Tinboard
Posted on 2023-12-19 09:47 +0000 in Coding • Tagged with Python, terminal, textual • 2 min read
Over the past few weeks I've been working on a new pet project, in part done as a Textual "dogfooding" project, but also because this is a tool I've been wanting for a while now: a terminal-based client for the Pinboard bookmarking service.
The dogfooding side of the development has been helping, uncovering a couple of fun bugs in Textual; plus the act of building this has let me try out a few of the newer features we've recently added to the framework.
What's really important though is this is a tool I actually wanted, and I'm using pretty often. I've written a lot of Textual-based applications over the past year, most small examples, some quite a bit bigger, but none of them really form part of my daily workflow. This changes with Tinboard.
Tinboard is designed as a fully-featured client, allowing for the creation of new Bookmarks, complete with tag suggestion support:
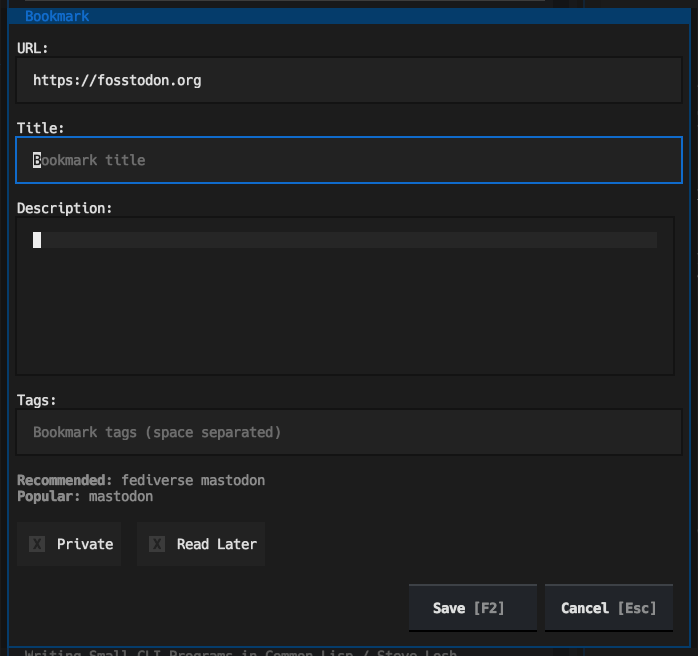
Not only are tag suggestions pulled from Pinboard, but entry of tags can auto-complete, taking completions from both the suggested tags and also tags used amongst your own bookmarks:

That feature was really easy to add thanks to the Suggester
API.
Thanks to the
recently-added
TextArea widget the add/edit dialog allows for proper full editing of the
extended text description of the bookmark too:
