Peplum
Posted on 2025-01-25 14:21 +0000 in Coding • Tagged with Python, terminal, textual • 3 min read
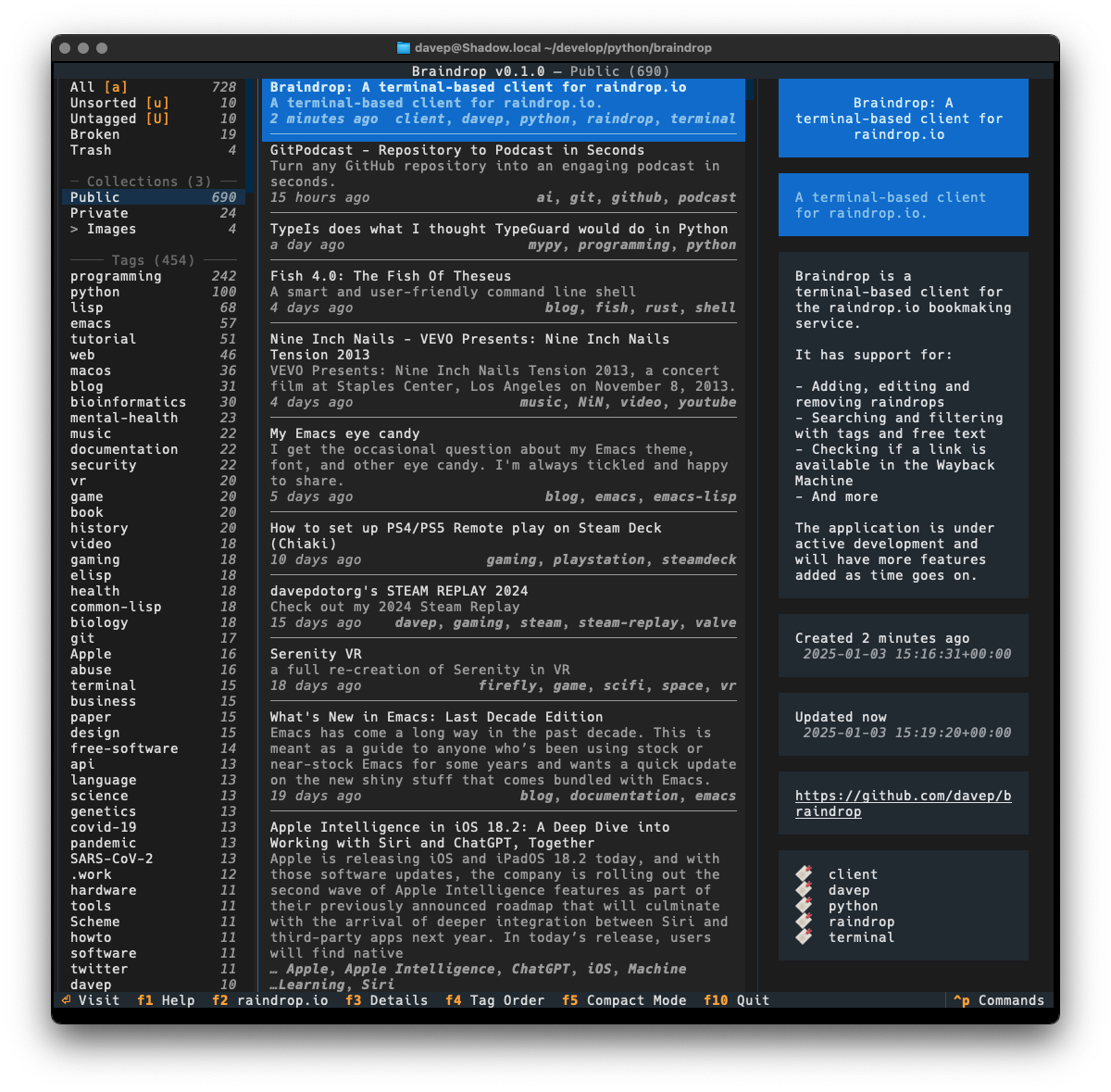
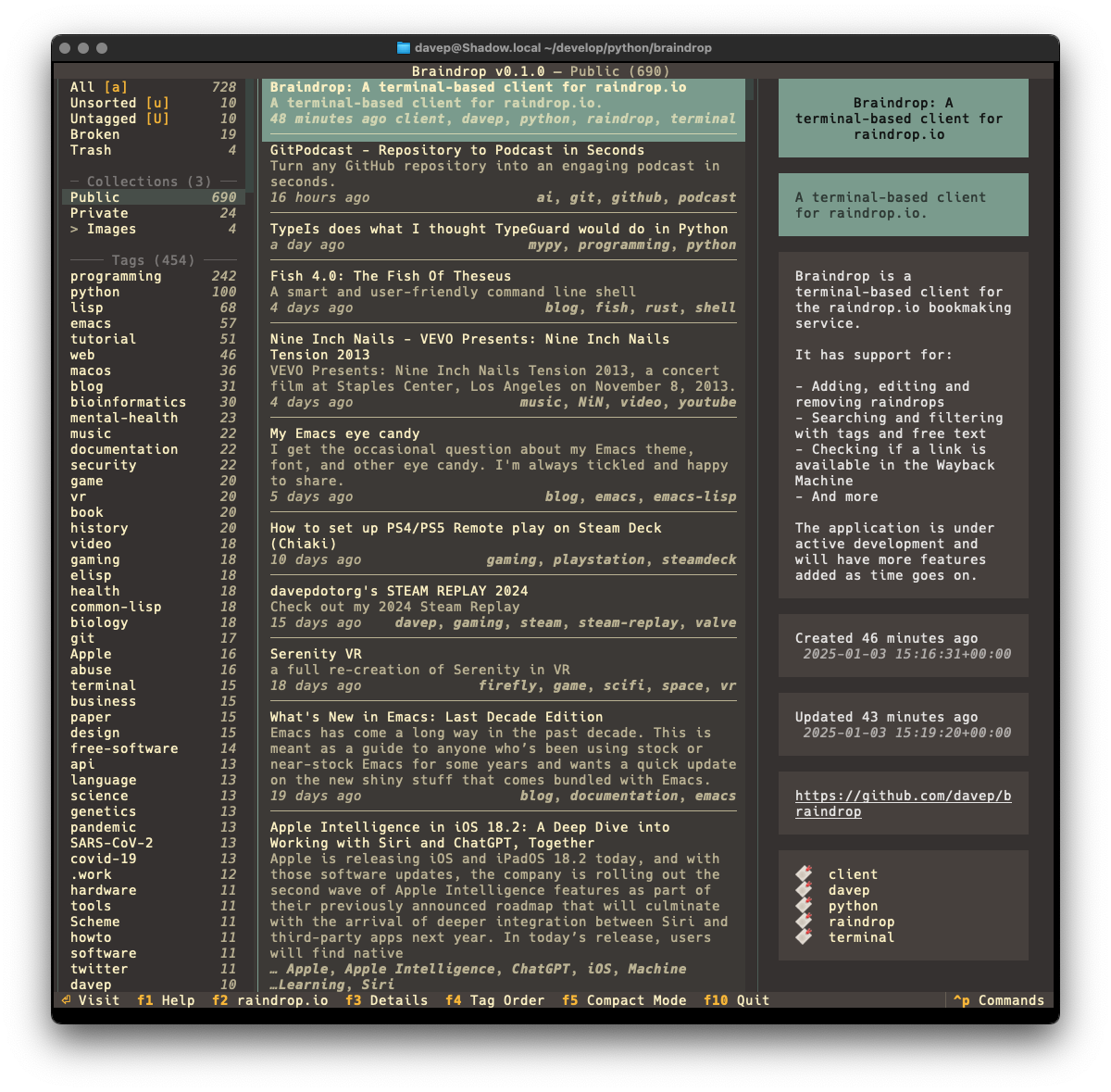
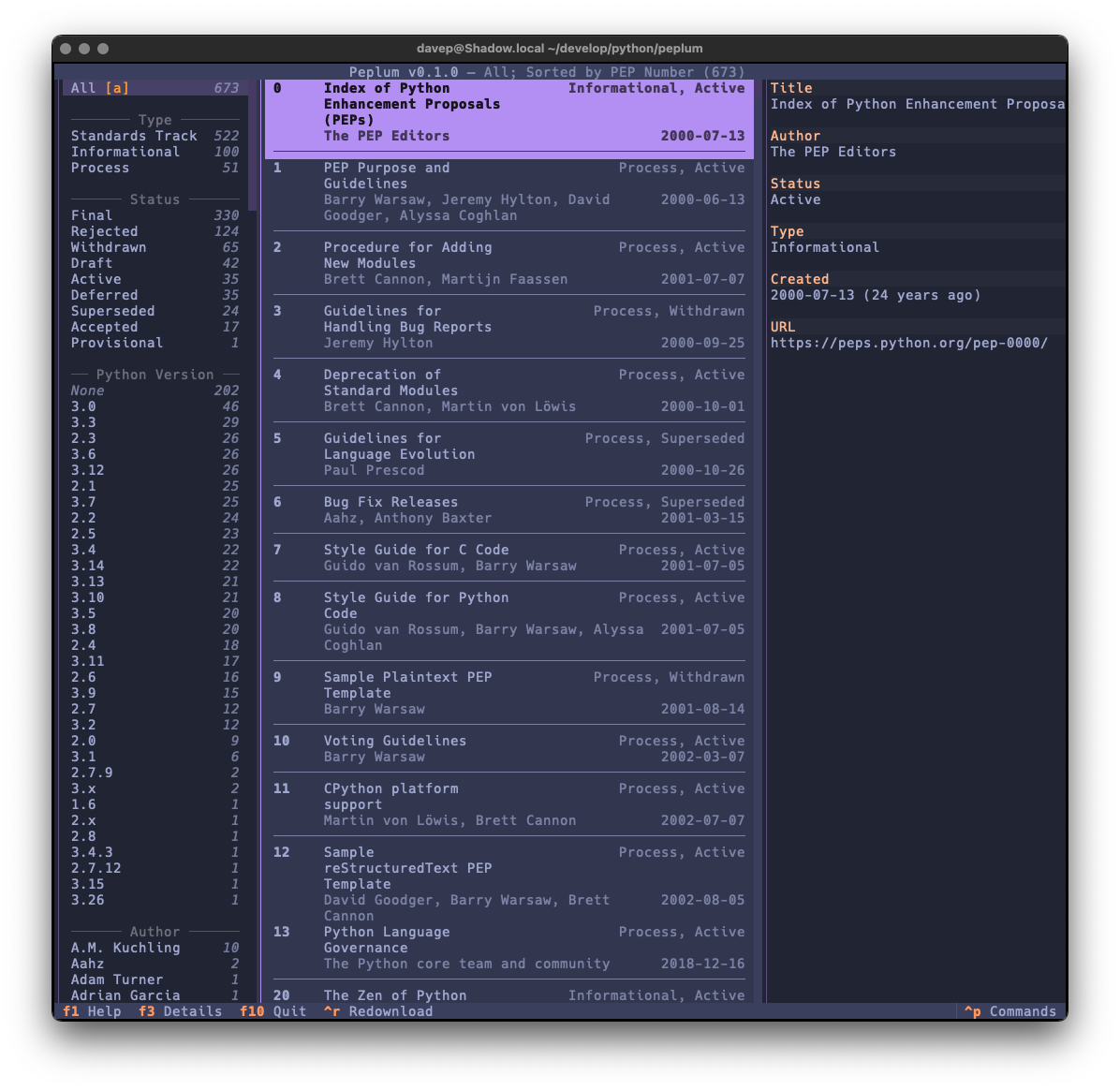
I seem to be back in the swing of writing handy (for me) little terminal-based applications again. Having not long since released Braindrop (which I'm still working on and tinkering with; it'll get more features in the near future, for sure), I had an idea for another tool I'd like to have: something for looking through, searching, and filtering Python PEPs.
As with anyone who is interested in what's happening with Python itself, I subscribe to the RSS feed of the latest Python PEPs, but I also wanted something that would let me look back at older ones in a way that worked "just so" ("just so" being "what feels right for me", of course). Having finished the main work on Braindrop I realised that the general layout of its UI would work here, as would the filtering and searching approach I used.
From this idea Peplum was born!
