Yesterday I read a rather positive post about BlogMore, which was lovely to see. But... when I saw the link for it over on Mastodon I noticed something wasn't quite right about the description in the preview:
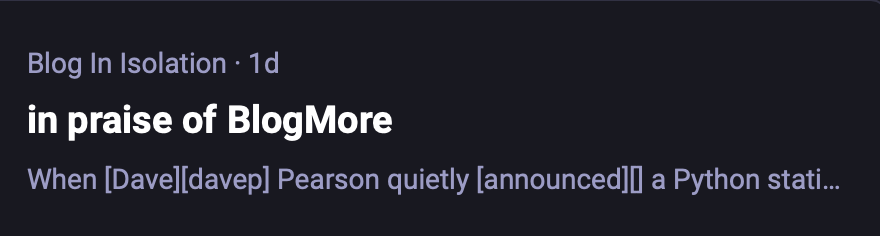
See, when BlogMore makes a post, if the author of the post hasn't provided a description in the frontmatter, the first paragraph of text will be used instead. When doing this the code should strip out any markup (and also skip any initial images, that sort of thing).
But, as you can see, there are things like [Dave][davep] in that description. So I checked in with Andy and that was something that came from the underlying Markdown. After a bit of checking, it became obvious that the code in BlogMore was only looking for and removing inline links, but wasn't doing anything about reference links.
So, as usual, one prompt later and the issue was handled.
As it stands, I don't think I'll keep up with the current approach. It doesn't feel quite right to me. The whole point is that the Markdown should be rendered down to pure text and then the first actual paragraph of text is used. The code I have there now is doing some regexp-based mucking about as an approximate approach. It works, more or less, but it feels like it's implementing a poor Markdown parser when there's a Markdown parser already built in.
Given this, at some point soon, I might have a play and look at the idea of "let's have a Markdown to pure text parser" and then use that. I could see it being useful for other purposes too.
Anyway, the upshot of all of this is that BlogMore v2.6.0 is now available and it handles the stripping of reference links from the description, plus the recently-added strikethrough markup too.