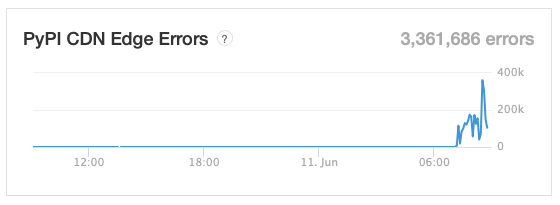
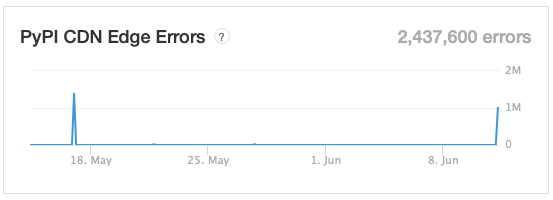
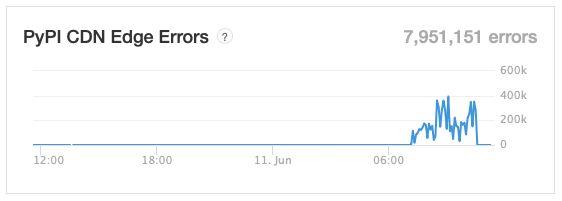
Rogallo v0.2.0 is now available. This version fixes some issues with links, makes gemtext parsing better conform with the specification, and also makes it easier to see where a link will take you.
The first issue is a fix to how page-relative links were resolved if the page you were viewing was the result of a redirection. What was happening was the links were being resolved relative to the initial URI, rather than the final URI of the redirection. This was most noticeably a problem when following links in the geminispace equivalent of webrings. The main change took place in Wasat, with Rogallo making use of the new Response.uri property.
The second fix was to how I parse gemtext. The initial parser was close enough, but I noticed there were some finer points relating to whitespace that I hadn't paid attention to (mainly due to skim-reading the specification). For example, I expected links to always start with => followed by a space, when in fact a link can simply start with a => and then be followed by the URI with no space.
link-line = "=>" *WSP URI-reference [1*WSP 1*(SP / VCHAR)] *WSP CRLF
Similar improvements to the detection of headings and quotes have also been added.
Finally, I've added a couple of features which make it easy to know where a link will take you. The first is that I've added a tooltip to each link, so that when you hover the mouse cursor over it the URI will be displayed. But, because not everyone is mouse-oriented in the terminal1, I've also added a status bar to the main viewer panel that shows the URI of the focused link.

As you tab through the links it will update, of course.

This should ensure that links are less likely to be surprising.
If any of this sounds interesting and you want to have a play, Rogallo is licensed GPL-3.0 and available via GitHub and also via PyPI. If you have an environment that has pipx installed, you should be able to get up and running with:
pipx install rogallo
It can also be installed using uv:
uv tool install rogallo
If you don't have uv installed, you can use uvx.sh to perform the installation. For GNU/Linux, macOS, or similar:
curl -LsSf uvx.sh/rogallo/install.sh | sh
or on Windows:
powershell -ExecutionPolicy ByPass -c "irm https://uvx.sh/rogallo/install.ps1 | iex"
Once installed, run the rogallo command.
Quite right too. ↩