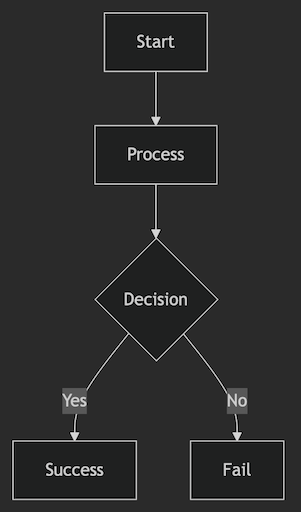
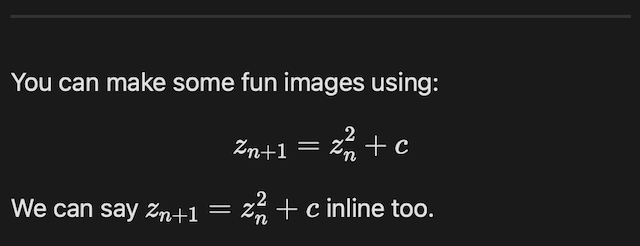
After recently adding Mermaid and maths support to BlogMore, I got to thinking that it now has connections with a handful of third-party resources. While almost all of them are optional (only FontAwesome comes close to being a hard requirement), it does mean that there are resources the user doesn't directly supply or control, and for which the URLs are hard-coded in the source for BlogMore.
I wasn't keen on this. While it's my intention to keep an eye on things and, periodically, check on those libraries and see if they need an update, I felt it was important that the user could override them on their own, without waiting on me.
So v2.43.0 adds a third_party section to the configuration file to give full control over these resources. The full version of it looks like this:
third_party:
mermaid:
script_url: "https://cdn.jsdelivr.net/npm/mermaid@11/dist/mermaid.esm.min.mjs"
katex:
css_url: "https://cdn.jsdelivr.net/npm/katex@0.16.9/dist/katex.min.css"
js_url: "https://cdn.jsdelivr.net/npm/katex@0.16.9/dist/katex.min.js"
mathjax:
js_url: "https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js"
fontawesome:
metadata_url: "https://raw.githubusercontent.com/FortAwesome/Font-Awesome/6.7.2/metadata/icons.json"
webfonts_base: "https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.7.2/webfonts"
css_url: "https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.7.2/css/all.min.css"
woff2_url: "https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.7.2/webfonts/fa-brands-400.woff2"
force_graph:
js_url: "https://unpkg.com/force-graph"
Of course, it's not an all-or-nothing setting; you can just set one of the values. So if you wanted to override the force_graph value it's enough to do:
third_party:
force_graph:
js_url: "https://unpkg.com/force-graph"
Hopefully this adds some useful flexibility. As well as giving the option to use a different version of a resource, it also allows you to host your own copy and refer to that instead. Heck, it would even allow totally replacing a library with a different one that has the same API, should you ever find yourself in that situation.