Damn. Oh damn. My Reddit account is now old enough to buy beer1. O_o
While I probably have accounts somewhere that are older than this, that's still a pretty long time to have held an account somewhere and still be actively using it.
I remember I'd been reading Reddit for a couple of years before I finally made an account; I can't quite remember what prompted me to do that. In that time I've been more or less active there (although seldom one to post things or make comments -- normally I just consume and vote). From what I can tell that suggests I was starting to read Reddit within a year of it being launched.
I vaguely remember those old days. I remember all the conversation when it moved away from being developed in Lisp. I can't remember if I was visiting it around that time.
I do have the charter member badge because, back when gold was launched, I was reading the site a lot and it seemed sensible to support it at the time. I've long since let that subscription lapse. I see zero benefit in Reddit Premium.
For some time, a couple or so years back, when they killed off most third-party clients, I stopped using the site for a while. These days I have got back into the habit of reading it again. While I do occasionally check in on a handful of Lemmy subscriptions, and do keep thinking I should probably look into lobste.rs2, it's hard to break the habit of opening the Reddit app and scrolling for a wee while. I've yet to finally and fully replace it.
I should go look at some of my other longer-serving accounts on websites and services and see exactly which is my oldest one.
Over the weekend I read a comment, I think it was on Hacker News, where someone said they were having fun building things using AI. This was in response to someone saying that using AI took the fun out of programming. In their reply, the person qualified their answer with something along the lines of "the highs are higher and the lows are lower".
I think I agree.
My first ever exposure to any sort of computer was a Sinclair ZX80 that my maths teacher brought into school. After a class he plugged it in and let me and a friend take a look. To this day I still remember looking in the manual, looking at the tutorial, and at some point typing...
When I hit NEW LINE and a 2 appeared on the screen I was thrilled, I was hooked. I'd typed something that appeared on a TV screen and then I did something that made the answer appear on the TV screen. This felt like magic.
I've been hooked on writing code ever since.
In that time the highs have been high, and the lows have been low, but I think it's fair to say that I've been doing this for long enough (it's now 45 or 46 years since I typed that first instruction) that things have settled down. I still get a thrill when writing code, and I still get fed up with it from time to time, but the distance between the two isn't what it once was.
Which brings me back to the comment I read: I think I can safely say that, while properly experimenting with agents, while building BlogMore to test this approach out, I have been through a period of higher highs and lower lows when it comes to how I feel about the code and the project itself. When I kicked off development it was genuinely thrilling to have gone from an empty repository to a comprehensively-working initial version in just a matter of hours. Likewise it was thrilling to have gone from nothing to rebuilding this blog with the tool in just a few days. It would be a lie to suggest that it wasn't fun and exciting to see the result.
But, as I wrote back then, I was also very mindful of how empty the process felt at times, how I missed the whole "flow state" connection to building out the application. There have also been many moments along the way, which I've documented at times on this blog, where I've felt the project was getting stuck down a dead-end with respect to how the code was going.
And then there's all the times Copilot and/or Gemini CLI just plain stopped getting stuff done.
Given this -- given the highs especially -- I can see why some people get totally hooked, go all in, get consumed by the illusion of how powerful these tools are. I can see why they'd buy into and embrace the mindset that trots out the AI-equivalent of the crypto-hype "stay poor" retort to those who display any level of scepticism.
Ever since I kicked off the work on BlogMore I've had a renewed interest in writing on this blog (as you can probably tell from the stats and the calendar). But not just writing: also tweaking it, tidying it up, thinking about maintaining it into the future, thinking about the links and the categories and so on.
In doing so, I've also been looking at other folk who persist in keeping a blog, and especially those who maintain blogs built with static site generation tools, and in some cases I'm mildly envious of how far back some of them stretch.
I maintained this for a while, the engine for it all being some self-written PHP engine that was what could be best described as a dynamic static site (in other words it generated everything on request from underlying text files and HTML snippets because I had no wish to be faffing around with databases on a web host). Eventually though the blog side of this got to be too much trouble and I jumped over to Blogger.
