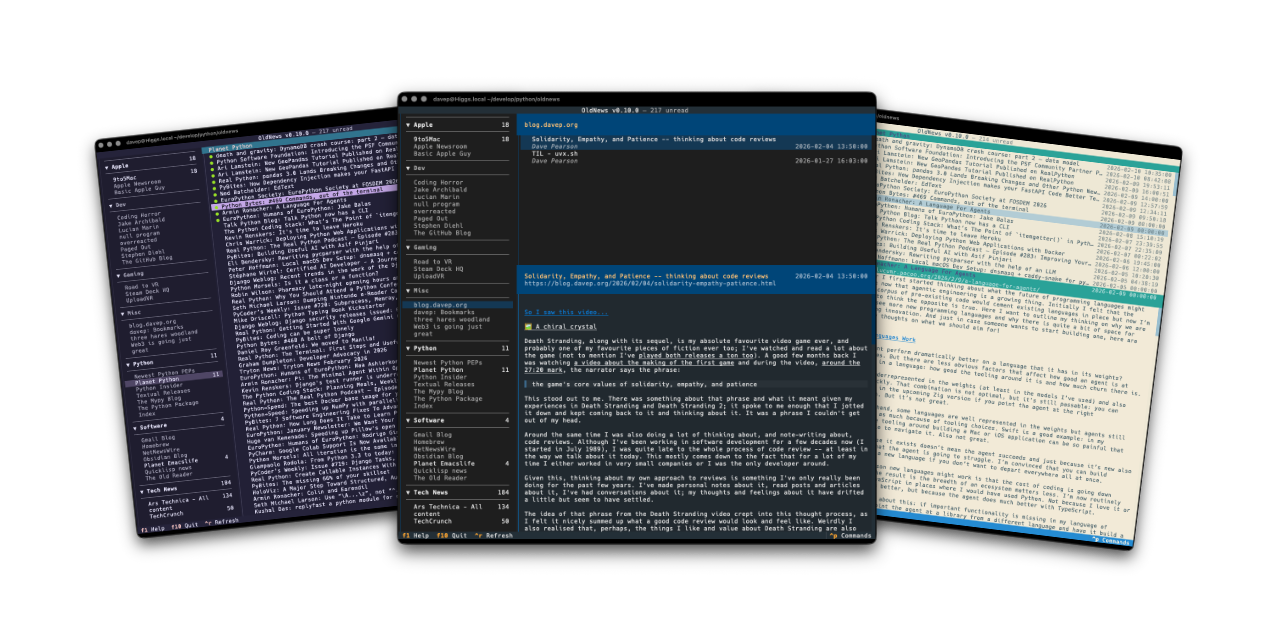
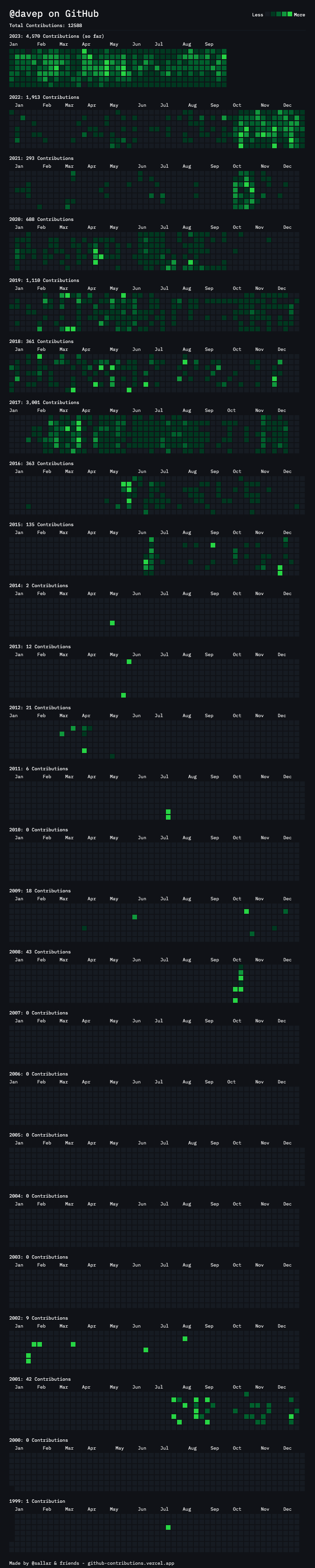
I've made a minor bump to OldNews, my terminal-based client for TheOldReader. There's no significant change in this release, but it does change the dependency on html-to-markdown.
Since I initially released the application, this library seems to have been through a couple of significant changes, and not every breaking change seems to have resulted in a major version bump. OldNews doesn't pin this dependency to a major version (I try not to, only ever setting lower-bounds for dependencies where possible), so it's fair that a change there can break things. I also think it's fair to hope that minor version changes won't cause trouble.
Recently, I've seen the library update with a minor version change and it's flat-out caused runtime errors, either because the API has changed, or because of an error being thrown by legitimate use of the API.
Most recently, such an error happened, and was fixed by the time I noticed it, but the release that was made never made it up to PyPI. This left OldNews stuck not working. Because of this I had to pin the library to an earlier version.
It's now been updated again and PyPI is correct, so I think it's safe to relax the pin.
Fingers crossed...

{kind=link}