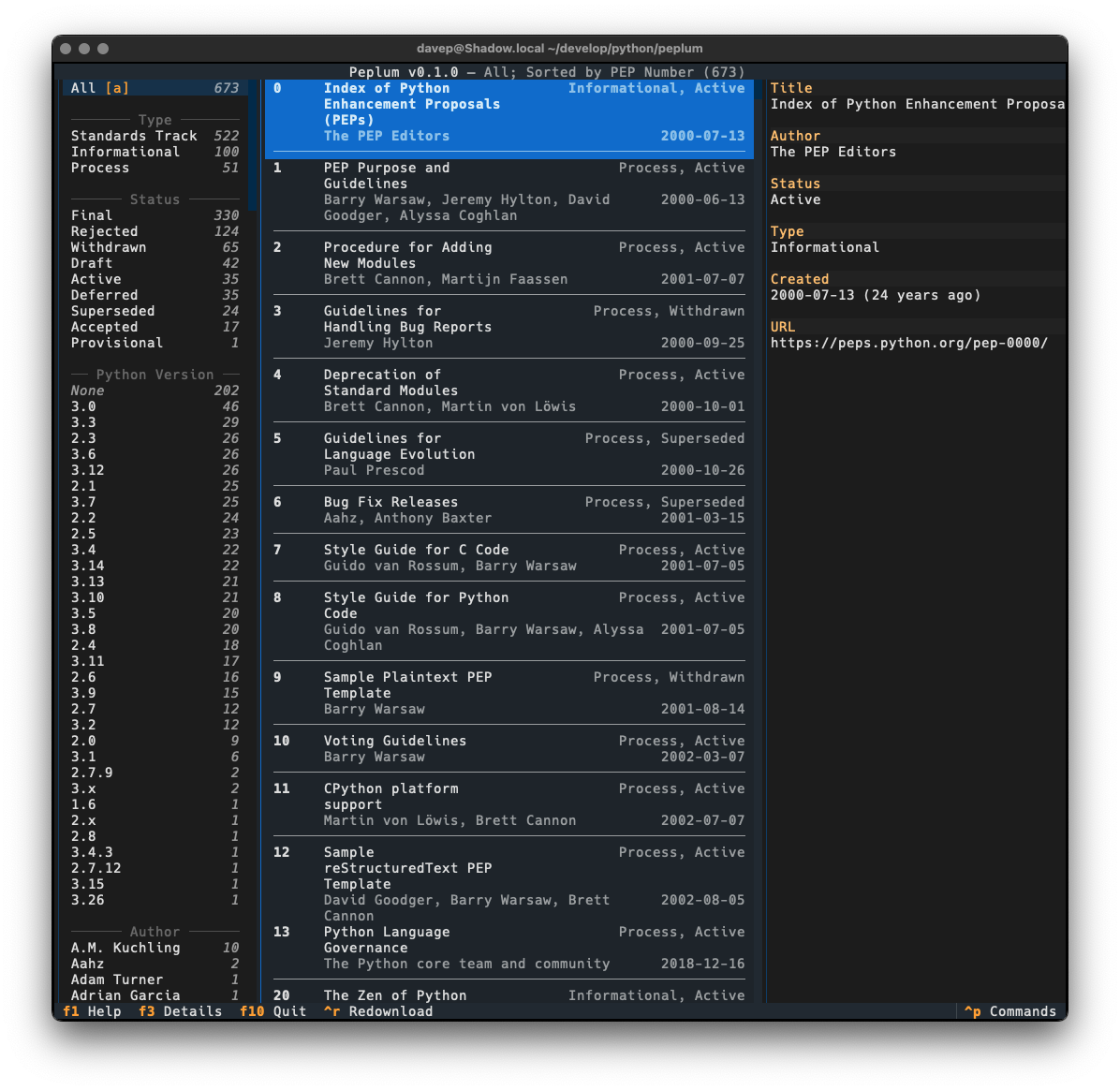
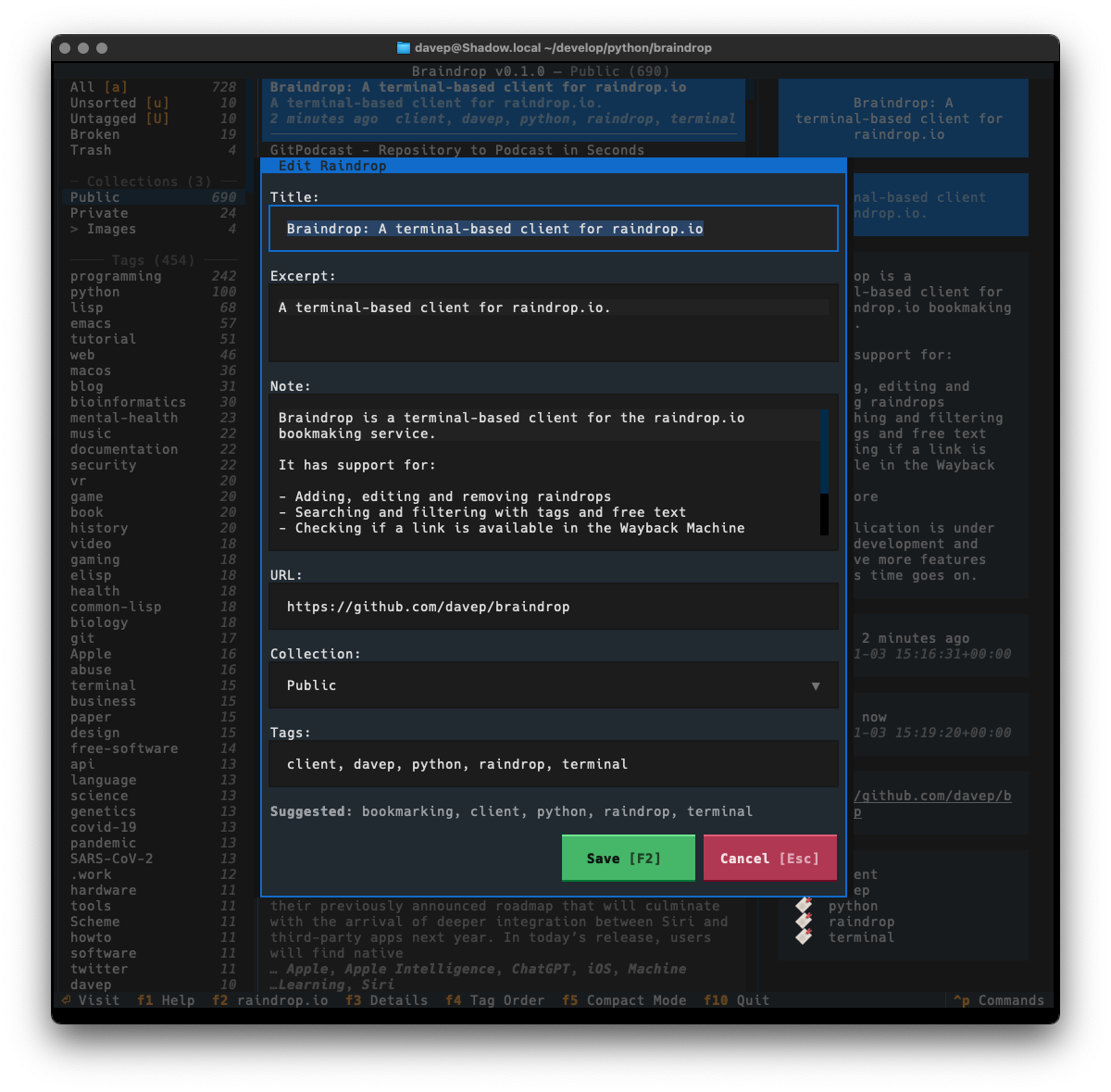
In this first release I've simply concentrated on all things to do with grabbing the list of PEPs and presenting them in a useful way; adding various forms of filtering them; adding the ability to search the metadata; that sort of thing. I aim to keep developing this out over the next few weeks and months, adding things like the ability to make notes, to locally view the text of a PEP, perhaps even to mark PEPs as unread and read, etc.
