Introduction
On Twitter, a few weeks back, @itsBexli asked me how I go about setting up
Python for development on
macOS. It's a
great question and one that seems to crop up in various places, and since I
first got into using
macOS and then
subsequently got back into coding lots in
Python it's absolutely an issue I ran
into.
With my previous employer, while I was the only developer, I wasn't the only
person writing code and more than one other person had this issue so I
eventually wrote up my approach to solving this problem. That document is on
their internal GitLab, but I thought it worth me writing my personal
macOS/Python "rules" up again, just in case they're useful to anyone else.
I am, of course, not the first person to tackle this, to document this, to
write down a good approach to this. Before and after I settled on my
approach I'd seen other people write about this. So... this post isn't here
to try and replace those, it's simply to write down my own approach, so if
anyone asks again I can point them here. I feel it's important to stress:
this isn't the only way or thoughts on this issue, there are lots of others.
Do go read them too and then settle on an approach that works for you.
One other point to note, which may or may not make a difference (and may or
may not affect how this changes with time): for the past few years I've been
a heavy user of pipenv to manage my
virtual environments. This is very likely to change from now on, but keep in
mind that what follows was arrived at from the perspective of a pipenv
user.
So... with that admin aside...
The Problem
When I first got back into writing Python it was on macOS and, really early
on, I ran into all the usual issues: virtual environments breaking because
they were based on the system Python and it got updated, virtual
environments based on the Homebrew-installed Python and it got updated,
etc... Simply put, an occasional, annoying, non-show-stopping breaking of my
development environment which would distract me when I'd sat down to just
hack on some code, not do system admin!
My Solution
For me, what's worked for me without a problem over the past few years, in
short, is this:
- NEVER use the system version of Python. Just don't.
- NEVER use the Homebrew's own version of Python (I'm not even sure
this is an issue any more; but it used to be).
- NEVER use a version of Python installed with Homebrew (or, more to
the point, never install Python with Homebrew).
- Manage everything with
pyenv; which I do
install from Homebrew.
The Detail
As mentioned earlier, what I'm writing here assumes that virtual
environments are being managed with pipenv (something I still do for
personal projects, for now, but this may change soon). Your choices and
mileage may vary, etc... This is what works well for me.
The "one time" items
These are the items that need initially installing into a new macOS machine:
Homebrew
Unless it comes from the Mac App Store, I try and install everything via
Homebrew. It's really handy for keeping track of what
I've got installed, for recreating a development environment in general, and
for keeping things up to date.
pyenv
With Homebrew installed the next step for me is to install pyenv. Doing so
is as easy as:
Once installed, if it's not done it for you, you may need to make some
changes to your login profile. I'm a user of fish
so I have these lines in my
setup.
Simply put: it asks pyenv to set up my environment so my calls to Python go
via its setup.
Plenty of help on how to set up pyenv can be found in its
README.
Once I've done this I tend to go on and install the Python versions I'm
likely to need. For me this tends to be the most recent "active" stable
versions (as of the time of writing, 3.7 through 3.10; although I need to
now start throwing 3.11 into the mix too).
I use this command:
to see the available versions. If I want to see what's available for a
specific version I'll pipe through grep:
$ pyenv install --list | fgrep " 3.9"
This is handy if I want to check what the very latest release of a specific
version of Python is.
The "Global" Python
When I'm done with the above I then tend to use pyenv to set my "global"
Python. This is the version I want to get when I run python and I'm not
inside a virtual environment. Doing that is as simple as:
Of course, you'd swap the version for whatever works for you.
When Stuff Breaks
It seems more rare these days, but on occasion I've had it such that some
update somewhere still causes my environment to break. Now though I find
that all it takes is a quick:
and everything is good again.
Setting Up A Repo
With all of the stuff above being mostly a one-off (or at least something I
do once when I set up a new machine -- which isn't often), the real "work"
here is when I set up a fresh repository when I start a new project. Really
it's no work at all. Again, as I've said before, I've tended to use pipenv
for my own work, and still do for personal stuff (but do want to change
that), mileage may vary here depending on tool.
When I start a new project I think about which Python version I want to be
working with, I ensure I have the latest version of it installed with
pyenv, and then ask pipenv to create a new virtual environment with
that:
When you do this, you should see pipenv pulling the version of Python from
the pyenv directories:
$ pipenv --python 3.10.7
Creating a virtualenv for this project...
Pipfile: /Users/davep/temp/cool-project/Pipfile
Using /Users/davep/.pyenv/versions/3.10.7/bin/python3 (3.10.7) to create virtualenv...
⠙ Creating virtual environment...created virtual environment CPython3.10.7.final.0-64 in 795ms
creator CPython3Posix(dest=/Users/davep/temp/cool-project/.venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/Users/davep/Library/Application Support/virtualenv)
added seed packages: pip==22.2.2, setuptools==65.3.0, wheel==0.37.1
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
✔ Successfully created virtual environment!
