My journey to the dark side is complete
Posted on 2020-06-14 20:00 +0100 in Emacs • Tagged with Emacs • 4 min read
Ever since the whole business of "light mode" and "dark mode" really kicked off in the mobile OS world, I've been a fan of the dark modes. On both Android and iOS/iPadOS, when apps became available with dark modes, I'd switch to it. When the operating systems themselves adopted the switch, that's what I went for. As well as having a love for all things black (anyone who knows me personally will know that), I think it just looks better on mobile devices. I can't quite say why, but it just works best for me.
So, when macOS got a supported dark mode, I instantly switched it on, obviously. Then, within a day, I switched it back to light mode. Surprisingly it just didn't work for me, and I wasn't sure why. Since then I've tried living with it a few times and it's rarely lasted more than a few hours. There was something, something I couldn't quite put my finger on, that didn't sit right.
Last Monday I decided to give it another go. This time, however, I thought I'd figured it out. The "problem" was Emacs! As mentioned back in January, for as long as I've used it (so since the mid-1990s), my Emacs has always had a light background -- probably because that's how it came "out of the box" (I'm talking Emacs in graphical mode here; I started with it on OS/2 Warp and then moved to a GNU/Linux X-based desktop). I figured that the contrast between the colour scheme of Emacs, and the rest of the machine, was the issue here.
I spend most of my working day either in Emacs, or in iTerm2 -- often rapidly switching between the two. I've always run iTerm2 in the usual dark background mode with light text. So I figured the problem was having a dark OS desktop, dark terminal, and then a light editing environment. Eventually that'd feel wrong.
So I decided that, for the first time in about 25 years, I should give Emacs
a go with a dark mode. Taking a quick look at popular dark
themes I noticed
sanityinc-tomorrow-night
looked easy on the eye, so I gave that a go (actually, I gave each of the
themes in that set a go, initially starting with
sanityinc-tomorrow-eighties,
but I finally settled on sanityinc-tomorrow-night).
To start with it didn't look too good; not because of a problem with the theme itself, but because, over time, I'd made changes and tweaks to my setup that assumed I'd be using my usual light theme. After some dabbling and tinkering and trying things out, I got it looking "just so".
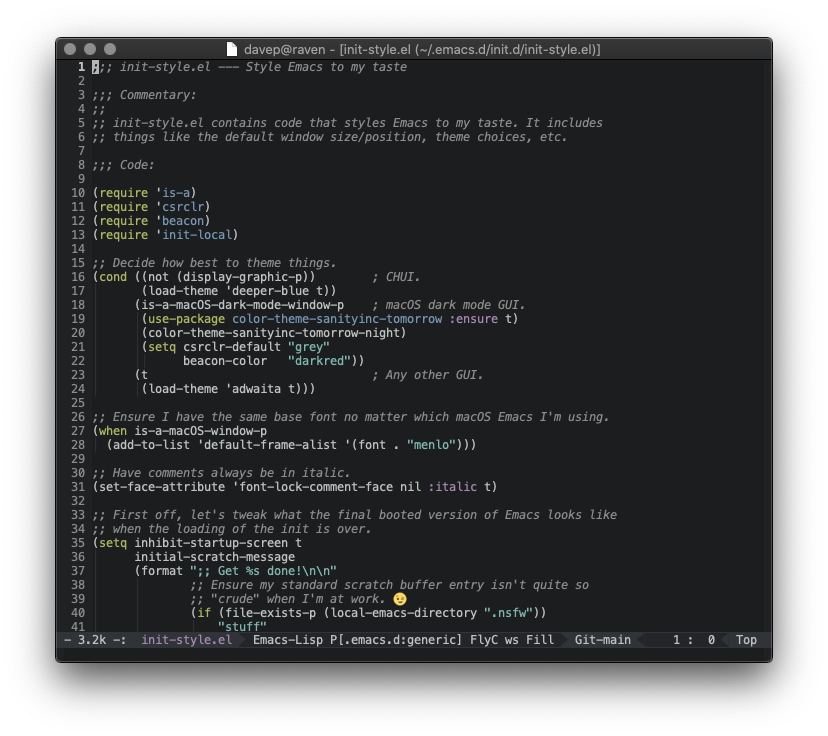
Having got that working, I then thought it would be nice to be able to have
Emacs -- at least on restart -- adapt to me switching between dark and light
mode on macOS. It turns out that detecting if macOS is in dark mode is easy
enough, the command defaults read -g AppleInterfaceStyle will emit Dark
if in dark mode. So, knowing that, I updated my personal package for
checking things about the environment that Emacs is in to use that
information:
(defconst is-a-macOS-dark-mode-window-p
(and
is-a-macOS-window-p
(string= (shell-command-to-string "defaults read -g AppleInterfaceStyle") "Dark\n"))
"Are we running in a macOS window in dark mode?")
