sub(r"`[^`]+`","",content)# Remove markdown links but keep the text: [text](url) -> textcontent=re.sub(r"\[([^\]]+)\]\([^\)]+\)",r"\1",content)# Remove markdown images:  -> ""content=re.sub(r"!\[([^\]]*)\]\([^\)]+\)","",content)# Remove HTML tagscontent=re.sub(r"<[^>]+>","",content)# Remove markdown formatting characterscontent=re.sub(r"[*_~`#-]"," ",content)# Count words (split by whitespace and filter out empty strings)words=[wordforwordincontent.split()ifword]word_count=len(words)# Calculate minutes, rounding to the nearest minute with a minimum of 1minutes=max(1,round(word_count/words_per_minute))returnminutes
I think this right here is a great example of why the code that these tools produce is generally kind of... meh. Let's just really appreciate for a moment the duplication of effort going on there. But it's even more fun. Look at the docstring2 for count_words: it says right there that the "same normalisation rules as calculate_reading_time are applied". It "knows" it copied the work that went into calculate_reading_time too, but never once did it then "think" to pull the common code out and have both of the functions call on that helper function.
Back to the parallel invitations to refactor, having asked:
please do a review of this codebase and see if there is any scope for refactoring so there's less duplication
Both Gemini and Claude noticed this and did something about it. Gemini came up with a:
def_strip_formatting(content:str)->str:
with all the regex-based-markdown-stripping code in there and then rewrote count_words and calculate_reading_time to call on that. The Copilot/Claude cleanup did something very similar:
def_strip_markdown_formatting(content:str)->str:
So it's a good thing that both of them "noticed" this duplication of effort and cleaned it up. What I do find interesting though is what the result was. Stripping docstrings and comments for a moment, here's what I was left with, by Gemini, for count_words and calculate_reading_time:
In both cases calculate_reading_time is still doing the work of counting words when count_words is right there to be called! Don't even get me started on how the Gemini version of calculate_reading_time is so obsessed with assigning values to variables that only get used once in the next line3. Were I reviewing these PRs (oh, wait, I am reviewing these PRs!), I'd request the latter function be turned into:
I would imagine that there's a lot more of this going on in the code, and under ideal conditions this sort of thing would not have made its way into the codebase in the first place. Part of the point of this experiment was to mostly get the agent to do its own thing, without me doing full-on reviews of every PR. Were I to use this sort of tool in a workplace, or even on a FOSS project that wasn't intended to be this exact experiment, I'd be far more inclined to carefully review the result and request changes.
Or, perhaps, hear me out... I have a third agent that I teach to be just like me and I get it do the work of reviewing the PRs for me. What could possibly go wrong?
Again, I guess I should stop referring to Copilot in this case and instead refer to Claude Sonnet. ↩
Note to self: I need to educate the agents in how I prefer and always use the mkdocstrings style of cross-references. ↩
Yes, I know, this is a favoured clean code kind of thing in some circles, but it can be taken to an unnecessary extreme. ↩
It seems that dunking on GitHub is the flavour of the day. At the moment most of the social/news type things I tend to read are filled with the Ghostty news, as well as a small revival of posts and links to blog posts about all the recent outages. It's understandable. It does seem that something has shifted with GitHub in the last few months. While it hasn't been the site I used to enjoy for quite some time now, it just seems to be getting worse at the moment.
As I read all of this I find myself mostly nodding along. For the most part I'm not finding that GitHub is getting in the way and stopping me from doing the things I want to do, and for the most part it does act as a vital tool that lets me get work done, and also lets me enjoy my longest-enjoyed hobby. On the other hand I couldn't help but sigh and think "yeah, I get why this is the time that people are done" when I opened up the PR page for this blog, just now, and saw this:
It does get me thinking about my relationship with GitHub, and how long I've been using it. As I've written before, I created my account back in 2008; I was within the first 30,000 users. While my use of it was only very occasional for quite a long time, for the last decade I've been constantly interacting with it. It is somewhere I visit constantly, not just to do work on my own projects, but to read what other people are doing. One of the first things I do every morning, when I sit down at my desk, is open my GitHub dashboard page and have a scroll through the feed to see what people I follow have been up to.
It's generally been the most fulfilling feed I've read.
But I'm also getting that feeling I got when I hung on to my Twitter account far longer than I really should have; not just because of the general vibe of "it's falling apart", but also other types of questionable behaviour. The degrading performance, the troubling business relationships, the over-emphasis on all things AI... it adds up.
There is a sense that some time ago was the time to move elsewhere as my sociable forge (probably around the time that Microsoft took over), and that not having done that, now is the second best time. But the effort of making that move is non-trivial and, quite frankly, I'd want to see where folk start to land, if they started to move away in any numbers at all. For me the real utility of GitHub isn't the "it's somewhere to store my shit" thing, it's the socially coding thing.
Then there's the follow-up problem: if some other forge was to become the next flavour of the decade, it too would probably end up suffering the same fate as GitHub.
Perhaps now is the time for me to start looking into options for collaborative code forges that offer the same sort of solution that Mastodon does for Twitter-like nattering.