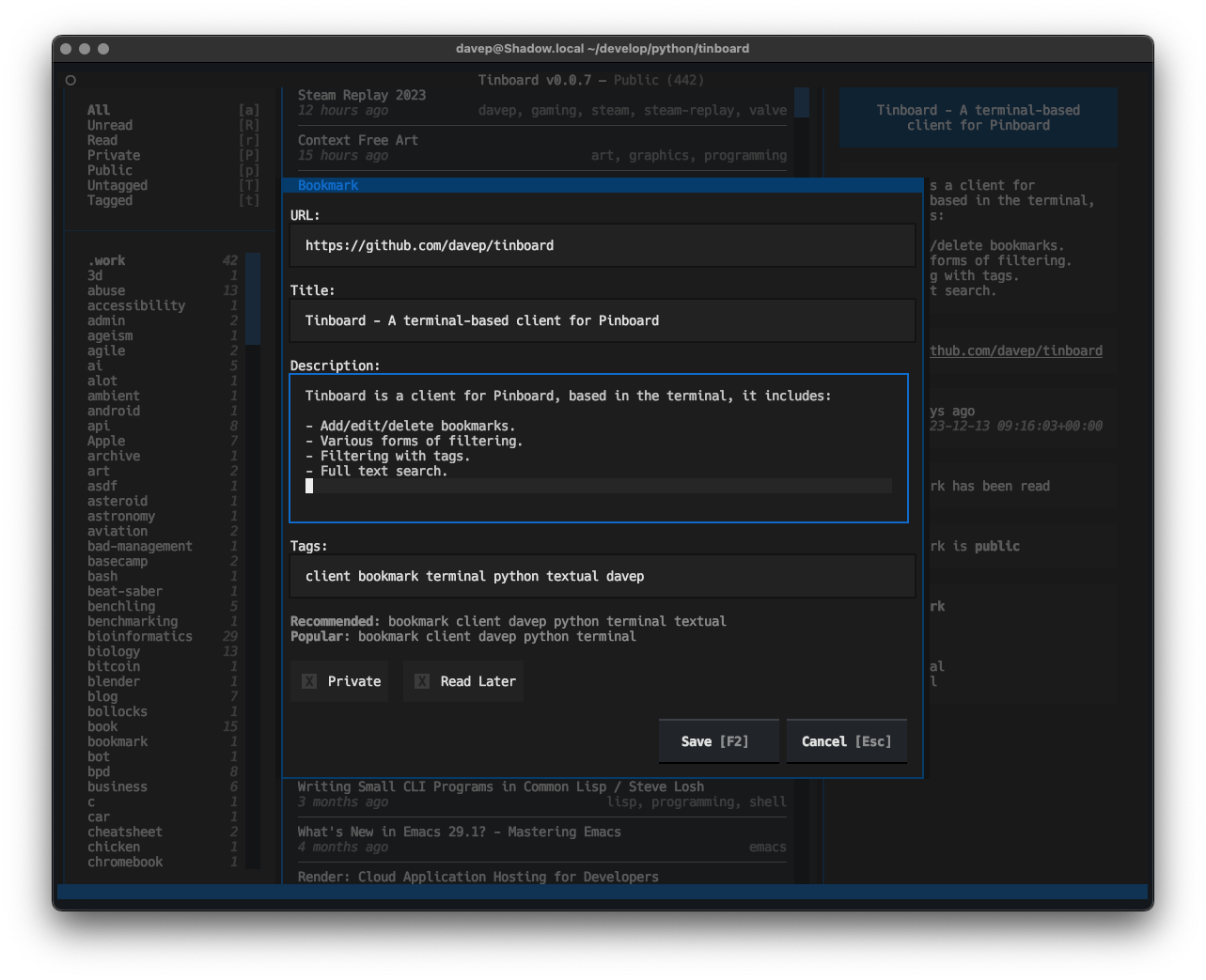
One caveat here is a lack of word-wrapping; but this will be arriving in an update to Textual early in the new year.
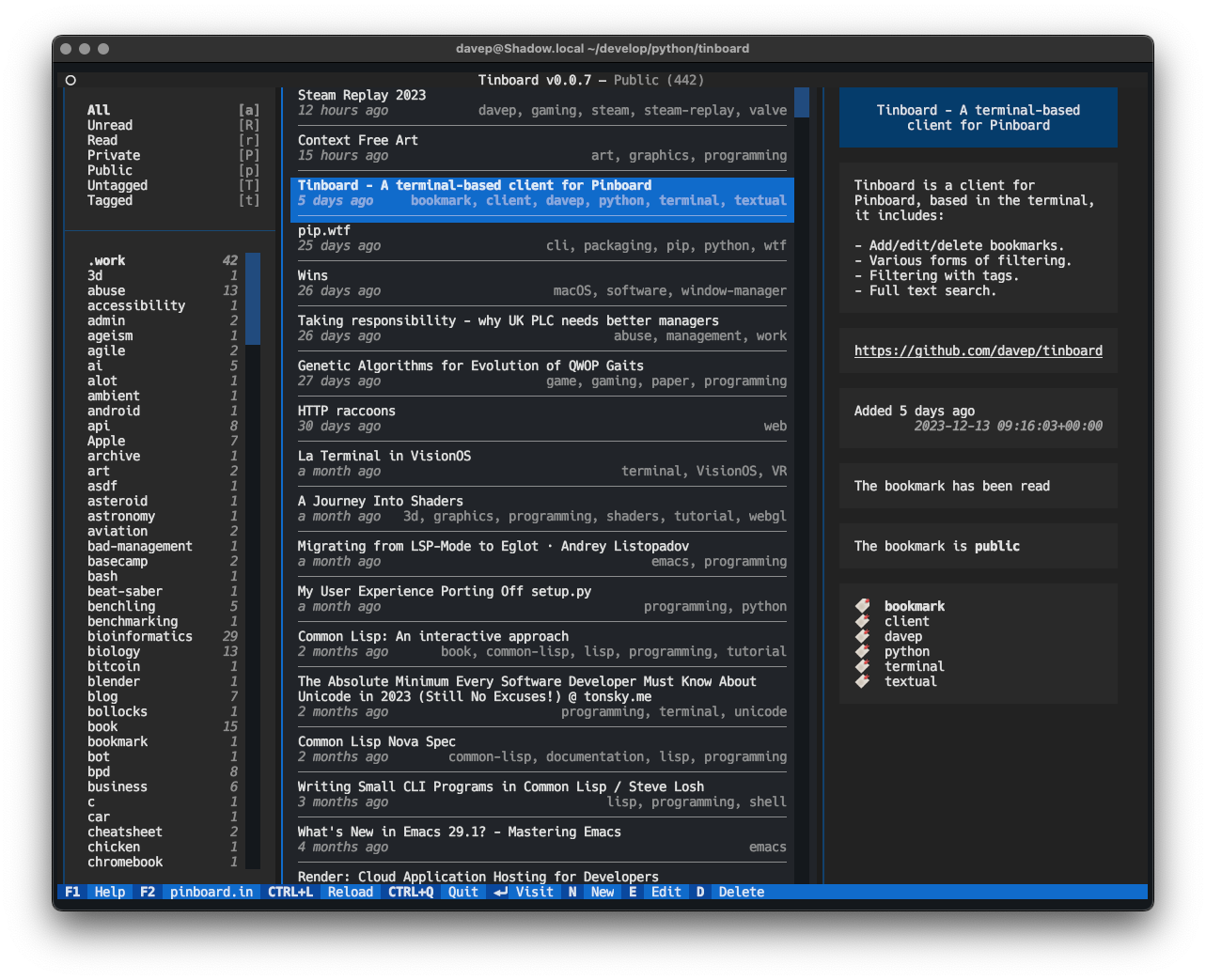
As well as all the usual add/edit/delete facilities, Tinboard is also designed to make it pretty easy to find bookmarks too. There are filtering options for seeing all read/unread, public/private and tagged/untagged bookmarks; this makes bookmark management really easy for me because I can filter for all the untagged and private bookmarks, which are likely the ones that need editing and expanding on, and tidy up my bookmark library.
There is also, of course, full text search too.