I maintained that blog for quite a few years, with the first post being made in 2006 and the last in 2011. Sadly it's all quite broken now. I used to include a lot of images and, while some of them are embedded in the site itself, most were hosted on the older version of my website, as part of the photo gallery I also had there.
This all fell apart when I finally killed off the PHP version of my site and all the images were removed. Now the blog is a wasteland of broken image icons (not to mention a wasteland of broken external links -- so many of the sites I referred to back then have fallen off the net).
I hate this. I hate that thirty-something me was fired up enough to want to write stuff down and communicate to other people (and to future me) and it's all decayed. I especially dislike that the original version of my blog, now only stored on the Wayback Machine (and perhaps on a hard drive that I think is in a box somewhere in storage, perhaps also on some burnt-as-a-backup DVDs) is otherwise inaccessible. Much like I did with my original photoblog, I want to rescue this. I want to rescue all of this.
The technical challenges of teasing out the original posts from the Internet Archive and from Blogger aren't too great. Turning a bunch of HTML into Markdown isn't impossible either -- the library that I use in OldNews should do the job fine there. All that sort of work feels like a fun little challenge that will keep me amused for a few evenings.
There are two main things that cause me to pause when thinking about doing this.
The first is that some of those very old posts, as I mentioned above, link to places that don't exist and haven't existed for a long time. It raises the question: do I even care to preserve things that have no context any more?
The second is that many of the posts in the Blogger blog, as I mention, relied on images hosted on my old site. Right now I'm not actually sure where those photos are! While I took a backup of all the code and other data for www.davep.org when I did the big reboot (storing it all up on GitHub), I seem to have stripped out all of the photos. This makes sense as there was a lot of data there. Making sure I had a backup of those files feels like something I would do -- I hang on to all sorts of data -- but at the moment I can't locate them1.
To make this work, for this to stand any chance of working, I need to pull them all back out from somewhere.
Will I do this? I don't know yet. The seed is there, the itch is waiting to be scratched. I look at the age span of this blog, and the calendar page, and think it could be really cool to really back-fill it from my older blogs. The graph might end up looking really funky.
On the other hand: am I just trying to preserve irrelevant things as a way to make work for myself (albeit "work" that is fun; after all coding is a hobby as well as a living).
On the gripping hand: if I can get the images back, a wasteland of links to sites that don't exist any more does, at the very least, provide a history of what was and is no longer.
I should point out that I have the original photos all backed up any number of ways and in multiple locations, but it's the specific jpeg files with their specific names as appeared in the photo library on my site that I need to make this work. ↩
The experiment with building an MCP server continues, with some hacking on it happening over a couple of hours while killing time in an Edinburgh coffee shop.
It is, of course, a solution looking for a problem, and I suspect I'm the only person who will ever use it, and even then only as a test, but building it is proving interesting.
The main changes in v0.2.0 are:
I turned the current search_guide tool into a line_search_guide tool (because that's what it was doing: a line-by-line search).
I added a body_search_guide tool that treats all the lines in an entry as a single block of text and then does the search in that (so searches over line breaks will work).
I added a read_entry_source tool that, rather than rendering the entry of a guide as plain text with all the markup removed, it instead delivers the underlying "source" for the entry; something that could be useful if you wanted to get an agent to convert it into another marked-up body of text.
I added a markup glossary resource, which technically tells an agent everything it needs to know about Norton Guide markup.
The latter one is interesting. I added it and did some experimenting locally and it seemed to be helpful and I could ask questions about markup and Copilot seemed to use it. Meanwhile, having installed v0.2.0 globally on my machine, and having enabled it, I'm finding that Copilot seems to have zero clue about the markup and instead is using the server to go off and read the guides to work out the markup1.
On the other hand, the new "get source" tool seems to work a treat.
So I suspect I still have some reading/experimenting to do when it comes to resources, so I can better understand why I'd want to provide them and what problem they solve.
