New Things On PyPi
Posted on 2022-12-01 22:13 +0000 in Python • Tagged with Python, coding, Textual, PyPi • 4 min read
An update
So, it's fast approaching 2 months now since I started the new thing and it's been a busy time. I've had to adjust to a quite a few new things, not least of which has been a longer and more involved commute. I'm actually mostly enjoying it too. While having to contend with busses isn't the best thing to be doing with my day, I do have a very fond spot for Edinburgh and it's nice to be in there most days of the week.
Part of the fallout from the new job has been that, in the last couple of weeks, I've thrown some more stuff up on PyPi. This comes about as part of a bit of a dog-fooding campaign we're on at the moment (you can read some background to this over on the company blog). While they have been, and will continue to be, mentioned on the Textualize blog, I thought I'd give a brief mention of them here on my own blog too given they are, essentially, personal projects.
gridinfo
This is one I'd like to tweak some more and improve on if possible. It is,
in essence, a Python-coded terminal tool that does more or less the same as
slstats.el. It started out as a
rather silly quick
hack, designed
to do something different with
rich-pixels.
Here's the finished version (as of the time of writing) being put through its paces:
Download from here, or install and
play with it with a quick pipx install gridinfo.
unbored
The next experiment with Textual was to write a terminal-based client for the Bored-API. My initial plan for this was to just have a button or two that the user could mash on and they'd get an activity suggestion dropped into the middle of the terminal; but really that seemed a bit boring. Then I realised that it'd be a bit more silly and a bit more fun if I did it as a sort of TODO app. Bored? Run it up and use one of the activities you'd generated before. Don't like any of them? Ignore them and generate some more! Feeling bad that you've got such a backlog of reasons to not be bored? Delete a bunch!
And so on.
Here's a short video of it in action:
Download from here, or install and play
with it with a quick pipx install unbored.
textual-qrcode
This one... this one I'm going to blame on the brain fog that followed flu and Covid jabs that happened the day before (and which are still kicking my arse 4 days later). Monday morning, at my desk, and I'm wondering what to next write to experiment with Textual, and I realised it would be interesting to write something that would show off that it's easy to make a third party widget library.