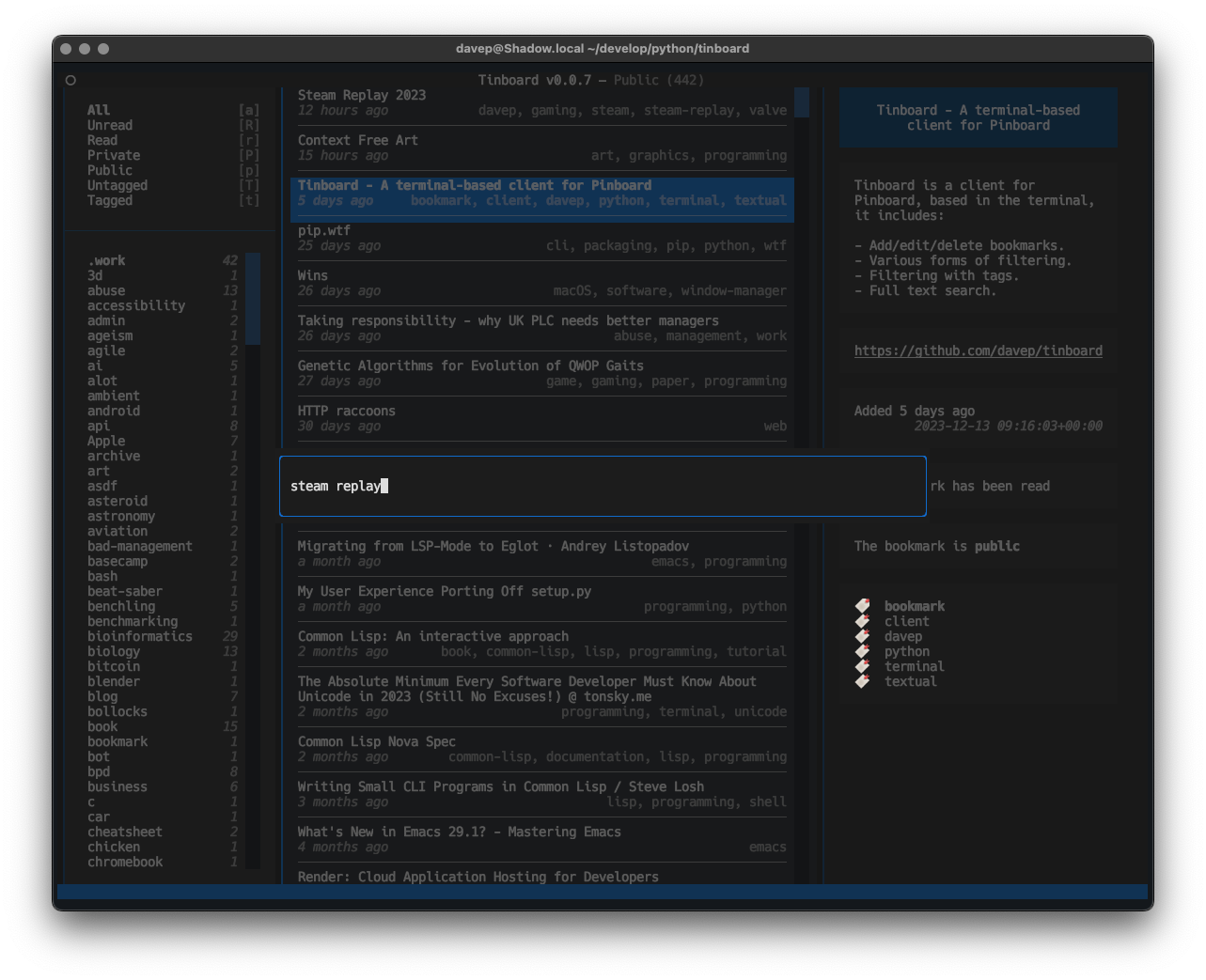
When a filter or search is in operation, the related tags and the like react too:
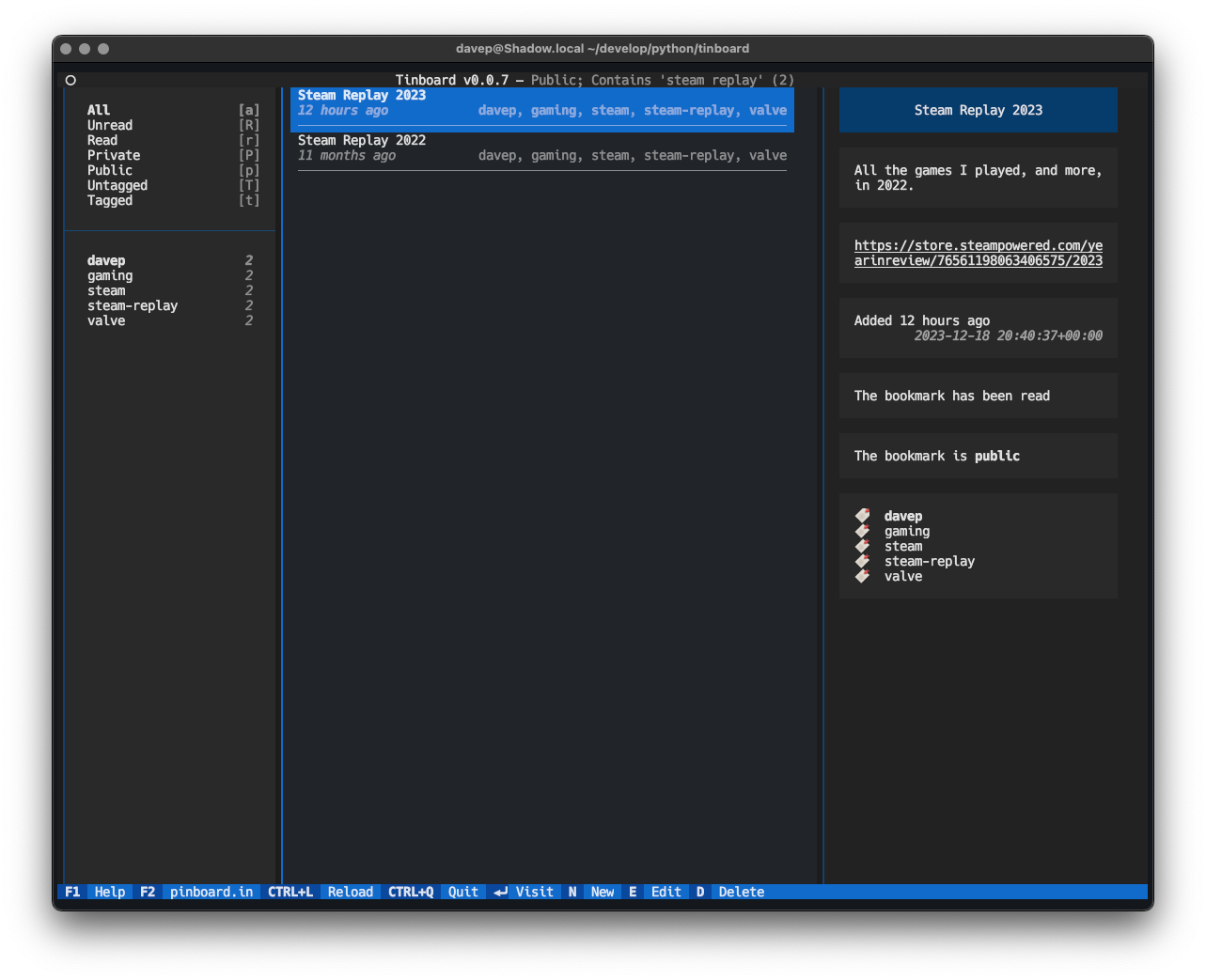
Another thing I've made a point of doing in Tinboard is leaning pretty hard on the Command Palette. No functionality is only available by it (I've done my best to make sure that keyboard is the primary input device here, with keyboard shortcuts for as much as possible). Initially I approached this as a "for the sake of completeness" feature, but already I'm finding that it's a pretty quick method of pulling up a tag filter.
