In a post yesterday I finished off by saying:
At least I have, as of the time of writing, 1,380 tests to check that I've not broken anything when I do hand-clean the code. But, hmm, there's a question: can I actually trust those tests? It's not like I wrote them.
This was, of course, slightly tongue-in-cheek, because I did anticipate that the coverage might not be as useful as you'd hope an agent would deliver, and especially not at the level you'd personally aim for. On the other hand, I did expect it to have covered some of the fundamentals.
Being serious about wanting to hand-tidy some of the code as a way to start to get myself into the codebase1, I set out to look at validate_path_template in content_path.py. My plan for how to tidy the code had overlap with how both Claude and Gemini had approached it, but also with a slightly different take. Nothing too radical, with the main difference being that I didn't want a baked-in default for which variables were required (to recap: both the agents saw the need to make this configurable rather than hard-coded into the body of the function, but both still kept a "backward-compatible" default that had a "mixing of concerns" code smell about it).
A function such as validate_path_template, which has a core use, is intended to be of fairly general utility, and which has a very obvious set of outputs given certain inputs, and which has zero side effects and no dependencies, seems like a really obvious candidate for a good set of unit tests. This in turn should have meant that I could modify the code with confidence, and experiment with confidence, knowing that said tests would let me know when I've screwed up.
I went looking for those tests so I could run them and them alone as I did this work.
Keep in mind, at this point, there are 1,380 tests that Copilot/Claude has written. That's a lot of tests. Of course there will be some direct tests of validate_path_template!
Spoiler: there weren't. No tests. At all. 1,380 tests inside the tests/ directory and not one that directly tested this utility function.
Now, sure, the function did have coverage. Before making any changes, the codebase itself had 94% coverage and content_path.py itself had 93% coverage. In fact, the only thing that wasn't covered was the code that raised an exception if a template looked broken.
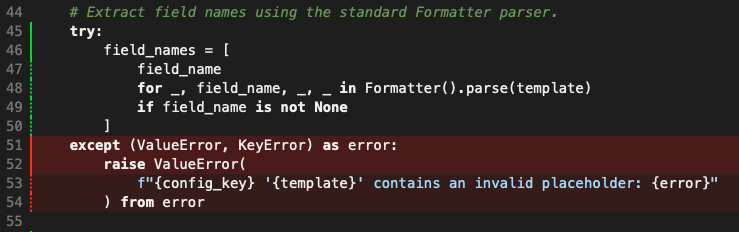
This, for me anyway, is a good example of how and where coverage doesn't help me. Sure, other code that is being tested is calling this and if I change this code in ways that breaks that other code, I'll (probably) get to know about it. But if I want to properly understand the code (remember, I didn't write it, this is like getting to know someone else's2 code) it's really helpful to see a set of dedicated tests for that specific function.
There were none.
For a moment, I'm going to give Copilot/Claude an out. When I started BlogMore, right at the very start, just as I was messing about to see what would happen, I gave no thought to tests. It was only after a short while that I asked it to a) create a set of tests for the current behaviour and b) made it clear that all new code had to have tests. It is possible, just possible, that the content of content_path.py fell through that crack. I don't know for sure without going back and looking through the PR history. I'm not that curious right now.
What is interesting though is that, in setting both Copilot/Claude and Gemini on the same problem with the same prompt, and having them both identify the same area for improvement, neither seemed to arrive at the conclusion that adding dedicated tests was something worth doing.
So the point here -- which isn't a revelation at all, but I think has been nicely illustrated by what I've seen happen -- is that an agent might indeed create a lot of tests, and perhaps even achieve pretty good coverage too, but it's no guarantee that they're going to be useful tests when you want to get your hands dirty in the codebase.
Turns out that some of those tests might still need writing by hand, like I did for this tidy-up of content_path.py. Well, I say, "by hand", I did take this as an opportunity to test being pretty lazy about typing out the tests I wanted.
PS: While looking through the tests and tidying some code related to the above, I came across this:
from blogmore.pagination_path import (
DEFAULT_PAGE_1_PATH,
DEFAULT_PAGE_N_PATH,
# ...other imports removed for brevity...
)
class TestDefaults:
"""Tests for the default constant values."""
def test_default_page_1_path(self) -> None:
"""The default page_1_path should be 'index.html'."""
assert DEFAULT_PAGE_1_PATH == "index.html"
def test_default_page_n_path(self) -> None:
"""The default page_n_path should be 'page/{page}.html'."""
assert DEFAULT_PAGE_N_PATH == "page/{page}.html"
Brilliant. I guess line goes up has come to agent-written tests. But look! 1,380 tests guys!