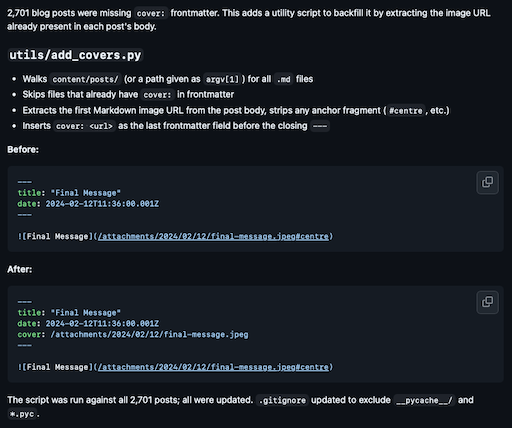
Another day, another tweak to BlogMore. This bump adds a couple of features relating to headings. The main change being that I've added support for custom IDs for links. To borrow from the docs:
If you need a specific id — for example because the auto-generated one is
too long, or because you want a stable id that won't change if you reword
the heading — you can set it explicitly by appending {#your-id} to the end
of the heading line:
### My Great Heading {#custom-id}
This produces:
<h3 id="custom-id">My Great Heading</h3>
The custom id overrides the auto-generated one. Headings without a {#…}
suffix keep their auto-generated IDs as usual.
Headings, of course, have a default "slugged" ID if a custom one isn't provided.
The other main change is that it's now easier for a reader to discover a link to a heading should they want to link someone to a specific part of a post or page. Again, to borrow from the docs:
To make it easy for readers to share a link to a specific section, BlogMore renders a small ¶ symbol at the end of every heading. The symbol is invisible by default and appears when the reader moves the mouse over the heading. Clicking the symbol navigates the browser to that heading's URL fragment, where the address can be copied from the browser's location bar.
The anchor appears and disappears with a smooth fade and does not affect the layout of the page in any way.
Another small change I added was to the "Generated by BlogMore" text that appears at the bottom of every generated page. I always think it's nice if some tool lets you turn that sort of thing off, and I'd not paid attention to that yet. So as of v1.12.0 you can add this to the configuration file:
with_advert: false
and you then don't have to have that at the bottom of each page.
Credit BlogMore if you want, but you don't have to.