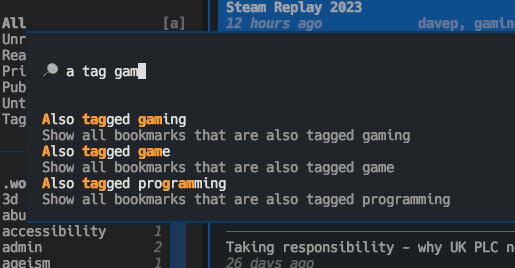
To help make all the features as discoverable possible, I've also ensured there's a pretty comprehensive help screen:
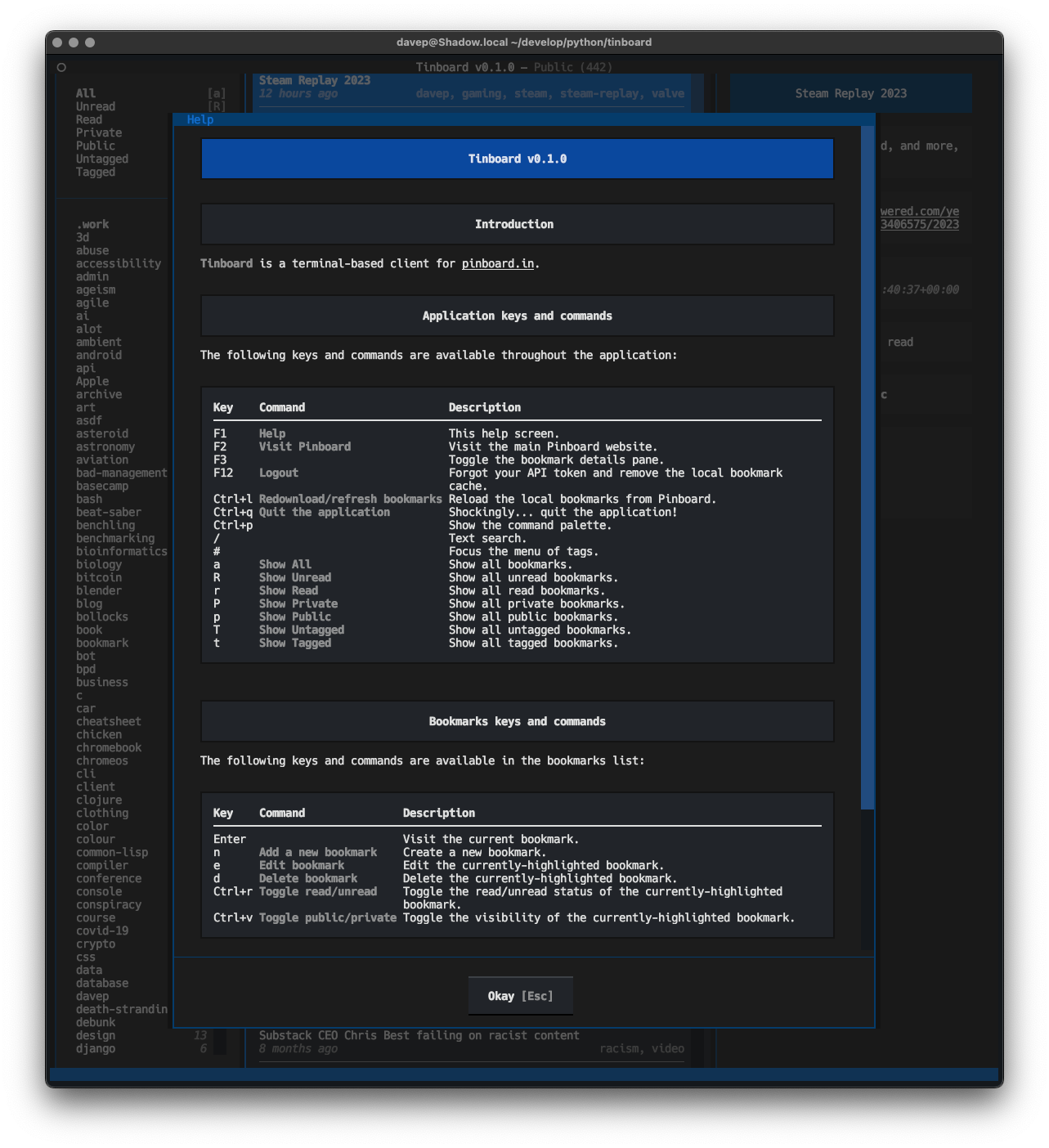
Anyway; that's v0.1.0 out in the wild. I'm pleased with how it's turned out
and there's a few more things I'd like to add. It's licensed GPL-3.0 and
available via GitHub and also via
PyPi. If you have an environment that
has pipx installed you should be able to get up and going with:
$ pipx install tinboard
I hope this is useful to someone else. :-)