All credit to it: it did find CREATING.NG and read the markup out of that. ↩
Recently I've been thinking that it would be interesting to get to know a little about the Model Context Protocol and see what it's about and get a feel for how useful it might be, if at all, for anything I do.
As always happens when I want to try out something new, I reached for a problem I know well so I don't have to get bogged down in solving the problem itself. As almost always happens, I decided I should base it around Norton Guides.
Part of the point of MCP seems to be providing an interface over sources of data and actions, that an LLM might not otherwise be able to cope with, and so it sounded to me like providing a bridge to the content of Norton Guide files would be a perfect test. Of course, this isn't the first time I've bridged LLMs and NG files, but this is obviously intended to be a more generic solution than throwing a Markdown file at NotebookLM.
Earlier this afternoon I sat down and did some reading, and then decided to throw the problem at GitHub Copilot. I told it I wanted to use my NGDB library as the core of the tool, and that it should wrap it up with FastMCP. The initial result was... a bit of a mess. It sort of worked, sort of, but it also seemed to try and put together a project that mostly looked how my Python repos look, but with some bits just wrong.
So far I've given the code a fairly quick read over, and I can see what it's doing and how it's going about this. This approach obviously has the disadvantage that I didn't hand-write it so there's still a lot to read to really appreciate what's going on; on the other hand, it does have the advantage that it's implemented a tool based on my library so I know what to expect it to be doing.
There will be more code reading happening, and I also intend to look to tidy up the code more and perhaps hand-add some more features.
I very much doubt that this particular MCP server is going to be any use to anyone, but as a proof of concept it works well for me. If I were in a position of needing to build something genuinely useful, I now have a start and a vague idea.
On the other hand: once again, as with other projects I've done related to Norton Guides, this is a tool that helps keep the content available and accessible; that alone is one reason for me to tidy this up and move it towards v1.0.0 and keep it maintained.
If you fancy having a play, some (currently Copilot-generated) documentation can be found on the server's dedicated site. When I get a bit more time I'm going to flesh this out.
As I've mentioned a few times on this blog, I've long had a bit of a thing for writing tools for reading the content of Norton Guide files. I first used Norton Guides back in the early 1990s thanks to the release of Clipper 5, and later on in that decade I wrote my first couple of tools to turn guides into HTML (and also wrote a Windows-based reader, then rewrote it, wrote one for OS/2, wrote one for GNU/Linux, and so on).
One tool (ng2html) got used by a few sites on the 'net to publish all sorts of guides, but it's not something I ever got into doing myself. Amusingly, from time to time, because I had a credit on those sites as the author of the conversion tool, I'd get random emails from people hoping I could help them with the topic of whatever guide they'd been reading. Sometimes I could help, often not.
From what I've recently been told two of the biggest sites for this sort of thing (they might even have been the same site, or one a copy of the other, I didn't really dive into them too much and wasn't sure who was behind them anyway) have long since gone offline. This means that, as far as I can tell, a huge collection of knowledge from the DOS days is a lot harder to get to, if it hasn't disappeared altogether.
This makes me kind of sad.
Edit to add: digging a little, one of the sites was called www.clipx.net and it looks to have long-since gone offline. It is on archive.org though. The other was x-hacker.org which, digging a wee bit more, seems to have been a copy of what was on clipx.net.