Virtualenv location: /Users/davep/temp/cool-project/.venv
Creating a Pipfile for this project...
The key thing here is seeing that pipenv is pulling Python from
~/.pyenv/versions/. If it isn't there's a good chance you have a Python
earlier in your PATH than the pyenv one -- something you generally don't
want. It will work, but it's more likely to break at some point in the
future. That's the key thing I look for; if I see that I know things are
going to be okay.
Conclusion
Since I adopted these personal rules and approaches (and really, calling
them "rules" is kind of grand -- there's almost nothing to this) I've found
I've had near-zero issues with the stability of my Python virtual
environments (and what issues I have run into tend to be trivial and of my
own doing).
As I said at the start: there are, of course, other approaches to this, but
this is mine and works well for me. Do feel free to comment with your own,
I'm always happy to learn about new ways!


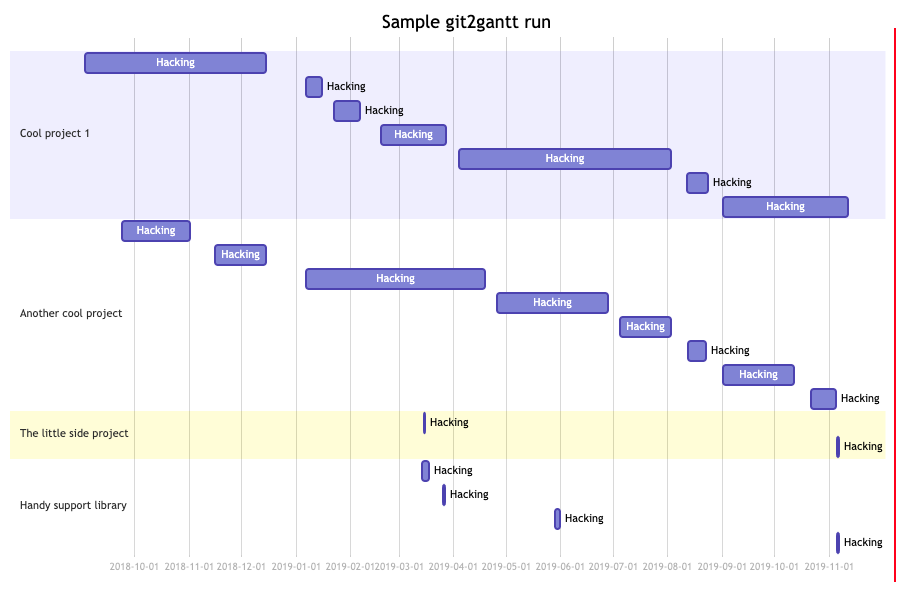
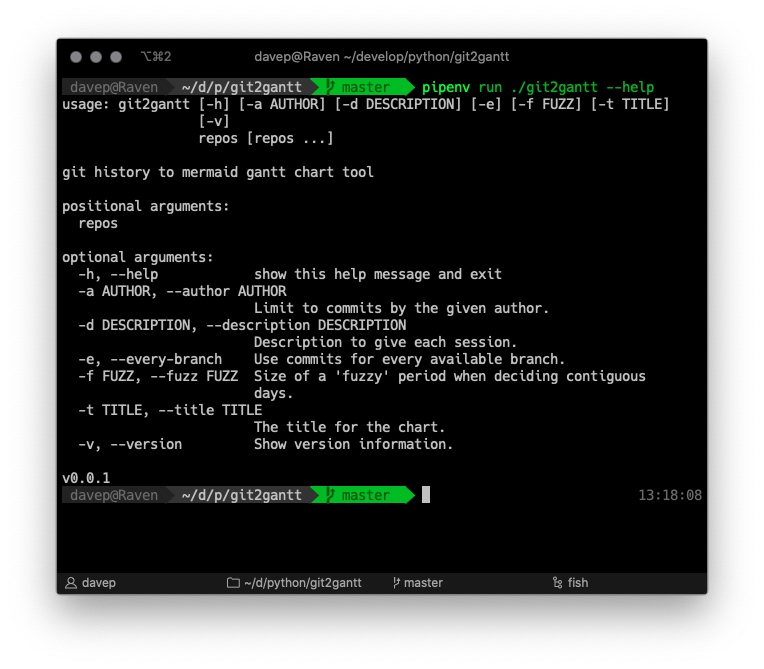 As you can see, it can be run over multiple repos at once, and there's also
an option to have it consider every branch within each repository. Another
handy option is the ability to limit the output to just one author --
perhaps you just want to document what you've done on a repo, not the
contributions of other people.
As you can see, it can be run over multiple repos at once, and there's also
an option to have it consider every branch within each repository. Another
handy option is the ability to limit the output to just one author --
perhaps you just want to document what you've done on a repo, not the
contributions of other people.