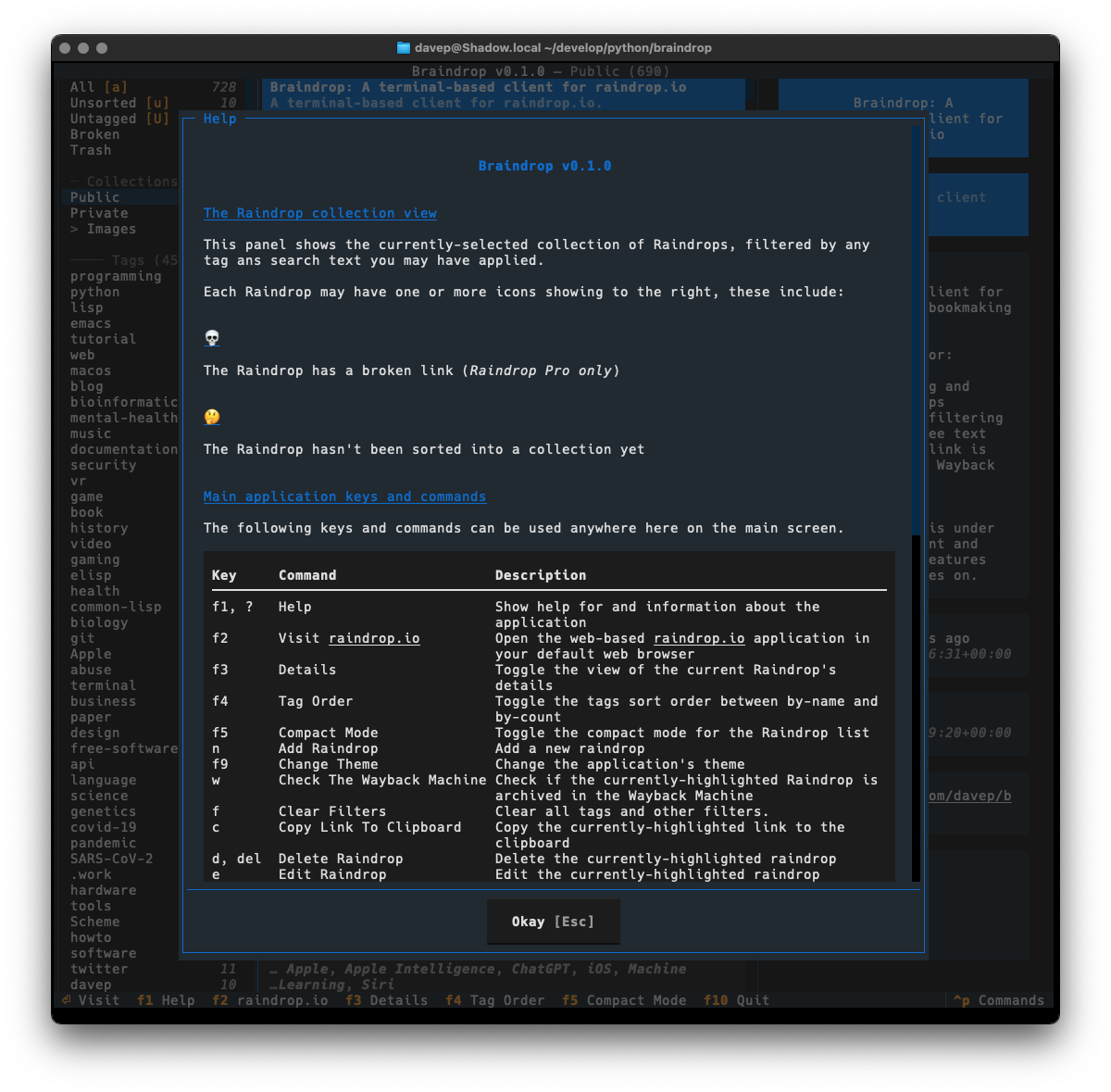
As I mentioned earlier, much of the design was driven by what I did with Braindrop, so once again I've tried my very best to make it keyboard-friendly and as much as possible keyboard-first. This sometimes means having to work against how Textual works, but generally that isn't too tricky to do. I'm once again making heavy use of the command palette and also ensuring that all commands that have corresponding keyboard bindings are documented in the help screen.
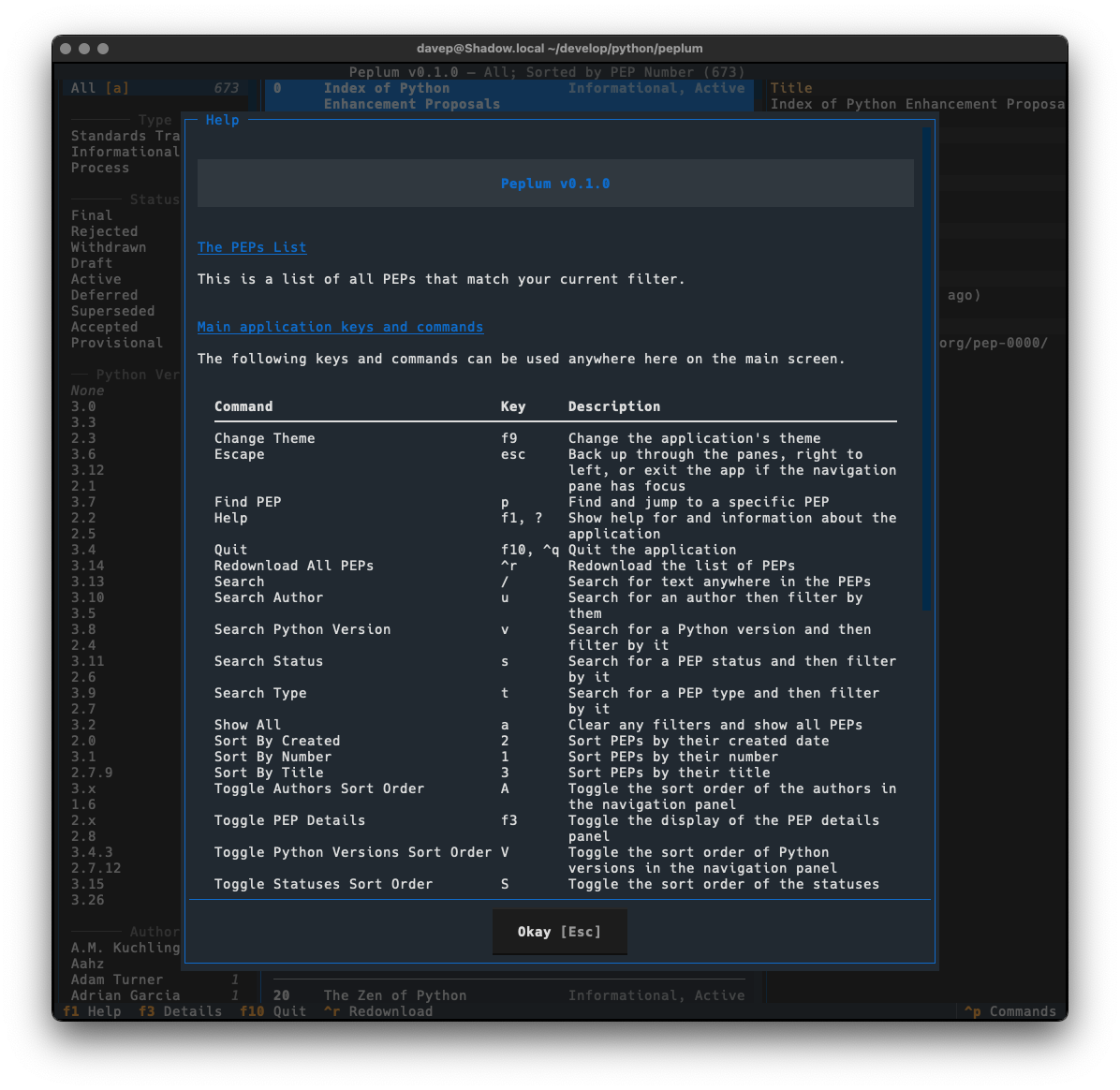
There's enough common code between Peplum and Braindrop, when it comes to this aspect of building a Textual application, that I'm minded to spin it out into a little library of its own. I'm going to sit on this code for a wee while and see how it develops, but I can see me taking this approach with future applications and doing this will stop the need to copy and paste.