There's one wrinkle to this though. While the other sites seemed to just publish every NG file they got their hands on, I'd prefer to try and do it like this: publish every guide I have in my collection that I have a licence or permission to publish; or as near as possible1
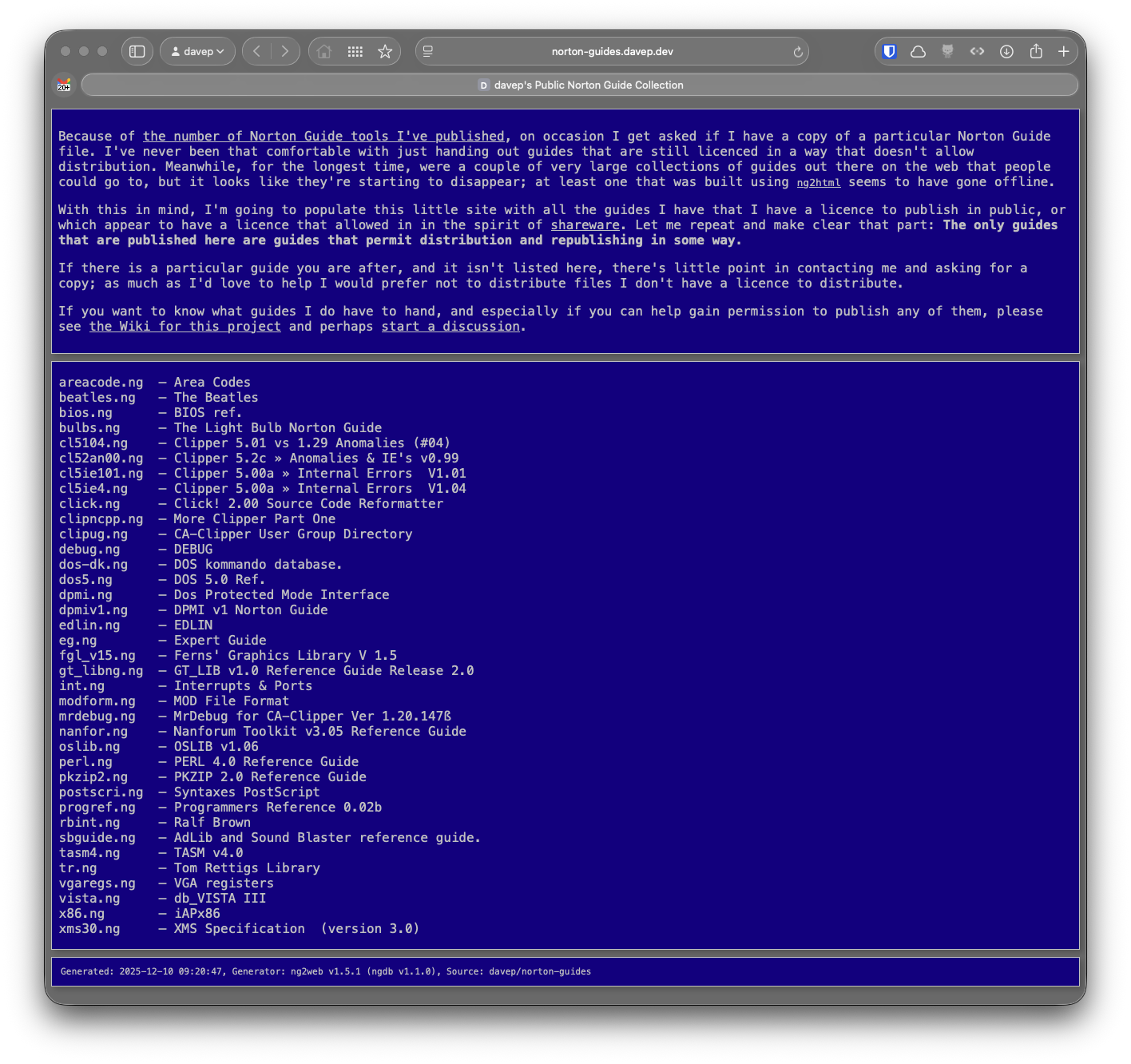
Given all of this, norton-guides.davep.dev has been born. The repository that drives it is on GitHub, and I have a wiki page that lists all the guides I have that I could possibly publish, showing what I know about the copyright/licence of each one and what the publishing state is.
So with this, I'm putting out a call for help: if you remember the days of Norton Guide help files, if you have Norton Guide help files I don't have, and especially if you are the copyright-holder of any of these files and you can extend me the permission to open them up, or if you know the right people and can get me in touch with them, DROP ME A LINE!
I'd also love to have others join me in this... quest. So if you want to contribute to the repository and help build it up I'd also love to hear from you.
I will possibly be a little permissive when it comes to things that I believe contain public domain information to start with. ↩