And... yeah, I don't know why, but I remembered
qrencode.el and so
textual-qrcode was born!
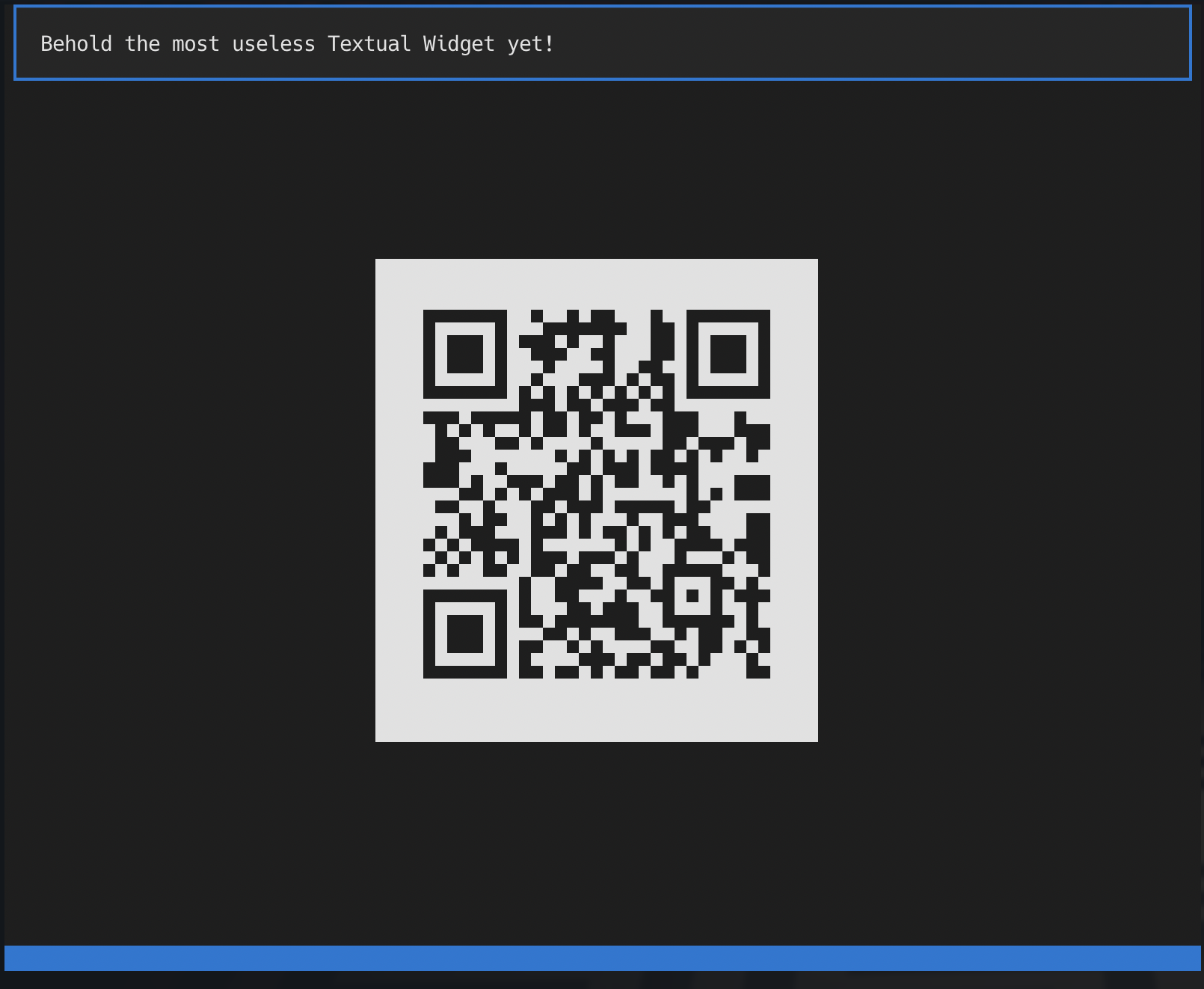
I think the most amusing part about this is that I did it in full knowledge that it would be useless; the idea being it would be a daft way of showing off how you could build a widget library as an add-on for Textual. But... more than one person actually ended up saying "yeah hold up there this could actually be handy!"
If you're one of those people... you'll find it here.
FivePyFive
While I was on a roll putting stuff up on PyPi, I also decided to tweak up my Textual-based 5x5 and throw that up too. This was my first app built with Textual, initially written before I'd even spoken to Will about the position here. At one point I even did a version in Lisp.
It's since gone on to become one of the example apps in Textual itself but I felt it deserved being made available to the world via an easy(ish) install. So, if you fancy trying to crack the puzzle in your terminal, just do a quick:
$ pipx install fivepyfive
and click away.
You can find it over here.
PISpy
Finally... for this week anyway, is a tool I've called PISpy. It's designed as a simple terminal client for looking up package information on PyPi. As of right now it's pretty straightforward, but I'd like to add more to it over time. Here's an example of it in action:
One small wrinkle with publishing it to PyPi was the fact that, once I'd chosen the name, I checked that it hadn't been used on PyPi (it hadn't) but when it came to publishing the package it got rejected because the name was too similar to another package! I don't know which, it wouldn't say, but that was a problem. So in the end the published name ended up having to be slightly different from the actual tool's name.
See over here for the package, and you can install it with a:
$ pipx install pispy-client
and then just run pispy in the terminal.
Conclusion
It's been a fun couple of weeks coming up with stuff to help exercise Textual, and there's more to come. Personally I've found the process really helpful in that it's help me learn more about the framework and also figure out my own approach to working with it. Each thing I've built so far has been a small step in evolution on from what I did in the previous thing. I doubt I've arrived at a plateau of understanding just yet.