It might also be useful to others building with Textual.
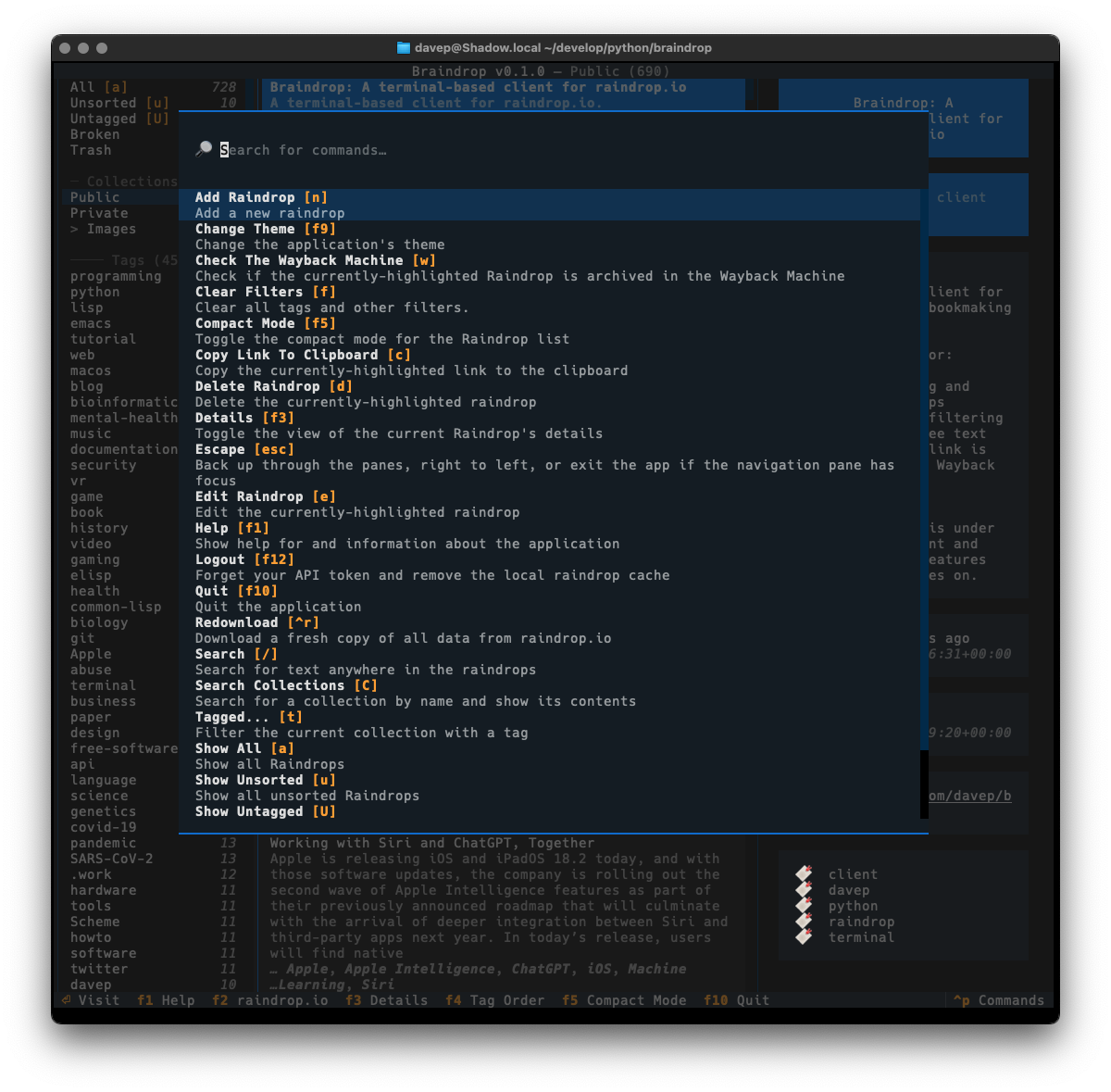
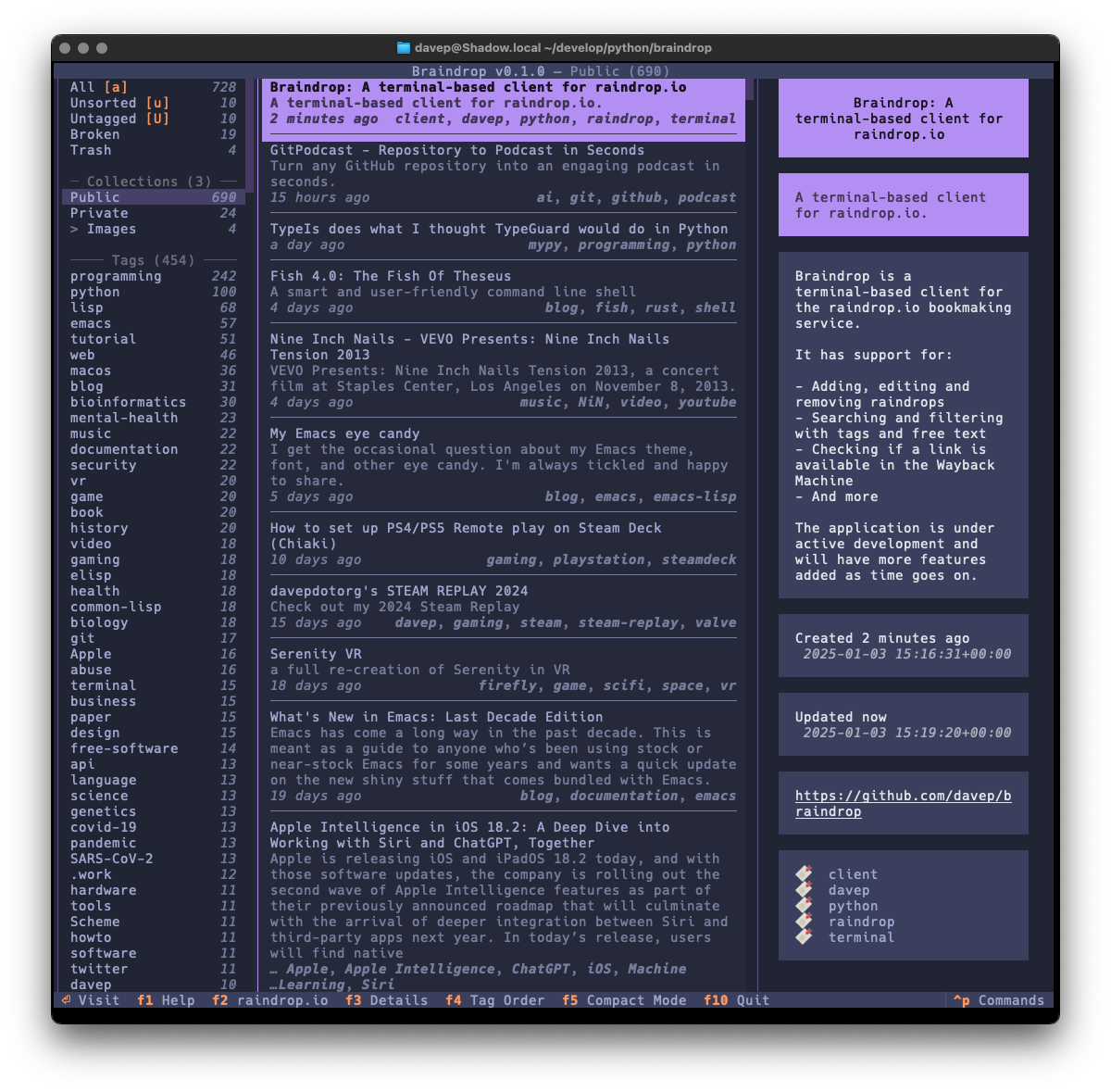
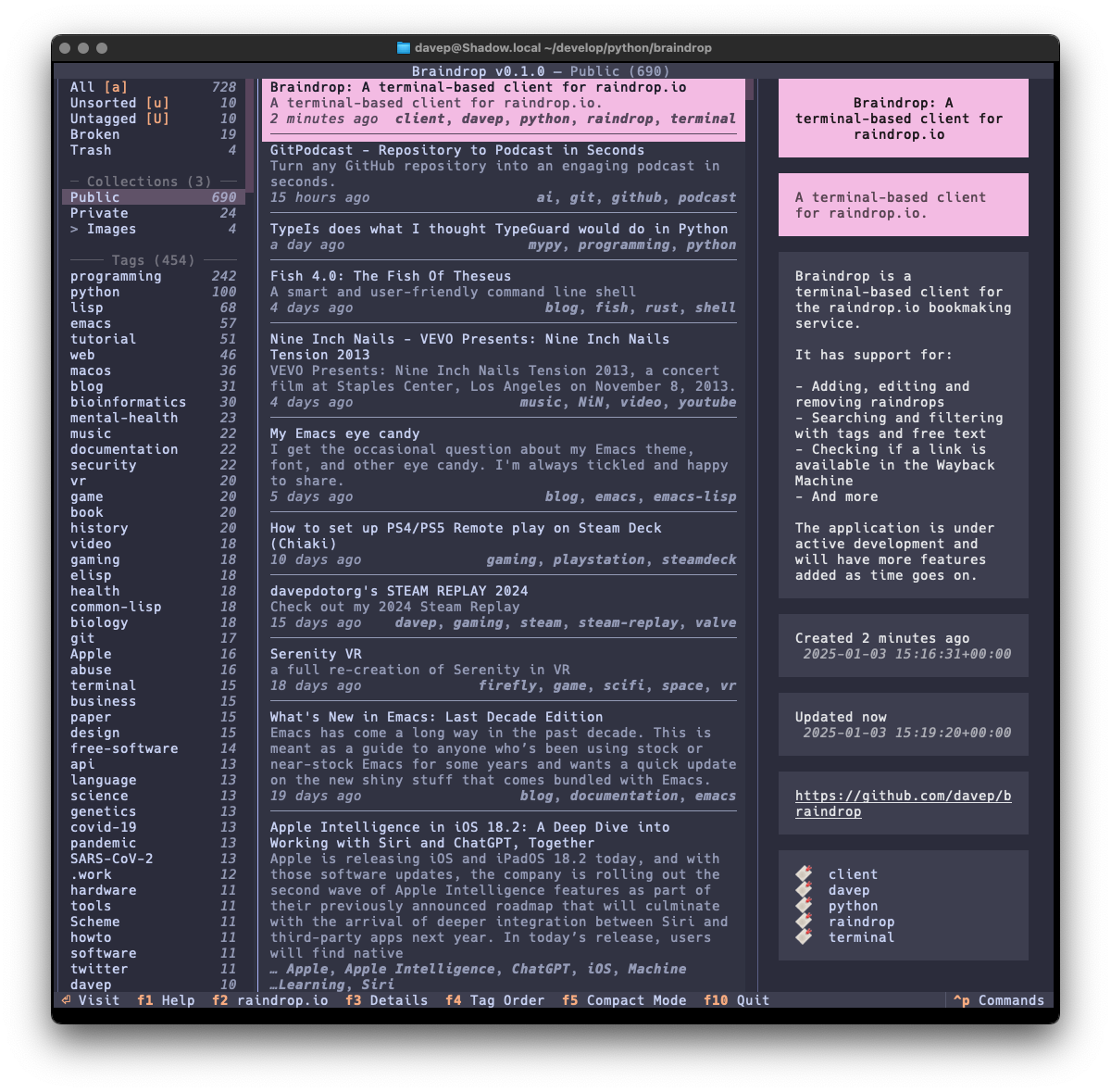
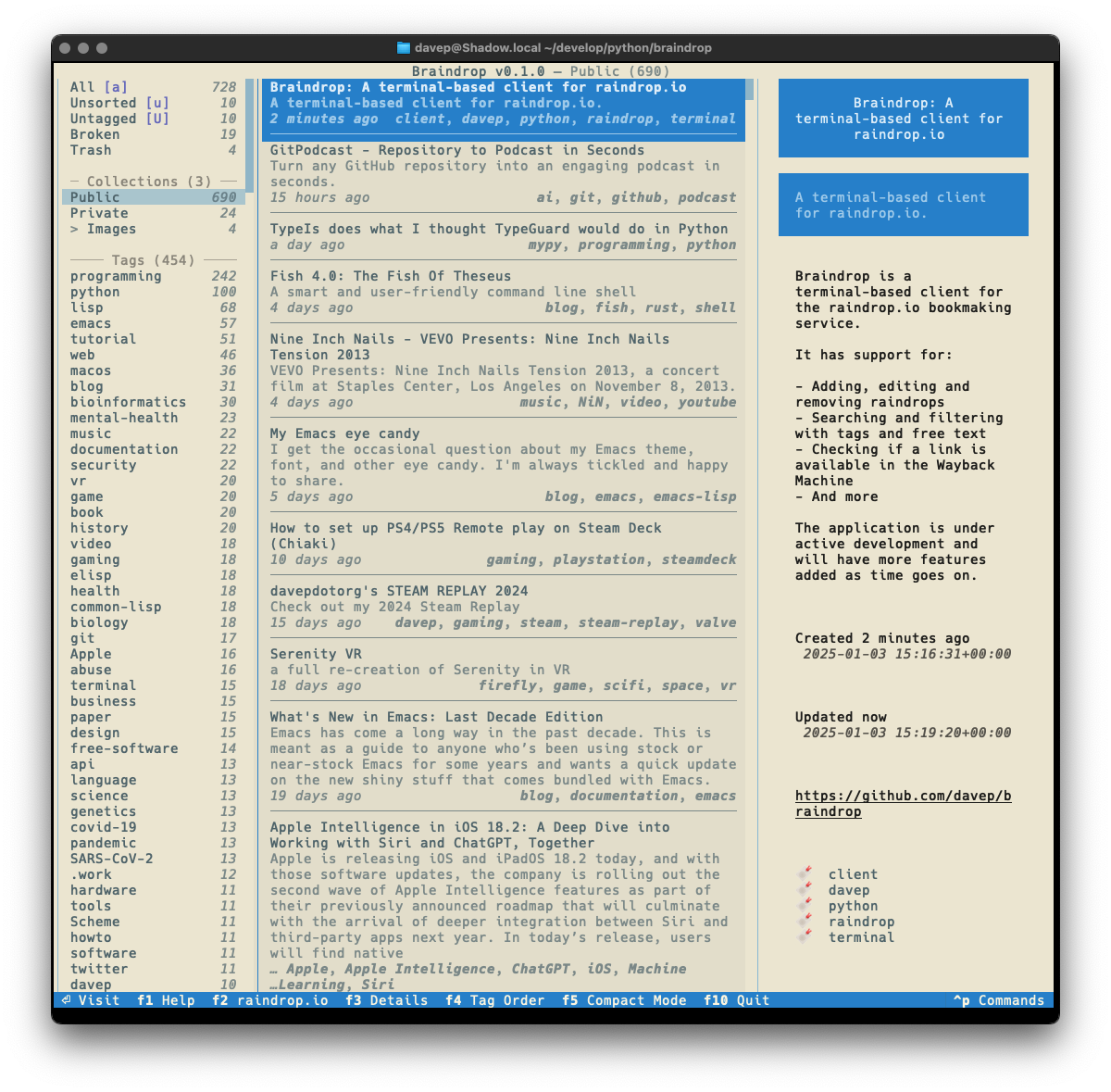
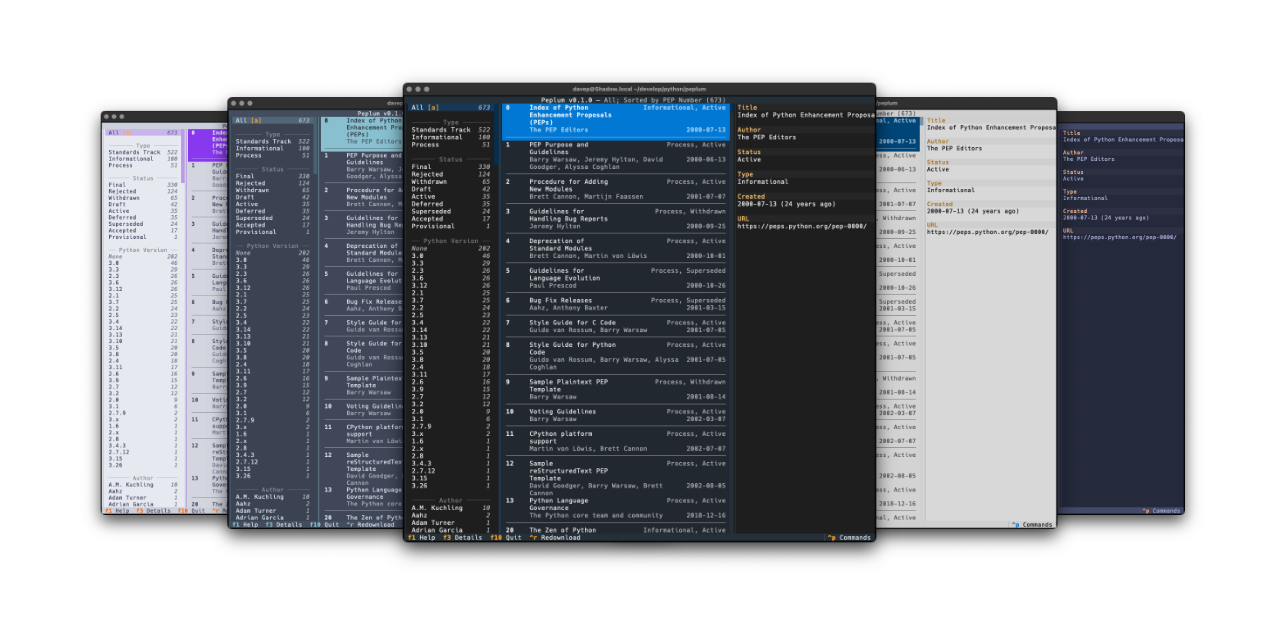
Also as with Braindrop, themes are a thing, and the theme setting is sticky so you can set it the once and stick with that you like. Here's some examples:
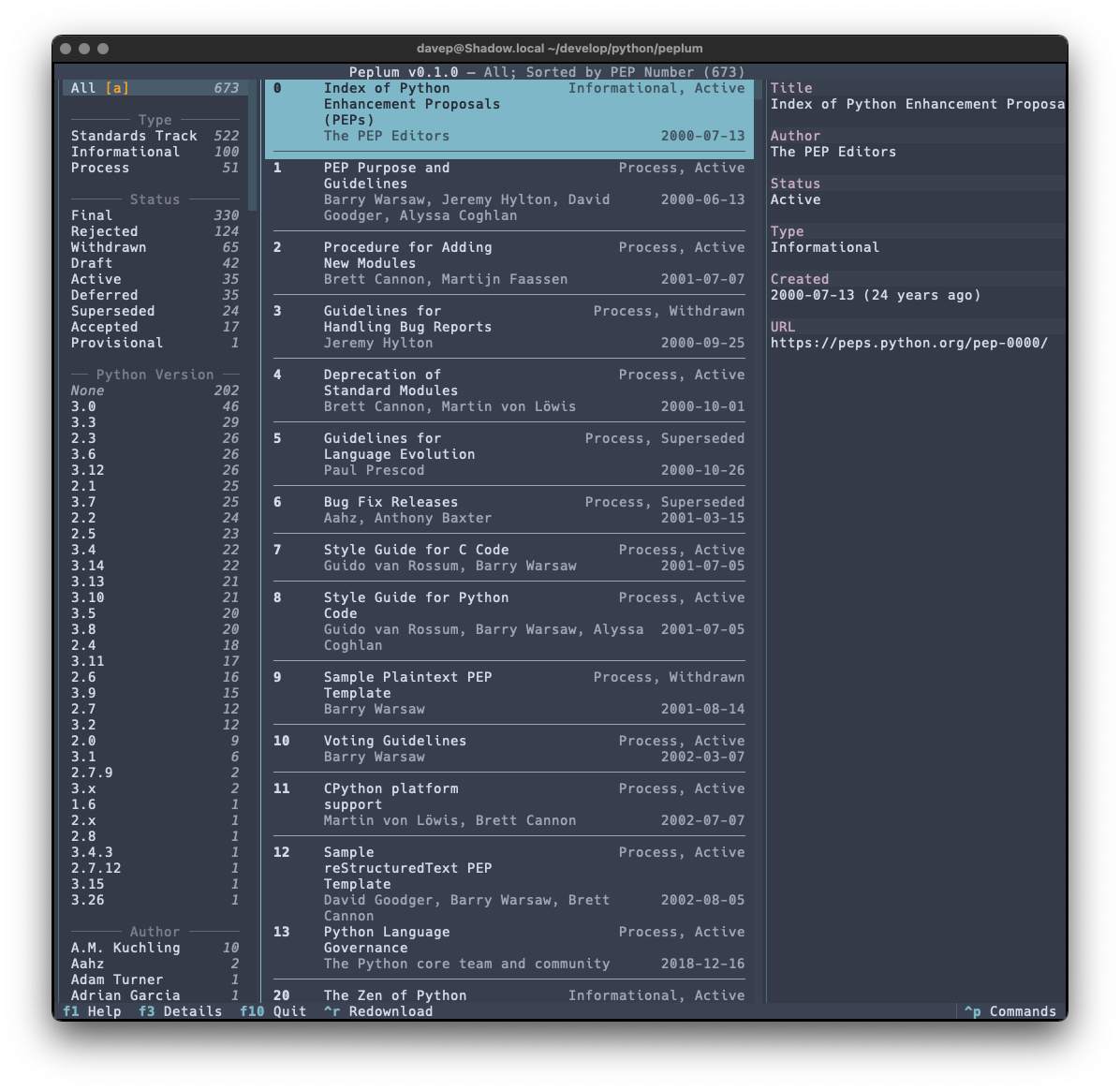