So, as of now, my Emacs setup is such that, if I'm in graphical mode on macOS and I'm in dark mode, Emacs will use a dark theme, otherwise it'll do what it did before -- with a light background in a graphical mode and a more Borland-a-like blue background when in CHUI mode.
This seems to have made a difference. Almost one week on my work Macbook is still in dark mode, and I've switched both of my personal Macbooks, and my iMac, into dark mode too. I think it's sticking this time. Next up is to give some serious consideration to darkening the web in general. Only now am I noticing just how damn bright most of it is!
As a slight aside to the above, I've also made one other change to Emacs: I've finally dropped the display of scroll bars. In the themes I'm using they didn't look so great, appearing to be distracting. For the past 25 years I've had the scrollbars there, but never actually used them; all they've ever done is serve as a visual aid to where I am in a file. Thing is, I'm not sure I ever really pay that much attention to that either. So, as a test, I've also been running with them turned off and, so far, I'm really not noticing them been gone.
The habits we form that we convince ourselves make sense...

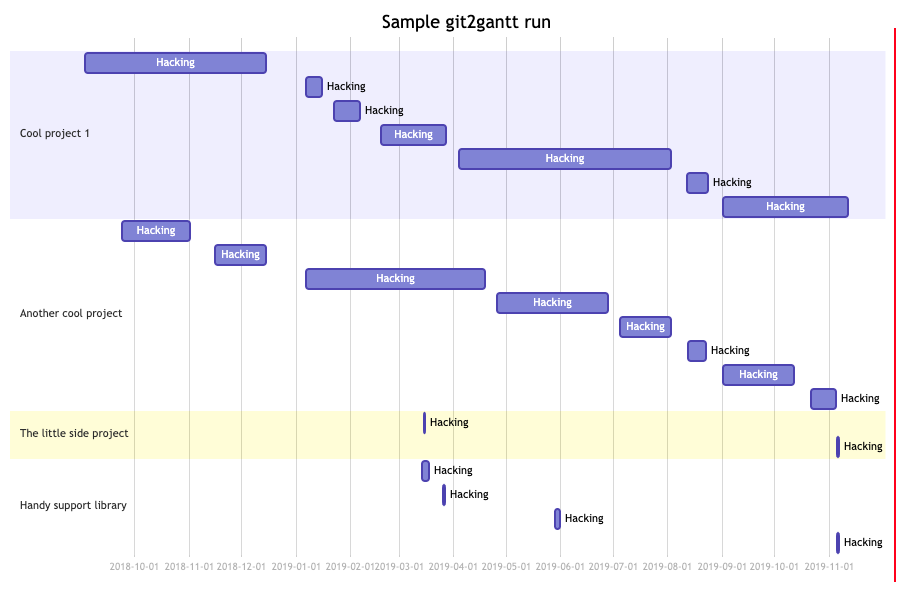
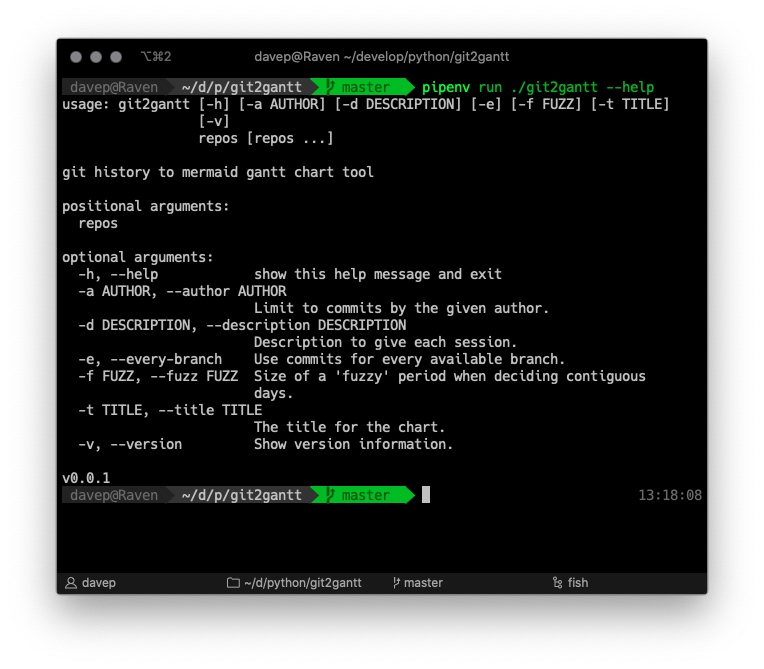 As you can see, it can be run over multiple repos at once, and there's also
an option to have it consider every branch within each repository. Another
handy option is the ability to limit the output to just one author --
perhaps you just want to document what you've done on a repo, not the
contributions of other people.
As you can see, it can be run over multiple repos at once, and there's also
an option to have it consider every branch within each repository. Another
handy option is the ability to limit the output to just one author --
perhaps you just want to document what you've done on a repo, not the
contributions of other people.