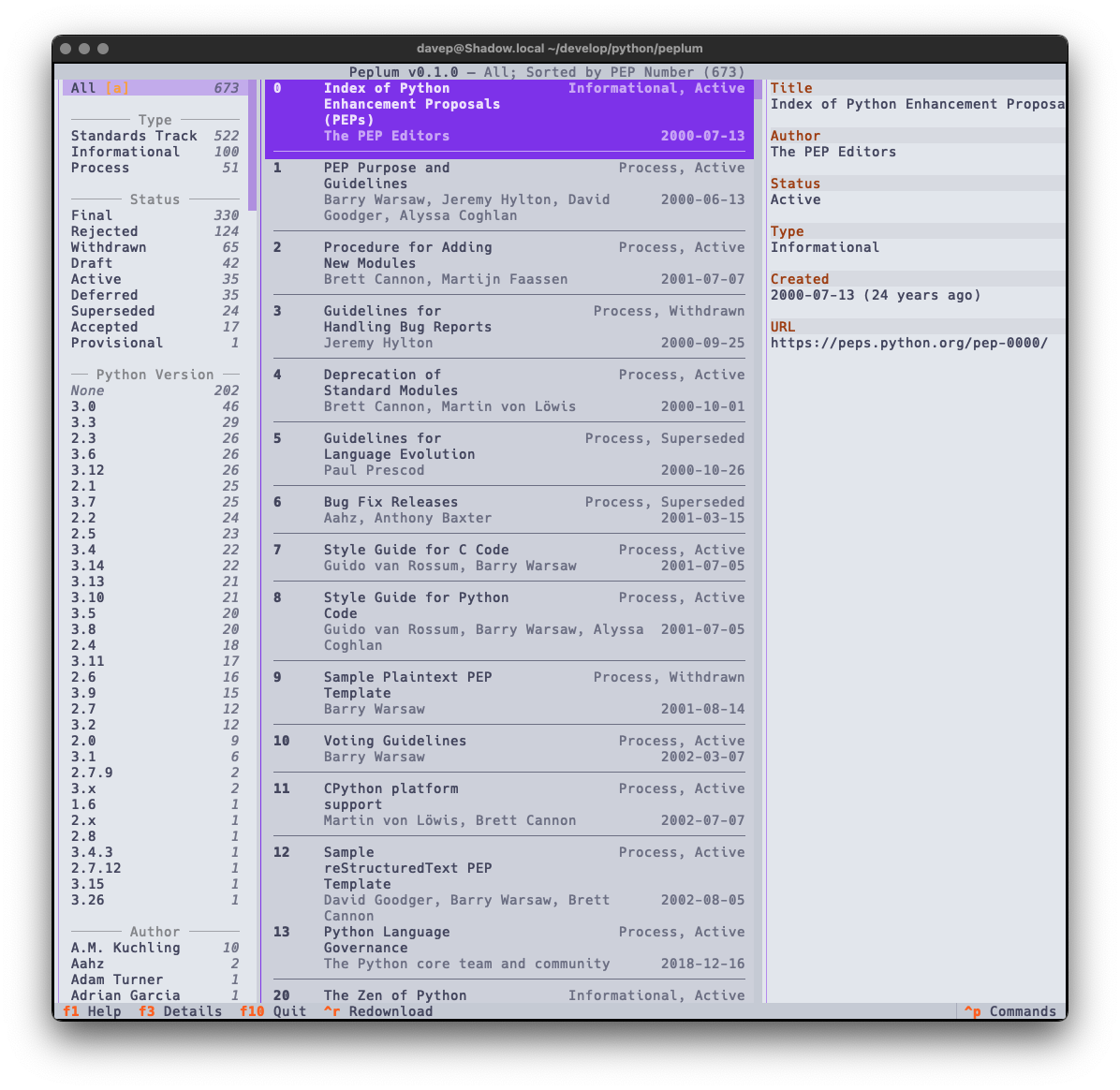
That's a small selection of the themes, with more to explore.
While working on this project I managed to find a couple more bugs in
Textual, including a fun way to get transparent backgrounds to get out of
sync and also a way to
get an easy crash out of OptionList if it's set to width:
auto.
What was even more fun was I sort of discovered a bug in the Python PEP API. Thanks to Hugo noticing my "huh, weird" post on Fosstodon, there's now an issue for it as well as a PR in the works. In retrospect I should have raised an issue myself; instead I fell into that "they obviously know what they're doing so it must be like this for a reason" trap.
Lesson relearned: it's always better to ask and get an answer, than to assume a thing is how it is for a reason you don't know; which I guess is a version of Linus' law really.
So that's v0.1.0 out in the wild. I'm pleased with how it's turned out and
there's more to come. It's licensed GPL-3.0 and available via
GitHub and also via
PyPi. If you have an environment that
has pipx installed you should be able to get up and going with:
$ pipx install peplum
It can also be installed with
Homebrew by tapping davep/homebrew and then installing peplum:
$ brew tap davep/homebrew
$ brew install peplum
I'm going to be making good use of this and working on it more; I hope it's useful to someone else. :-)